论文浅尝 - CIKM2020 | 用于推荐系统的多模态知识图谱
论文笔记整理:王琰,东南大学硕士。

来源:CIKM 2020
链接:https://doi.org/10.1145/3340531.3411947
研究背景与任务描述
为了解决推荐系统中的数据稀疏和冷启动问题,研究人员通过利用有价值的外部知识作为辅助信息,提出了基于知识图(KGs)的推荐。但是,以往大多数工作都忽略了多模态知识图谱(MMKG)中的各种数据类型(例如,文本和图像)。因此作者提出了多模态知识图谱注意力网络(MKGAT),以通过利用多模态知识来提高推荐系统的推荐效果。
多模态知识图谱表示学习有两种类型:基于特征的方法和基于实体的方法。
基于特征的方法将模态信息视为实体的辅助特征
基于实体的方法将不同类型的信息(例如文本和图像)视为结构化知识的关系三元组
主要工作:遵循基于实体的方法来构造多模式知识图,提出了多模态知识图谱注意力网络(MKGAT)
任务描述:制定基于多模态KG的推荐任务:
•输入:协同过滤知识图谱,其中包括用户-项目二部图和原始的多模态知识图谱
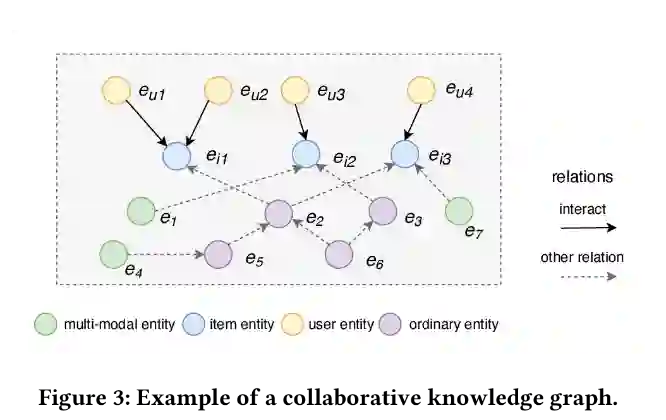
•输出:一种预测用户采用某项商品的概率
MKGAT model
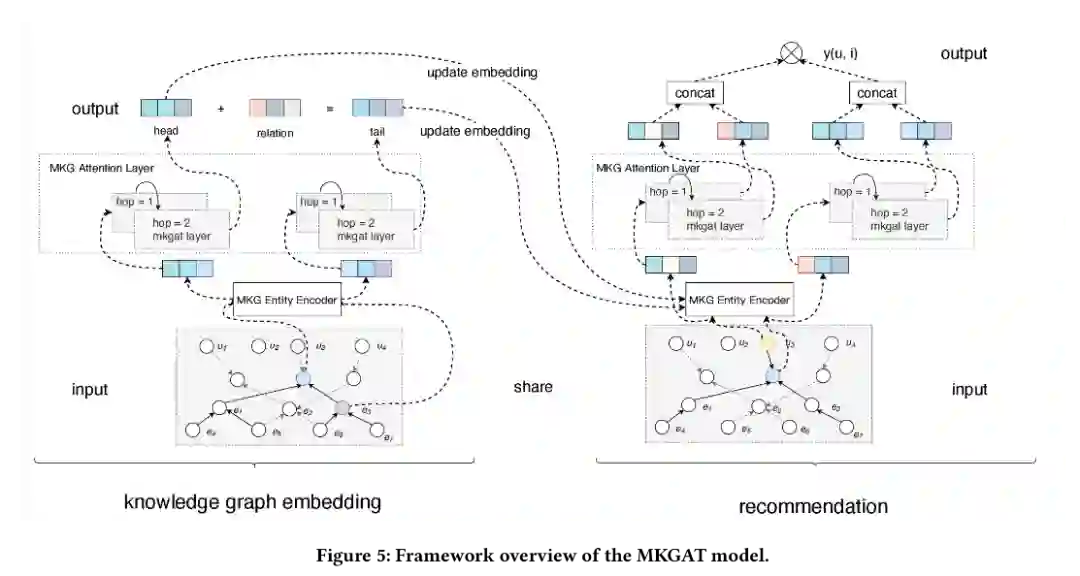
MKGAT model由两个子模块组成: multi-modal knowledge graph embedding module 和 recommendation module.
