机器之心 & ArXiv Weekly Radiostation
本周论文包括中国天眼 FAST 再立功,精确测量星际磁场强度,研究登 Nature 封面;浙大提出无数据知识蒸馏方法 FastDFKD,生成速度加速 100 倍,性能媲美 SOTA 等。
目录:
A Neural Network Solves and Generates Mathematics Problems by Program Synthesis: Calculus, Differential Equations, Linear Algebra, and More
An early transition to magnetic supercriticality in star formation
Up to 100× Faster Data-free Knowledge Distillation
Are Large-scale Datasets Necessary for Self-Supervised Pre-training?
Masked Feature Prediction for Self-Supervised Visual Pre-Training
Activation Modulation and Recalibration Scheme for Weakly Supervised Semantic Segmentation
A Survey of Generalisation in Deep Reinforcement Learning
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:A Neural Network Solves and Generates Mathematics Problems by Program Synthesis: Calculus, Differential Equations, Linear Algebra, and More
摘要:
前段时间,DeepMind 的一项研究登上《Nature》封面,通过引导直觉解决了两大数学难题;之后,OpenAI 教 GPT-3 学会了上网,能够使用基于文本的 Web 浏览器。
就在 2021 年的最后一天, MIT 与哥伦比亚大学、哈佛大学、滑铁卢大学的联合研究团队发表了一篇长达 114 页的论文,提出了首个可以大规模自动解决、评分和生成大学水平数学问题的模型,可以说是人工智能和高等教育的一个重要里程碑。其实在这项研究之前,人们普遍认为神经网络无法解决高等数学问题。
