WSDM2022 | 考虑行为多样性与对比元学习的推荐系统
title:Contrastive Meta Learning with Behavior Multiplicity for Recommendation
link:https://arxiv.org/pdf/2202.08523.pdf
code:https://github.com/weiwei1206/CML.git
from:WSDM 2022
1. 导读
本文希望通过结合多种类型的行为(访问页面,喜欢,购买等),从而发掘用户和商品之间的复杂关联。但是这类方法通常面临两个问题:
-
目标行为下监督信号稀疏; -
通过依赖关系建模捕获个性化的多行为模式。
本文提出对比元学习CML来解决上述问题,
-
通过对比损失,在多行为对比学习框架下学习不同行为之间的迁移信息,利用辅助行为的信息来帮助目标行为学习,缓解稀疏问题; -
设计对比元网络编码不同用户的特定行为的异质性,从而捕获多样的行为模式。
2. 定义
U表示用户集合,I表示商品集合, 表示第k中行为的用户-商品交互矩阵,多行为交互数据可以表示为 ,如果 则表示用户u和商品i在类型k的行为上存在交互。整个数据中存在目标行为,即需要预测可能会交互的行为,而其他交互属于辅助行为。
整个任务可以描述为,输入:用户集U和商品集I的K种类型的交互数据。输出:预测函数对用户u和商品i可能交互的行为进行预测。
3. 方法
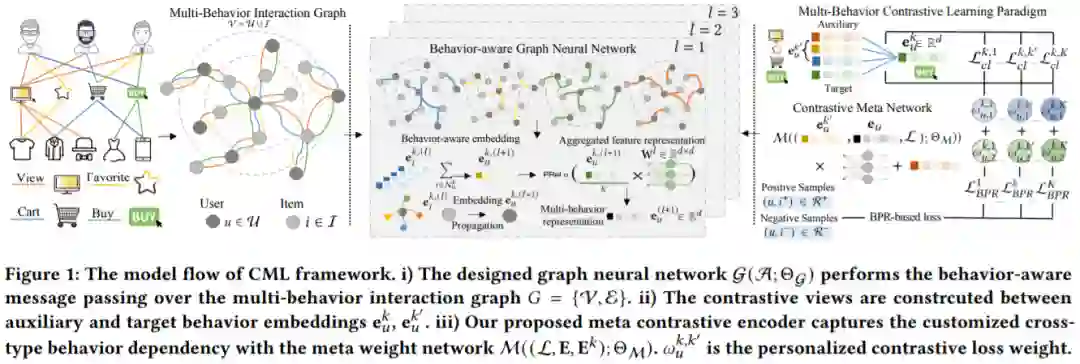
3.1 行为感知的GNN
为了将高阶连接性注入跨用户/项目的多重关系学习,设计了一个行为感知的基于图的消息传播框架。基于LightGCN,本文提出的图结构可以表示为下式,以用户embedding为例进行说明,同一类型的行为下,后一层使用前一层该用户节点的邻居商品节点的embedding求和得到。
在同一层中,将所有类型的行为进行聚合可以得到该层下的用户或商品表征(用户和商品的表征的聚合方式一样),聚合方式如下,
3.2 多行为对比学习
在CML框架中采用一种多行为对比学习范式,通过自监督原则捕捉不同类型用户交互的复杂依赖关系。该对比学习框架利用来自辅助行为的辅助监督信号促进主要的监督任务(即目标行为预测)。
3.2.1 对比视角生成
本文将不同的行为视为不同的视角,在每个视角下用用户行为embedding进行对比学习。通过辅助行为的上下文信息作为监督信号来对数据进行增广,使得不仅能够编码不同行为之间得到依赖关系,还能缓解不同类型的行为数据分布倾斜问题。
3.2.2 逐行为对比学习
在建立了多行为下的对比视角后,进一步设计目标行为和辅助行为之间的逐行为对比学习范式。将同一用户的不同行为视角看做是正样本对,不同用户的行为视角看做是负样本对。给定从GNN得到的用户目标行为表征 ,生成正负样本对为 ,。基于InfoNCE的对比损失来最大化用户表征的互信息,公式如下,其中 表示相似度函数,如内积或余弦相似度,τ是超参数。
上述损失函数是目标行为k和其他辅助行为k'之间进行互信息约束,那么考虑所有辅助行为就可以得到损失函数如下,
3.3 元对比编码
不同的用户有不同的行为模式和商品交互偏好。例如,一些用户可能会从他们最喜欢的商品列表中挑选大部分商品来购买,而另一些用户可能只购买零星的商品,因为他们在列表中添加了很多不太感兴趣的商品。来自不同用户的多种行为模式的多样性导致了不同的商品交互。本文提出了一种元对比编码方案来学习一个显式的权重函数来整合多行为对比损失。从而有效建模不同类型行为之间的个性化依赖关系。元对比编码模式是一个两阶段:
i)用元知识编码器来捕获个性化的多行为特征,从而反映不同的行为感知的用户偏好。
ii)然后,提取的元知识被纳入元权重网络中,为跨类型行为依赖建模生成定制的对比损失权重。
3.3.1 元知识编码器
本文设计了两种编码方式,公式分别如下,其中d()为复制函数,生成与embedding维度对应的向量。||表示拼接,γ为缩放系数。 为辅助行为的embedding, 为聚合后的embedding。
3.3.2 元权重网络
得到元知识后,设计元权重网络得到不同对比损失的权重。公式如下,
结合两个元知识,得到最终的权重为下式,这部分生成的权重用于对比损失和后面的BPR损失进行加权。
3.4 CML的学习过程
3.4.1 优化目标
这里采用BPR损失函数对模型进行优化,第k个类型的行为下的损失函数公式如下,L2正则用于防止过拟合,x为用户表征和商品表征计算得到的在行为k下的偏好分数。
3.4.2 模型训练
基于元学习的策略,本文交替更新GNN 和多行为对比元网络 。其中A为邻接矩阵, 和 分别表示跨类型的用户embedding矩阵和特定类型行为的用户embedding矩阵。训练循环中总共三个阶段:
-
将行为感知图神经网络(带克隆状态)和对比元网络相结合,在整个训练数据中学习多行为对比编码器的初始参数空间; -
基于元数据细化模型参数 -
得到个性化权重后,利用更新好的 改善GNN的参数 。
优化过程如下,其中B是batch size。
4. 结果