Multi-modal knowledge graph embedding module:
知识图嵌入模块以协作知识图作为输入,利用多模态知识图谱(MKG)实体编码器和MKG注意层为每个实体学习新的实体表示。新的实体表示将汇总其邻居的信息,同时保留有关其自身的信息。然后,可以使用新的实体表示来学习知识图嵌入,以表示知识推理关系。
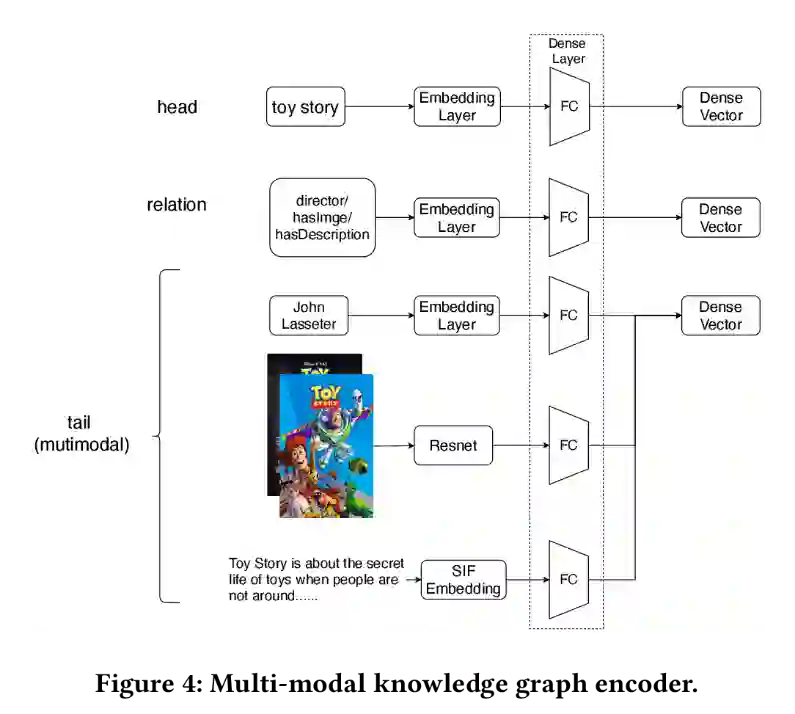
将结构化知识的实体id或关系id分别embedding;用ResNet embedding 图像; 用用Word2Vec训练单词向量,然后应用SIF模型获得句子的单词向量的加权平均值,用作句子向量来表示文字特征
Multi-modal Knowledge Graph Attention Layer
给定候选实体 h ,首先通过transE模型学习知识图的结构化表示,然后把实体 ℎ 的多模态邻居实体信息汇总到实体 h 。N_h 表示直接连接到 h 的三元组的集合,
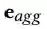 集合了邻居实体信息,是每个三重表示形式的线性组合,计算公式为
集合了邻居实体信息,是每个三重表示形式的线性组合,计算公式为
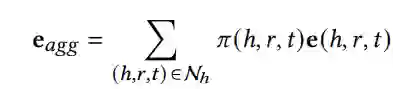
e(h, r, t) 是通过对头部实体,尾部实体和关系的嵌入的串联进行线性变换得到的
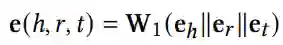
通过关系注意力机制实现π(h, r, t)
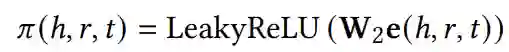
在这里,选择LeakyReLU作为非线性激活函数。此后采用softmax函数对所有与将与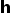
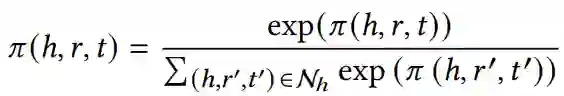
Aggregation layer
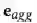 聚合为实体 h
的新表示
聚合为实体 h
的新表示
1) Add aggregation method
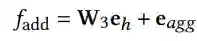
对初始e^h进行线性变换并将其添加到
2) Concatenation aggregation method
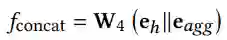
使用线性变换连接 e^h 和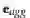
Knowledge Graph Embedding
使用translational scoring function来embedding
通过优化转换原理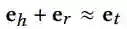
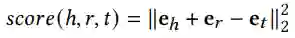
Pairwise Ranking Loss:
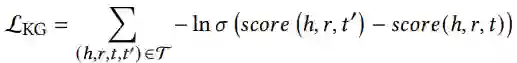
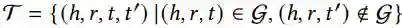
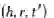