![]()
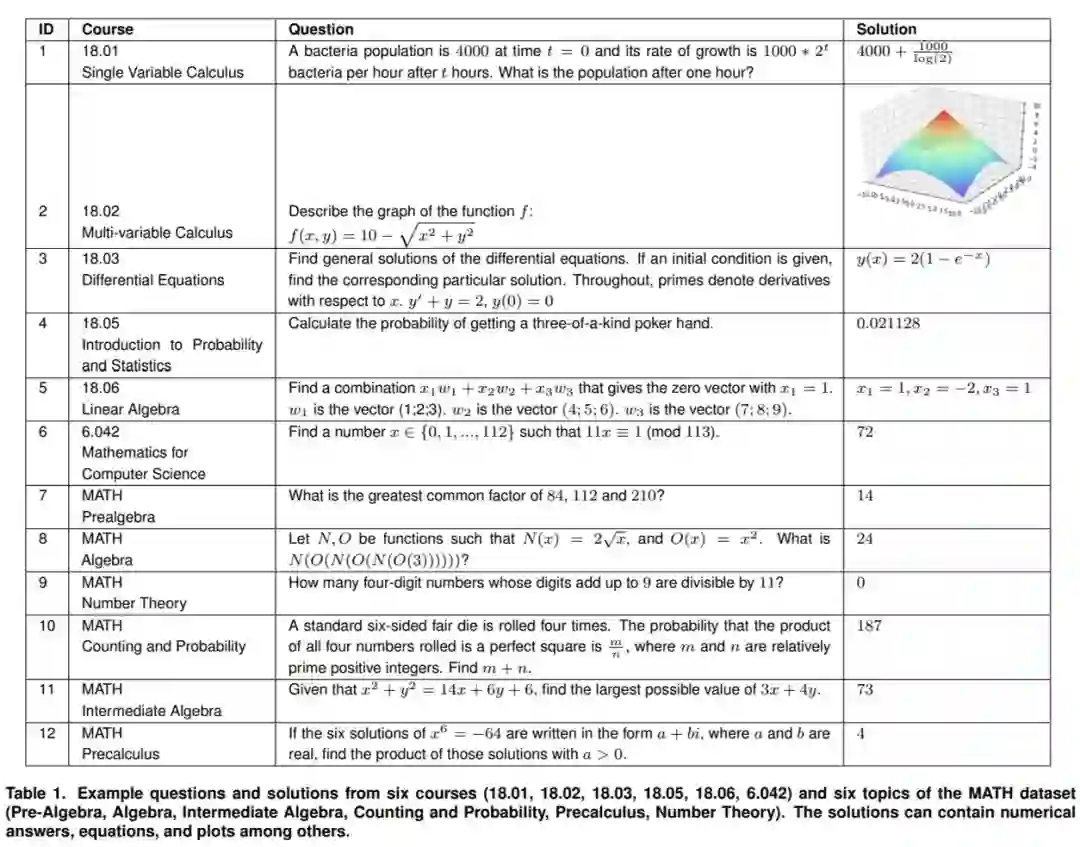
对于 MATH 数据集,该研究从每个主题中随机抽取 5 个问题。
![]()
使用 Codex 将课程问题转换为编程任务并运行程序以解决数学问题。
推荐:
AI 生成高数题,难出新高度:MIT 提出首个可出题、做题、评分的算法模型。
论文 2:An early transition to magnetic supercriticality in star formation
摘要:
1 月 6 日,「中国天眼」在中性氢谱线测量星际磁场取得了重大进展,登上《Nature》封面。这是科学家依托「中国天眼」再次取得的一批重要科研成果。该研究采用原创的中性氢窄线自吸收方法,并首次利用这种方法实现了塞曼效应的探测,获得了强度为 3.8±0.3 微高斯的高置信度星际磁场测量,为解决恒星形成三大经典问题之一的「磁通量问题」提供了重要的观测证据。该研究由中国科学院国家天文台研究员李菂等领导的国际合作团队完成。
研究者开发了一种叫做 HI 窄自吸收(HI narrow self-absorption, HINSA)的技术,以提供从 HI 到 H_2 转变的探针。HINSA 追踪与 H_2 混合良好的冷原子氢,并通过碰撞提供必要的 H1 冷却(CNM 中无法提供)。
如下图 1 所示,研究者使用中国天眼 FAST,在距离 L1544 中心 3.6' (0.15 pc)、靠近 HINSA 柱密度峰值的 2.9′(0.12 pc) 光束中检测到了塞曼分裂,获得了 L1544 的精确磁场强度。
![]()
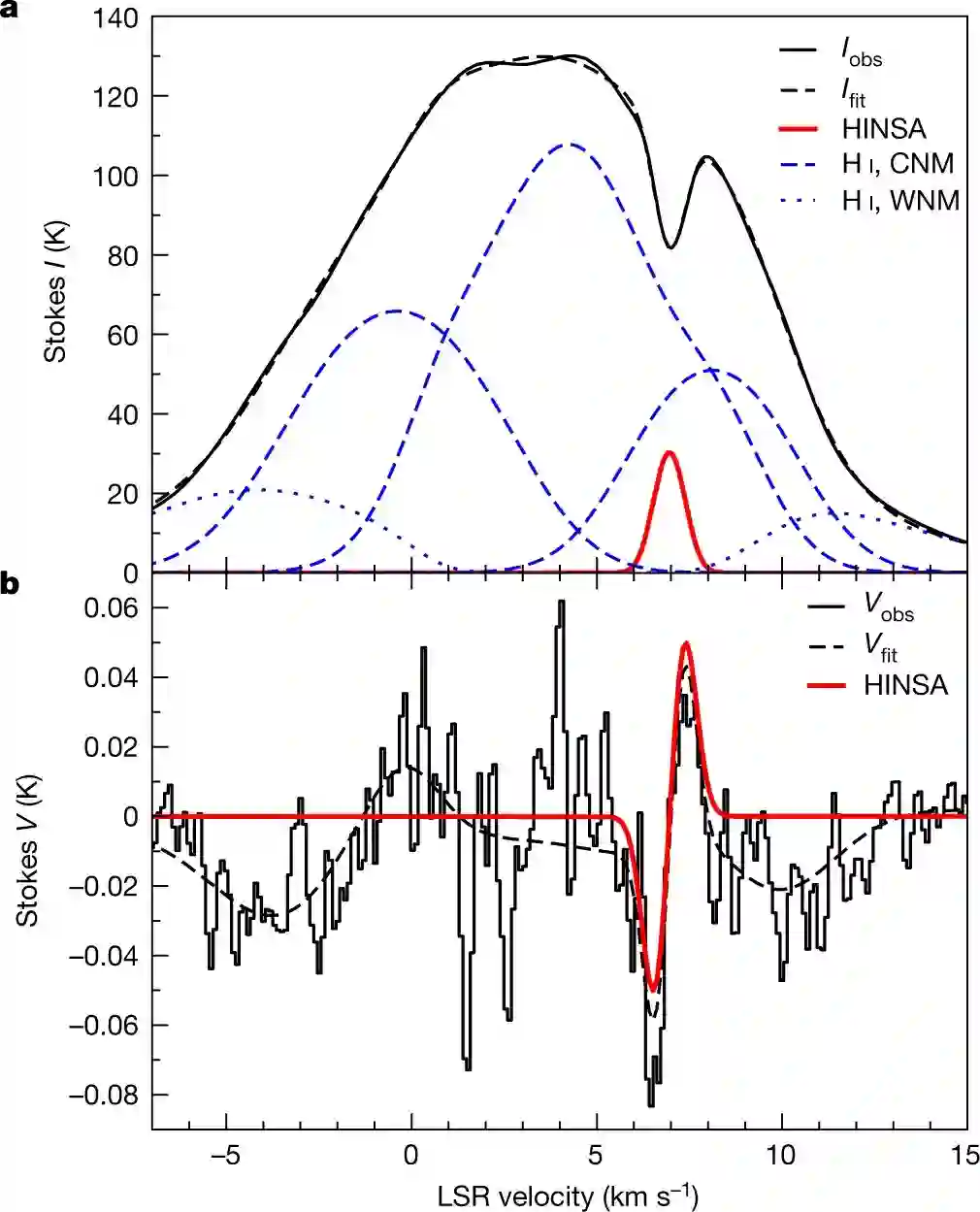
下图 2 展示了 Stokes I(v) 和 V(v) 参数的频谱,v 表示速度。图 2a 将 I(v) 分解为前景 HINSA 分量(component)、背景 WNM 分量以及 HINSA 和 WNM 之间的 3 个 CNM 分量。图 2b 为 HINSA 的塞曼分裂和 5 个分量的总体塞曼分布。
![]()
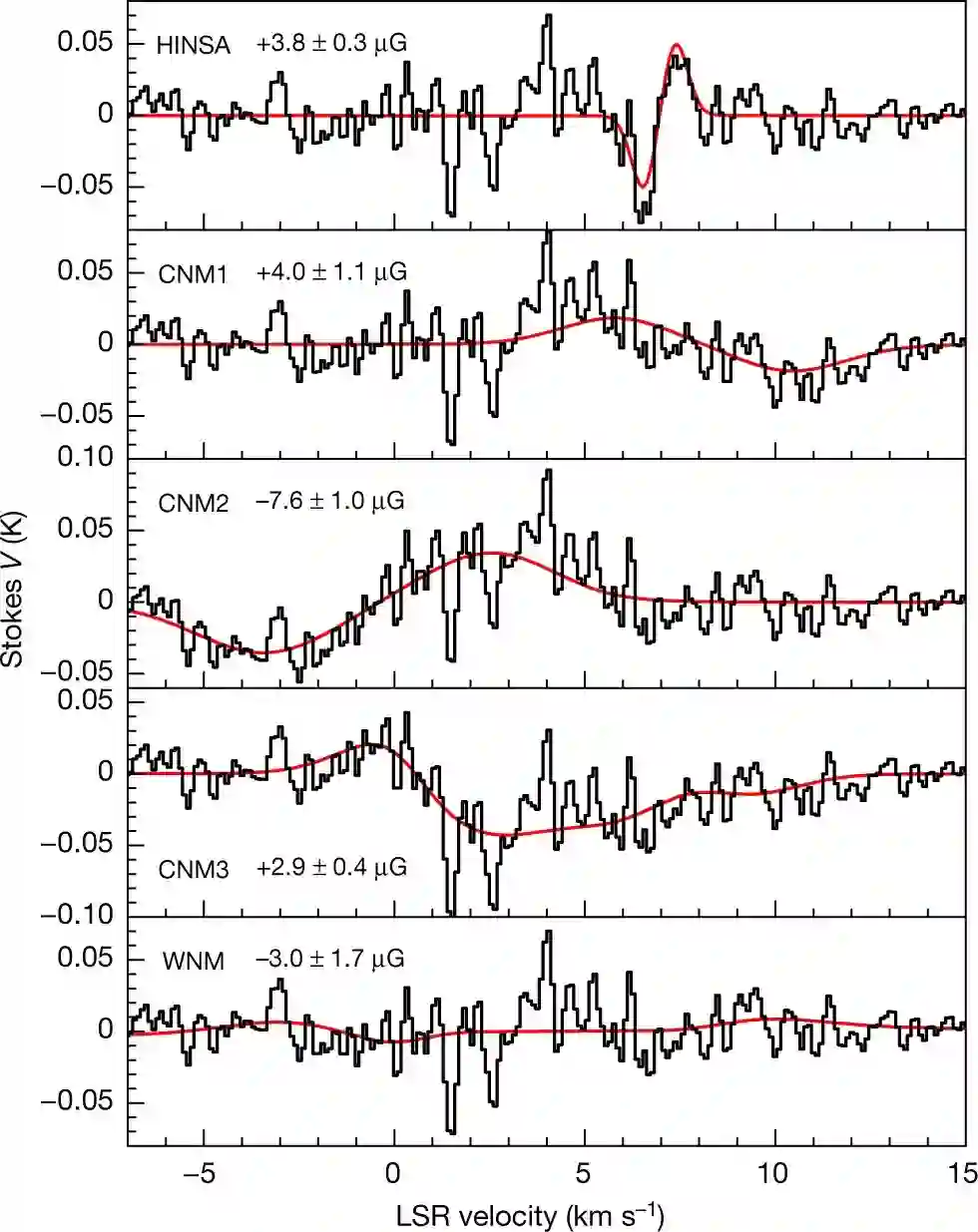
下图 3 展示了 HINSA、CNM1、CNM2、CNM3 和 WNM 等 5 个分量的塞曼分裂和 B_los。
![]()
推荐:
