多样性文本生成任务的研究进展
©作者|王晓珂
机构|中国人民大学信息学院
研究方向 | 自然语言处理和对话系统
本文主要介绍了多样性文本生成的最新研究进展。文章也同步发布在AI Box知乎专栏(知乎搜索 AI Box专栏),欢迎大家在知乎专栏的文章下方评论留言,交流探讨!

近年来开放域的闲聊对话研究如雨后春笋般涌现,甚至还做起了跨界,如最近炙手可热的会话推荐系统。而作为人工智能王冠上明珠中的一颗,自然语言处理中随时打算挑战图灵测试的对话系统,当然是不可能止步于机械地一问一答的形式,因此本文基于一对多生成这个角度,探索相关领域的多样性生成,希望能给一对多对话生成注入新的构思。下面主要介绍近来的 5 篇多样性生成的研究成果。
01
Target Conditioning for One-to-Many Generation
这篇论文是 Facebook 收录在 EMNLP2020 的工作,主要是为了解决机器翻译模型中缺乏多样性的问题。本文认为当前的 beam search 方法生成的目标语句仍缺乏多样性,时常出现词语重复和语义重叠的问题。并且之前的模型都是在 1-to-1 的数据集上进行训练,缺少对鼓励多样性的目标函数的设计。
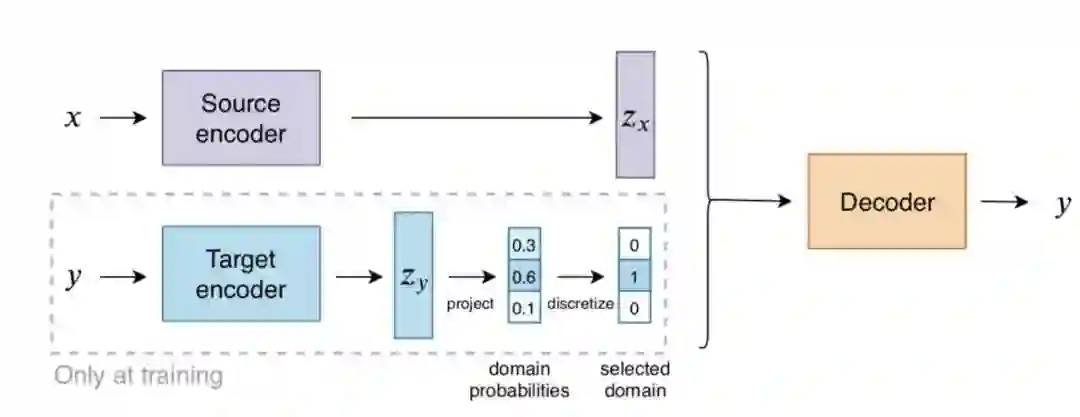
这篇工作借鉴了 discrete autoencoders 的思路,提出将一个 discrete target encoder 引入到翻译模型中,方便将每一个目标语句关联到对应的 variable 或者 domain。其中每一个 domain 对应一个 embedding,这样在测试阶段可以根据每个 domain embedding 来生成多样性的翻译。并且这种离散化的表示方式允许以无监督的方式来改变翻译的 domain 信息。
02
Diversify Question Generation with Continuous Content Selectors and Question Type Modeling
这篇论文是华为诺亚方舟收录在 EMNLP2020 的工作。主要关注的是 QA 工作的逆任务,基于回复和上下文来生成问题,同样这也在一对多生成的范畴内。本文主要思想是通过关注 context 中的不同位置以及表达的不同含义来建模多样性。

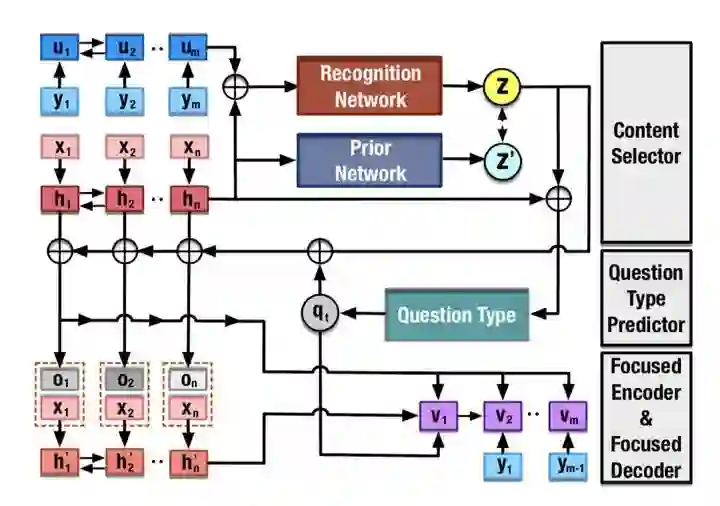
基于 CVAE,通过采用 multimodal 的先验分布来构造更多样的 content selectors,从而能够在 context 定位更多样的关注点。在预测 question type 时,提出 diversity-promoting 算法,主要通过引入 decay 变量来限制相同类型问题分布的出现概率,从而鼓励预测出更丰富的 question type。
03
Focus-Constrained Attention Mechanism for CVAE-based Response Generation