Recommendation module:
推荐模块以实体的知识图嵌入(由知识图嵌入模块获得)和协作知识图为输入,推荐模块还使用MKG实体编码器和MKG attention layer来利用相应的邻居来丰富用户和用户的表示。最后,根据传统推荐模型来生成用户和项目之间的匹配分数
为了保留第
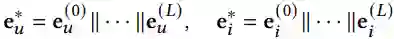
其中||是连接操作,L是MKG attention layer的数目。这样不仅可以通过执行嵌入传播操作来丰富初始嵌入,还可以通过调整L来控制传播强度
匹配分数的计算公式为:
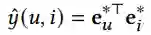
推荐预测损失为Bayesian Personalized Ranking (BPR) loss:

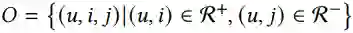
Experiment
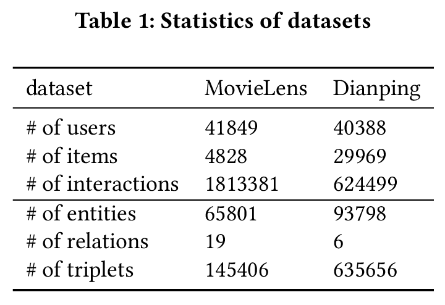
数据集:MovieLens,Dianping
Evaluation Metrics:recall@k和ndcg@k
Baselines:基于FM的方法(NFM),基于KG的方法(CKE,KGAT),多模态方法(MMGCN)
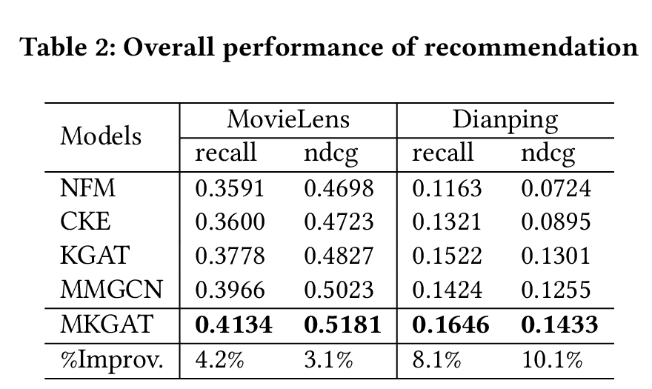
可以看出MKGCN在recall和ndcg方面均优于两个数据集的所有baselines
模态的影响:

在Dianping数据集上比较了KGAT和MKGAT模型在不同模态下的结果,可以看出在KGAT和MKGAT中,具有多模式特征的方法均优于具有单模式特征的方法且视觉效果比文本效果更加重要
模型深度的影响:
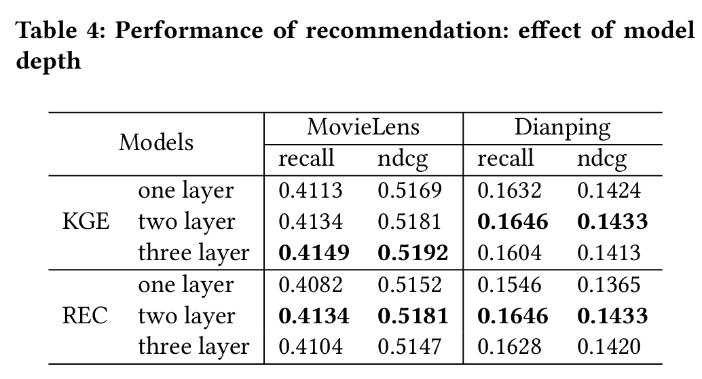
对于KGE,在MovieLens中,随着MKGAT层数的增加,评估指标也增加,证明了邻域信息融合在知识图嵌入中的有效性。在Dianping数据集中,随着MKGAT层数的增加,评估指标先增大然后减小,这可能是因为点屏数据的多跳信息相对稀疏
推荐部分随着MKGAT层数的增加,评估指标首先集中增长,证明了不同跃点的KGE对于推荐系统有益。但是当层数增加到一定水平时,评估指标下降,这可能是由于数据稀疏导致了过度拟合
组合层的影响:

可以看出使用的连接层(用CONCAT标记)的方法优于添加层(用ADD标记)
Case study:
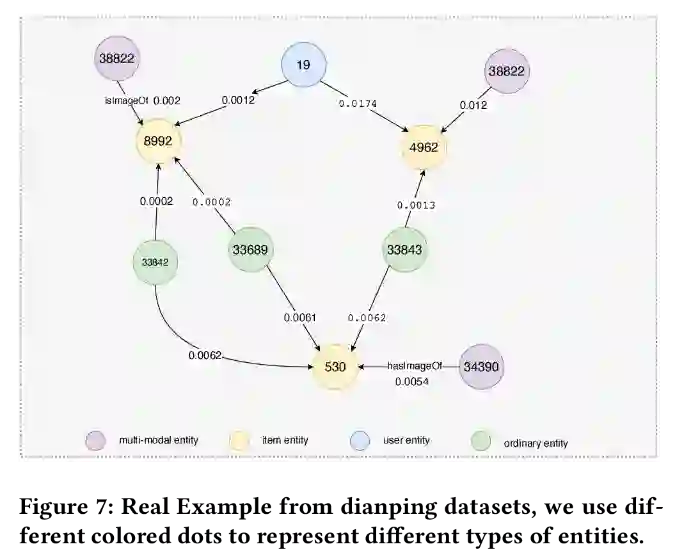
随机选择Dianping数据集中的一个用户和相关项,计算候选项目与实体之间的相关性得分,相关性得分越高,模型就认为当前实体对模型的影响越大。可以看出多模态关系在协作知识图中通常有较高评分,表明多模态实体的重要性
总结:
作者提出了一种多模式知识图注意力网络(MKGAT),将多模态知识图谱创新地引入了推荐系统。通过学习实体之间的推理关系,并将每个实体的邻居实体信息聚合到自身,该模型可以利用多模式实体信息改进推荐效果
未来可以在多模态知识图的框架下探索更多的多模态融合方法,例如 Tensor Fusion Network(TFN)或低秩多模态融合(LMF)等
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 网站。