中国天眼 FAST 再立功,精确测量星际磁场强度,研究登 Nature 封面。
论文 3:Up to 100× Faster Data-free Knowledge Distillation
摘要:
知识蒸馏(KD)最近成为一种流行的范式,它是一种很典型的模型压缩方法,可以复用如今在线流行的预训练模型。随着自然语言处理模型等进入了预训练模型的时代,模型的规模也在极速增长,例如 GPT-3 参数量达到 1750 亿。如何在资源有限的情况下部署使用这些庞大的模型是一个很大的挑战。
知识蒸馏在解决这一问题中占据了重要的地位。我们可以用它来有效地从大型教师模型学习小型学生模型,并且学生模型的性能也很不错。
KD 的传统设置需要拥有原始训练数据作为输入以训练学生模型。不幸的是,由于隐私或版权原因,在很多情况下,原始数据无法发布,用户只能使用预先训练好的模型,反过来,这对 KD 应用于更广泛的领域构成了主要障碍。
为了解决这个问题,有研究者(Lopes, Fenu,Starner 2017)提出了无数据知识蒸馏 (DFKD,Data-free knowledge distillation) 方法,这种方法假设根本无法获得训练数据。由于 DFKD 对训练数据的约束非常宽松,其在自然语言处理、计算机视觉等领域受到越来越多的关注。
DFKD 虽然取得了一些比较好的结果,但 SOTA 性能的 DFKD 方法仍然存在数据合成效率较低的问题,这使得无数据训练过程非常耗时,因此不适用于大规模训练任务。
在这项研究中,来自浙江大学、新加坡国立大学等机构的研究者引入了一种有效的解决方案 FastDFKD,其能够将 DFKD 加速一个数量级。FastDFKD 的核心是:复用训练数据中共享的公共特征,从而合成不同的数据实例。不同于之前单独优化一组数据,该研究建议学习一个元合成器(meta-synthesizer),可以寻求共同特征作为快速数据合成的初始化。因此,FastDFKD 只需几步即可实现数据合成,显着提高了无数据训练的效率。在 CIFAR、NYUv2 和 ImageNet 上的实验表明,所提出的 FastDFKD 实现了 10 倍甚至 100 倍的加速,同时保持了与当前 SOTA 相当的性能。
![]()
推荐:
加速 100 倍,性能媲美 SOTA,浙大提出快速高效的无数据知识蒸馏方法 FastDFKD。
论文 4:Are Large-scale Datasets Necessary for Self-Supervised Pre-training?