这篇工作是小米 AILab 和香港理工大学的合作论文。文中指出了目前基于 CVAE 的方法仅仅是依赖 discourse-level latent variable 来进行多样性的建模,认为这太过粗粒度。因此提出使用 fine-grained word-level information。
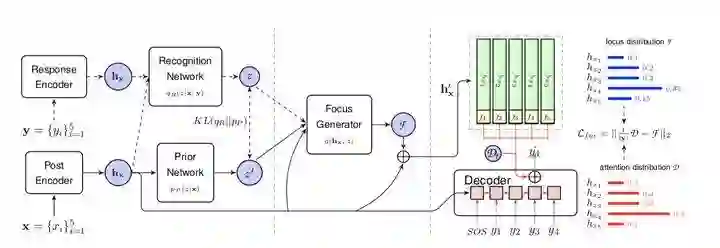
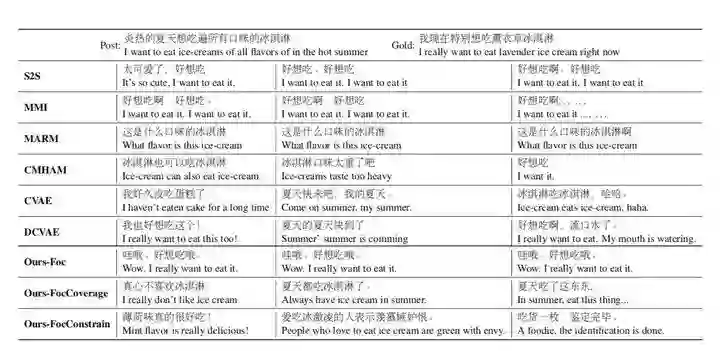
具体来说就是,首先通过引入更加细粒度的 focus 信号,来衡量对话上文和回复的语义集中度。然后提出一个 focus-constrained 的注意力机制,以充分利用 focus 信号并辅助回复的生成。实验结果表明,通过利用细粒度的 focus 信号,文中的模型确实可以产生更多样化以及更可控的回复。
04
Controllable Text Generation with Focused Variation
本文指出了当前可控文本生成的不足,在给定 attributes 的情况下,模型往往不足以生成足够相关的文本,以及很容易生成无意义或者重复的文本。
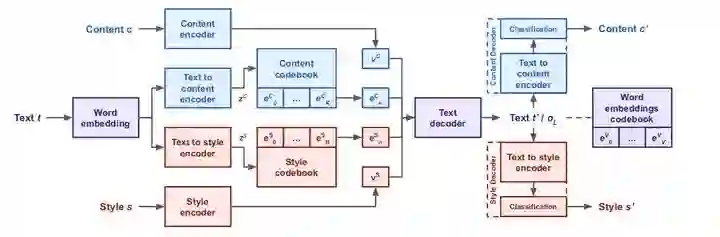
作者从 CVAE 及其变种的角度分析,当前 CVAE 系列在处理这种可控属性的问题上都表现得不是很好。当然这个不足也是当前对话生成中普遍存在的问题。真正实现可控文本的生成,那离可控地进行多样化的文本生成也就不远了。
这篇工作从可控性和多样性两个角度来进行文本生成的工作,设计 context 和 style 两类属性编码器和解码区解构整个语义空间,以此来实现属性的可控性和多样化。
05
COD3S: Diverse Generation with Discrete Semantic Signatures
本文主要针对在 decoding 阶段的采样方法进行改进。经典的 beam search 方法易造成句法、词汇、语义上的重叠和重复。因此本篇工作提出显式地捕捉语义差异的信号,从而实现多样化的采样策略。
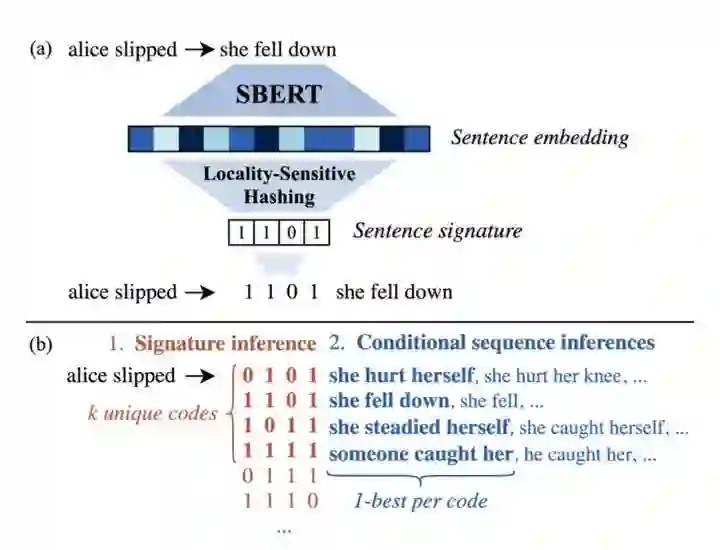
该模型主要是用 sentence-BERT (SBERT) 获得的上下文相关语义表示,通过使用 Locality-Sensitive Hashing (LSH) 来获得句子的离散语义代码。然后采用两阶段的解码策略,获得最相关的代码,作为前缀,使用 prefix-conditioned beam search 方法进行解码。
结束语:一对多对话生成以及多样性文本生成的研究任重而道远。给模型一个输入,然后返回多个引入知识、涵盖类型广但又不存在语义重叠的回复,目前来看还没有真正地实现。希望本文能给读者带来一些启发。如有不同见解,欢迎指正批评、不吝赐教。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DTGA” 就可以获取《多样性文本生成任务的研究进展》专知下载链接