摘要:
当今应对数据匮乏问题的主流学习范式是,即先在大型数据集(如 Imagenet )上对模型进行预训练,之后基于特定的任务以较少的数据集微调模型。这一训练过程通常优于从头开始训练(例如,从头随机初始化参数)。这种学习范式在许多任务中取得了 SOTA 性能,例如检测、分割、动作识别等。尽管这种方法取得了成功,但我们很难将这种大规模标签数据集提供的好处与预训练范式的局限性区分开来。除此以外,在一个数据集上预训练模型并在另一个数据集上对其进行微调会引入差异。
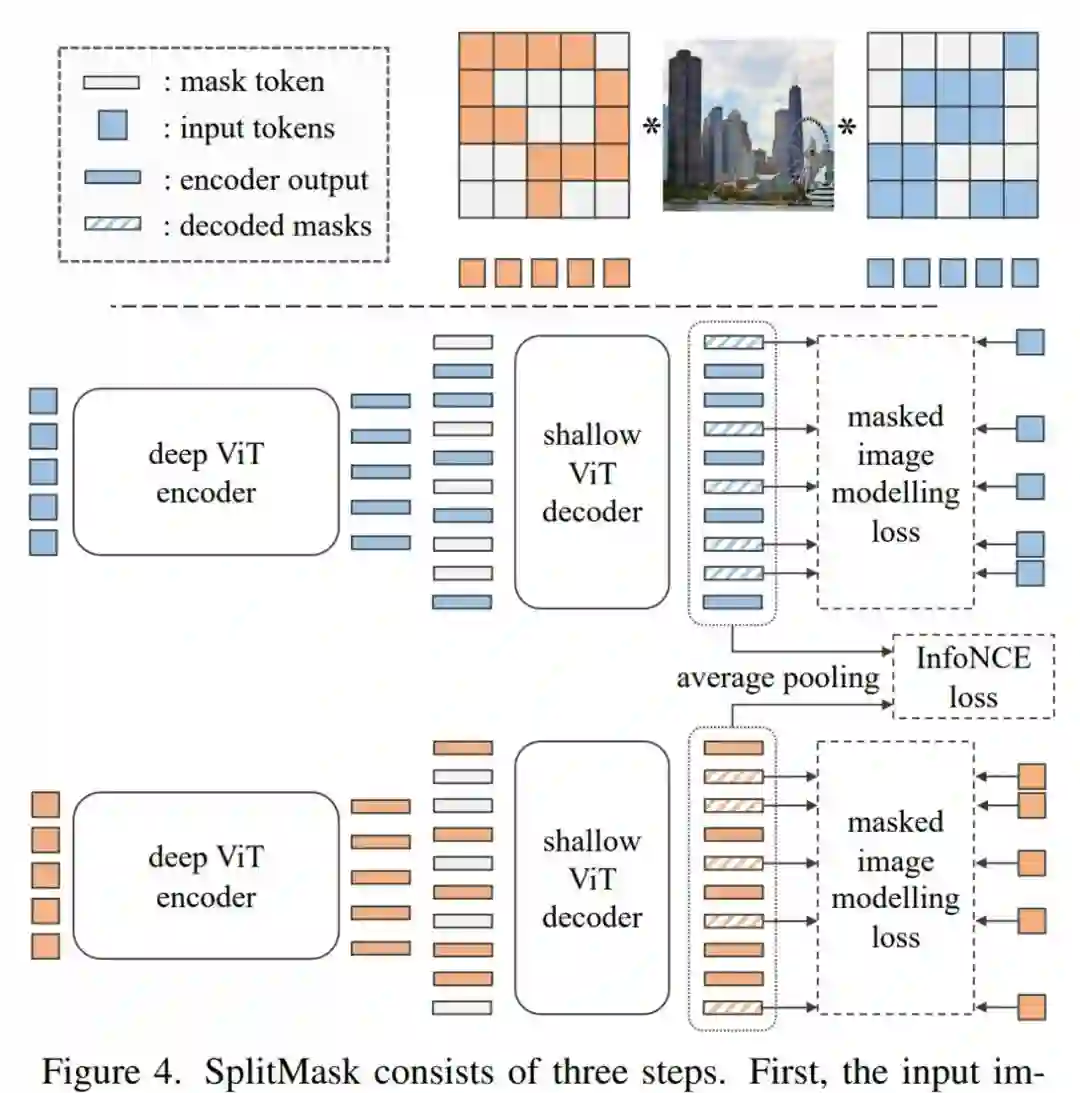
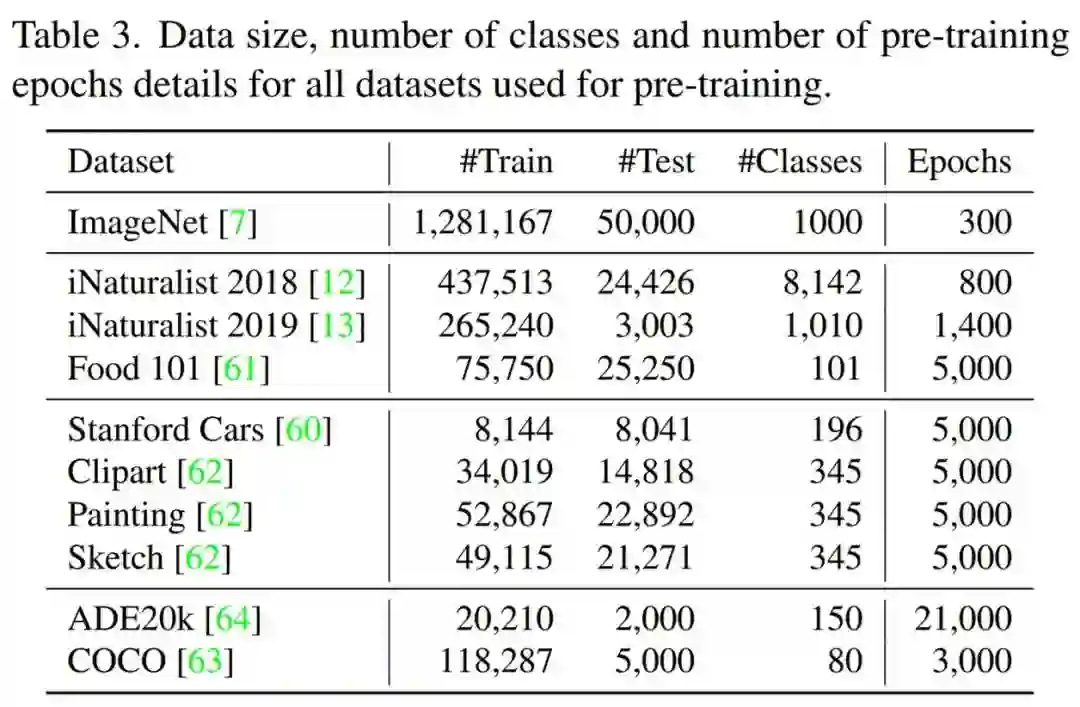
来自 Meta AI 等机构的研究者,考虑了一个仅利用目标任务数据的自监督预训练场景。所用数据集包括如 Stanford Cars、Sketch 或 COCO,它们的数量级小于 Imagenet。该研究表明,本文介绍的去噪自编码器(如 BEiT 或其变体),对预训练数据的类型和大小更具有鲁棒性。与来自 ImageNet 预训练相比,该研究获得了具有竞争力的性能。在 COCO 上,当仅使用 COCO 图像进行预训练时,在检测和实例分割任务上,性能超过了监督 ImageNet 预训练。
![]()
![]()
实验研究了计算机视觉模型在各种数据集上的预训练和微调。
推荐:
超越 ImageNet 预训练,Meta AI 提出 SplitMask,小数据集也能自监督预训练。
论文 5:Masked Feature Prediction for Self-Supervised Visual Pre-Training
摘要:
来自 Facebook AI 研究院(FAIR)的研究团队又提出了一种自监督视觉预训练新方法 MaskFeat。
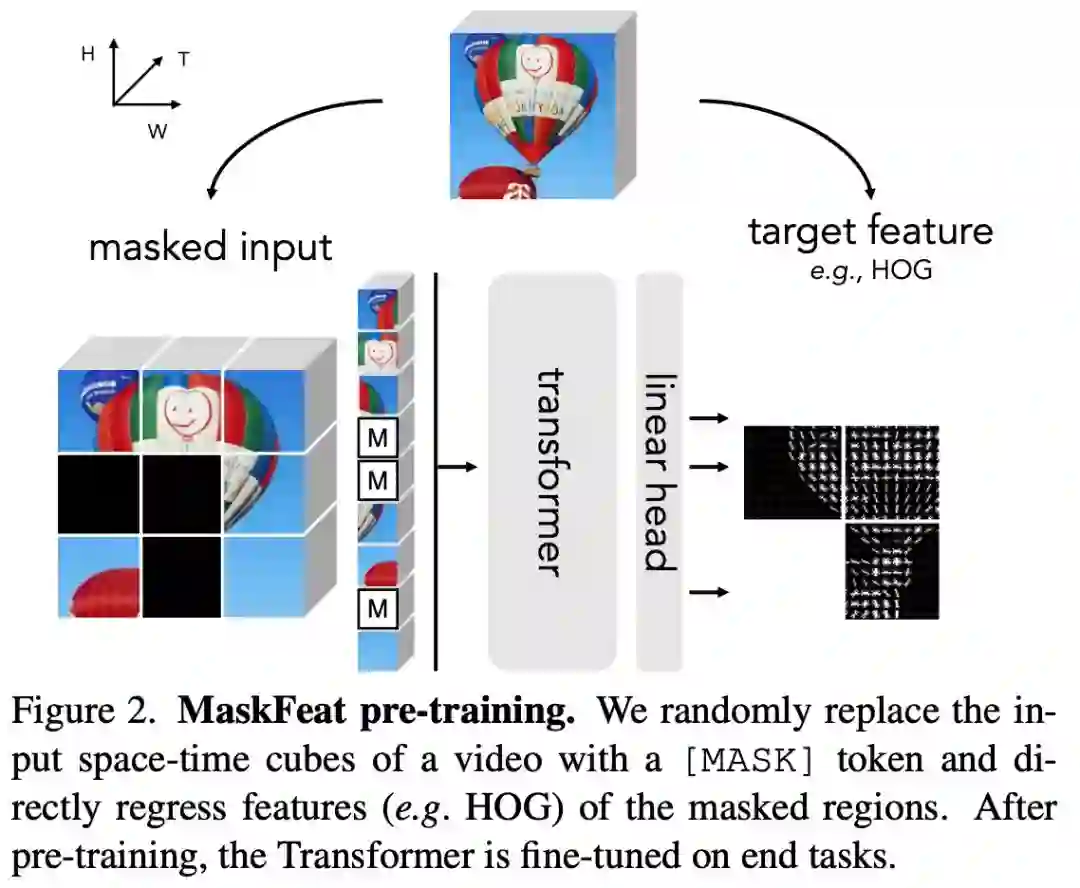
MaskFeat 首先随机掩码一部分输入序列,然后预测被掩码区域的特征。通过研究 5 种不同类型的特征,研究者发现方向梯度直方图 (HOG) 是一种很好的特征描述方法,在性能和效率方面都表现优异。并且研究者还观察到 HOG 中的局部对比归一化对于获得良好结果至关重要,这与之前使用 HOG 进行视觉识别的工作一致。该方法可以学习丰富的视觉知识并驱动基于 Transformer 的大规模模型。在不使用额外的模型权重和监督的情况下,MaskFeat 在未标记的视频上进行预训练,使用 MViT-L 在 Kinetics-400 上实现了前所未有的 86.7% top-1 准确率。此外,MaskFeat 还能进一步推广到图像输入,并在 ImageNet 上获得了有竞争力的结果。
掩码视觉预测任务旨在修复被掩码的视觉内容。通过建模掩码样本,该模型从识别物体的部位和运动的意义上实现了视频理解。例如,要补全下图中的图像,模型必须首先根据可见区域识别对象,还要知道对象通常的形态和移动方式,以修复缺失区域。
![]()
MaskFeat 提出将预测被掩码区域的特征。借助从原始完整样本中提取的特征进行监督。目标特征的选择在很大程度上影响了预训练模型的属性,该研究对特征进行了广泛的解释,并主要考虑了 5 种不同类型的目标特征。
![]()
推荐:
比 MAE 更强,FAIR 新方法 MaskFeat 用 HOG 刷新多个 SOTA。
论文 6:Activation Modulation and Recalibration Scheme for Weakly Supervised Semantic Segmentation
摘要:
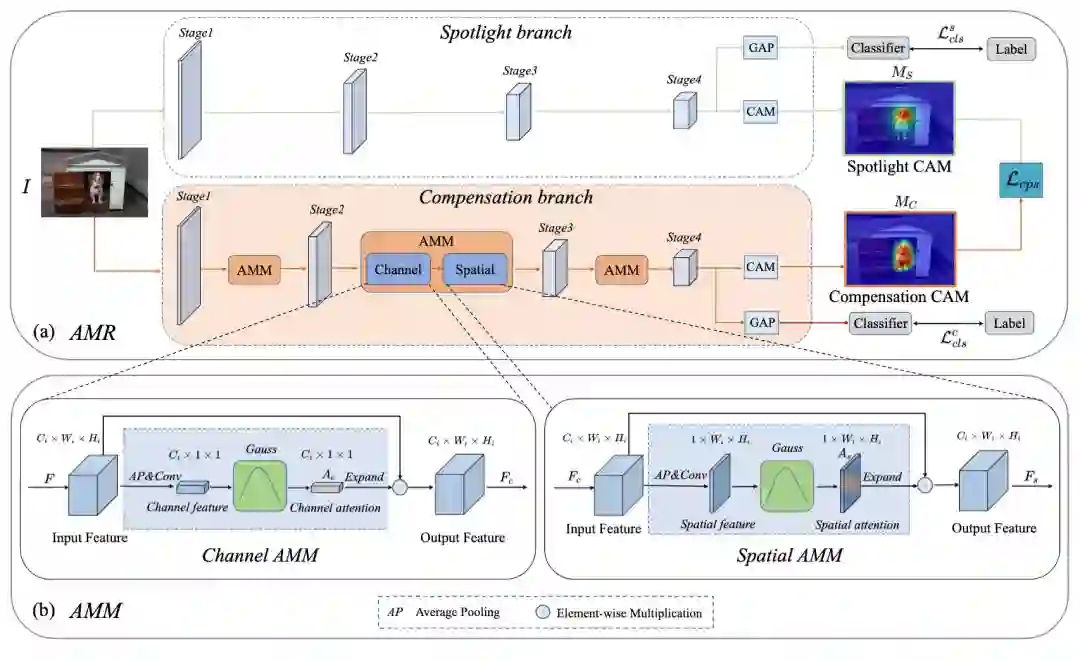
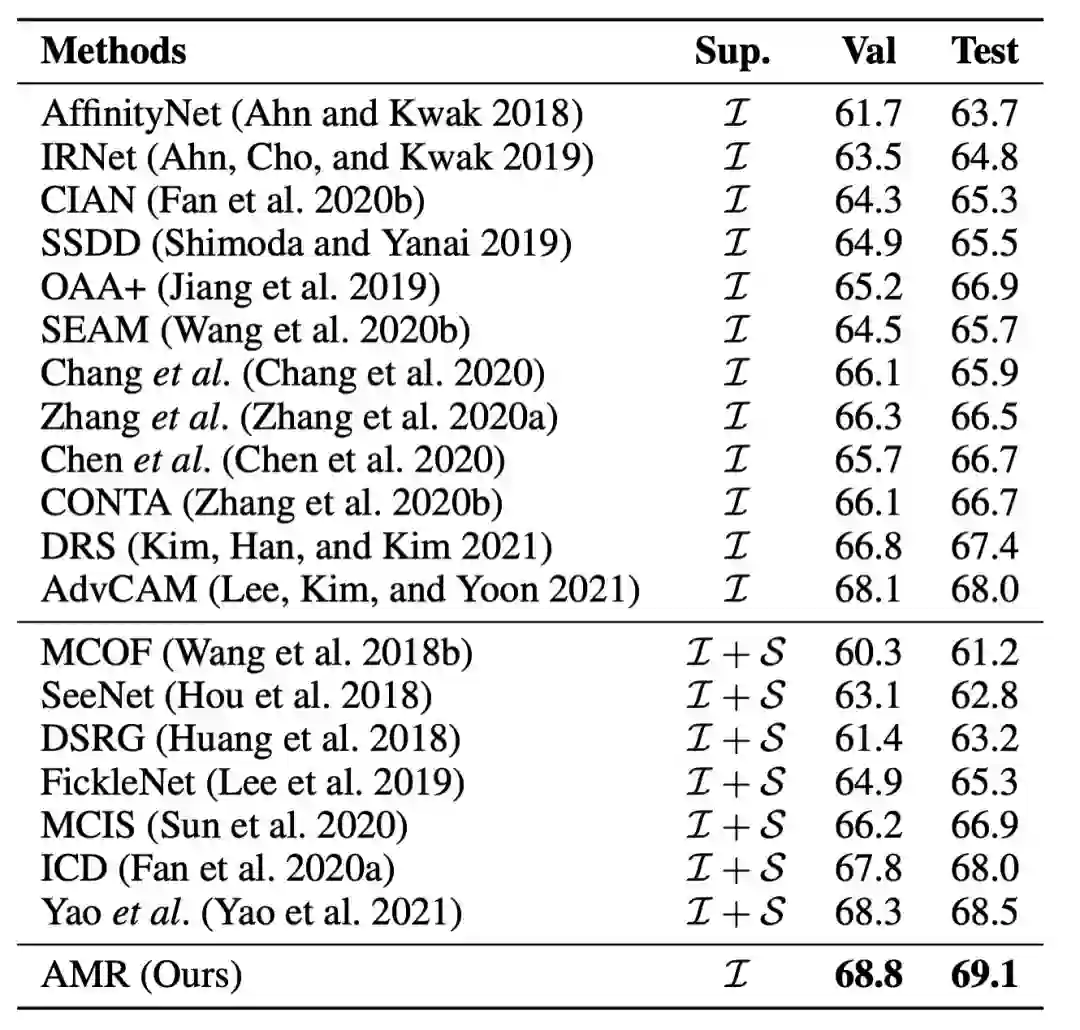
图像级弱监督语义分割(WSSS)是一项基本但极具挑战性的计算机视觉任务,该任务有助于促进场景理解和自动驾驶领域的发展。现有的技术大多采用基于分类的类激活图(CAM)作为初始的伪标签,这些伪标签往往集中在有判别性的图像区域,缺乏针对于分割任务的定制化特征。
为了解决上述问题,字节跳动 - 智能创作团队提出了一种即插即用的激活值调制和重校准(AMR)模块来生成面向分割任务的 CAM,大量的实验表明,AMR 不仅在 PASCAL VOC 2012 数据集上获得最先进的性能。实验表明,AMR 是即插即用的,可以作为其他先进方法的子模块来提高性能。论文已入选机器学习顶级论文 AAAI2022,相关代码即将开源。
![]()
![]()
推荐:
在图像级弱监督语义分割这项 CV 难题上,字节跳动做到了性能显著提升。论文被 AAAI 2022 接收。
论文 7:A Survey of Generalisation in Deep Reinforcement Learning
摘要:
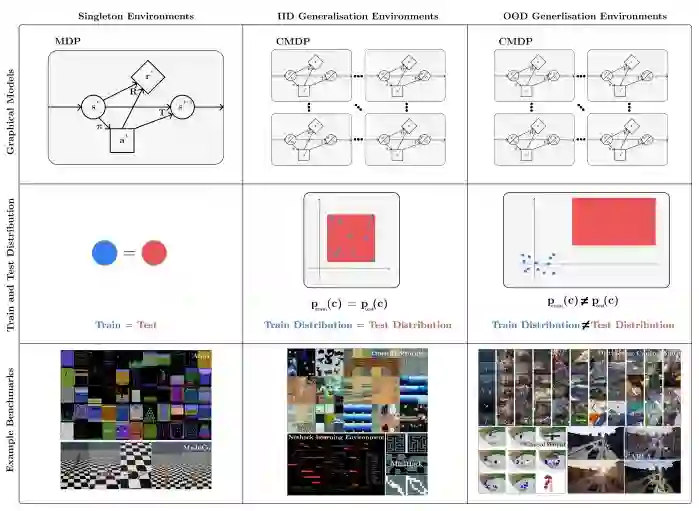
强化学习 (RL) 可用于自动驾驶汽车、机器人等一系列应用,其在现实世界中表现如何呢?现实世界是动态、开放并且总是在变化的,强化学习算法需要对环境的变化保持稳健性,并在部署期间能够进行迁移和适应没见过的(但相似的)环境。然而,当前许多强化学习研究都是在 Atari 和 MuJoCo 等基准上进行的,其具有以下缺点:它们的评估策略环境和训练环境完全相同;这种环境相同的评估策略不适合真实环境。
目前,许多研究者已经意识到这个问题,开始专注于改进 RL 中的泛化。来自伦敦大学学院、UC 伯克利机构的研究者撰文《 A SURVEY OF GENERALISATION IN DEEP REINFORCEMENT LEARNING 》,对深度强化学习中的泛化进行了研究。
![]()
![]()
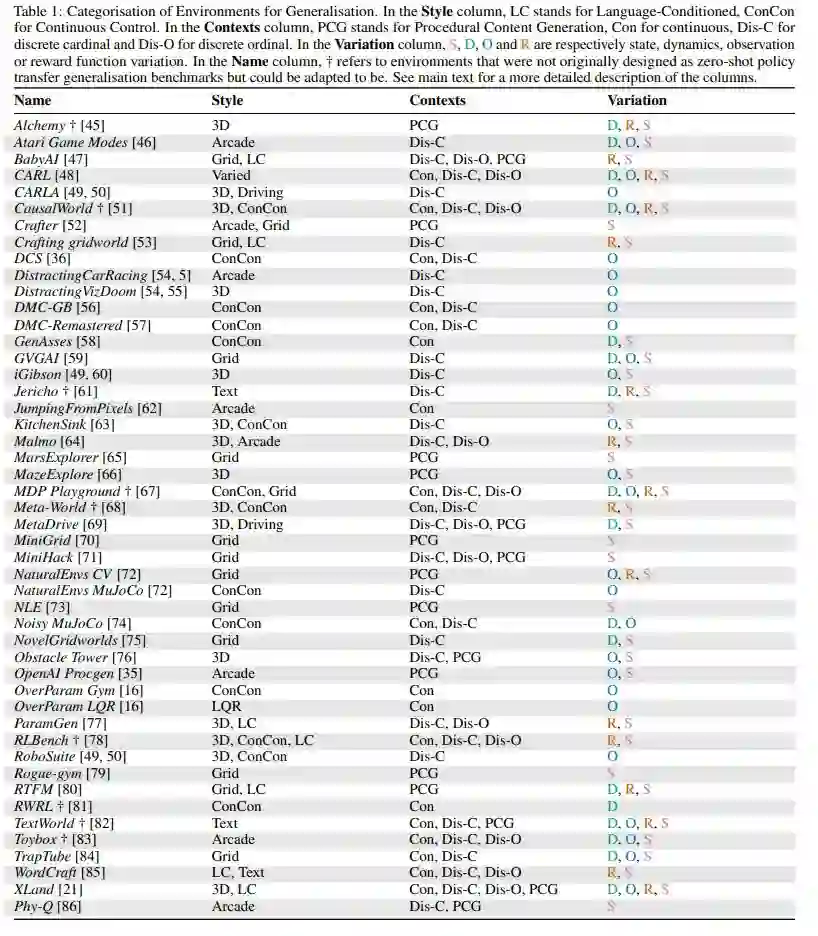
在 RL 中可以进行测试泛化的可用环境,共 47 个。
推荐:
伦敦大学学院、UC 伯克利联手,撰文综述深度强化学习泛化研究。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
本周 10 篇 NLP 精选论文是:
1. OpenQA: Hybrid QA System Relying on Structured Knowledge Base as well as Non-structured Data. (from Yang Liu)
2. Phrase-level Adversarial Example Generation for Neural Machine Translation. (from Jian Yang)
3. TextRGNN: Residual Graph Neural Networks for Text Classification. (from Meng Wang)
4. Utilizing Wordnets for Cognate Detection among Indian Languages. (from Gholamreza Haffari)
5. A Survey on Using Gaze Behaviour for Natural Language Processing. (from Pushpak Bhattacharyya)
6. Fortunately, Discourse Markers Can Enhance Language Models for Sentiment Analysis. (from Ranit Aharonov)
7. BERN2: an advanced neural biomedical named entity recognition and normalization tool. (from Jaewoo Kang)
8. Improving Mandarin End-to-End Speech Recognition with Word N-gram Language Model. (from Yuexian Zou)
9. Zero-shot Commonsense Question Answering with Cloze Translation and Consistency Optimization. (from Nanyun Peng)
10. Which Student is Best? A Comprehensive Knowledge Distillation Exam for Task-Specific BERT Models. (from Alham Fikri Aji)
本周 10 篇 CV 精选论文是:
1. iCaps: Iterative Category-level Object Pose and Shape Estimation. (from Dieter Fox)
2. SASA: Semantics-Augmented Set Abstraction for Point-based 3D Object Detection. (from Dacheng Tao)
3. Quality-aware Part Models for Occluded Person Re-identification. (from Dacheng Tao)
4. PCACE: A Statistical Approach to Ranking Neurons for CNN Interpretability. (from Seth Flaxman)
5. CaFT: Clustering and Filter on Tokens of Transformer for Weakly Supervised Object Localization. (from Ming Li)
6. Vision Transformer Slimming: Multi-Dimension Searching in Continuous Optimization Space. (from Kwang-Ting Cheng, Eric Xing)
7. Multi-Dimensional Model Compression of Vision Transformer. (from Sun-Yuan Kung)
8. Aerial Scene Parsing: From Tile-level Scene Classification to Pixel-wise Semantic Labeling. (from Liangpei Zhang)
9. D-Former: A U-shaped Dilated Transformer for 3D Medical Image Segmentation. (from Jian Wu)
10. Scene-Adaptive Attention Network for Crowd Counting. (from Yihong Gong)
本周 10 篇 ML 精选论文是:
1. Learning Agent State Online with Recurrent Generate-and-Test. (from Richard S. Sutton)
2. Randomized Signature Layers for Signal Extraction in Time Series Data. (from Thomas Hofmann)
3. Deconfounded Training for Graph Neural Networks. (from Tat-Seng Chua)
4. Federated Optimization of Smooth Loss Functions. (from Ali Jadbabaie, Devavrat Shah)
5. NumHTML: Numeric-Oriented Hierarchical Transformer Model for Multi-task Financial Forecasting. (from Barry Smyth)
6. Stochastic convex optimization for provably efficient apprenticeship learning. (from John Lygeros)
7. Multi-Agent Reinforcement Learning via Adaptive Kalman Temporal Difference and Successor Representation. (from Konstantinos N. Plataniotis)
8. TransLog: A Unified Transformer-based Framework for Log Anomaly Detection. (from Jian Yang)
9. CausalSim: Toward a Causal Data-Driven Simulator for Network Protocols. (from Devavrat Shah)
10. Transformer Embeddings of Irregularly Spaced Events and Their Participants. (from Jason Eisner)
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com