
今天专知小编介绍的是来自CMU朱俊彦博士等学者在CVPR2022发表的新作。

1 paper简介
- 标题:GAN-Supervised Dense Visual Alignment(GAN监督学习实现的密集视觉对齐)
- 作者:William Peebles, Jun-Yan Zhu, Richard Zhang, Antonio Torralba, Alexei Efros, Eli Shechtman
- 摘要:本文提出了GAN监督学习,这是一个用于学习判别模型及其 GAN 生成的训练数据端到端联合的框架。作者将该框架应用于稠密视觉对齐问题。受经典Congealing 方法的启发,我们的 GANgealing 算法训练一个空间transformer,将随机样本从在未对齐数据上训练的 GAN 映射到常见的联合学习目标模式。我们展示了八个数据集的结果,所有这些结果都表明我们的方法成功地对齐了复杂数据并发现了密集的对应关系。GANgealing显著优于过去的自监督对应算法,在多个数据集上的性能与最先进的监督对应算法相当(有时甚至超过),而无需使用任何对应监督或数据增强,尽管专门针对GAN生成的数据进行训练。为了精确对应,我们对目前最先进的监督方法进行了多达3倍的提升,我们展示了此方法在增强现实、图像编辑和用于下游 GAN 训练的图像数据集自动预处理方面的应用。
- 原文:https://www.zhuanzhi.ai/paper/d5539f2061329634953967ab2e5ea1c0
- 代码:https://github.com/wpeebles/gangealing
- 工程:https://www.wpeebles.com/gangealing
2 主要作者
朱俊彦博士是卡内基梅隆大学计算机科学学院机器人研究所的助理教授。在计算机科学系和机器学习系担任附属教员。研究计算机视觉、计算机图形学、机器学习和计算摄影。朱俊彦博士是计算机图形学领域现代机器学习应用的开拓者。其论文可以说是第一篇用深度神经网络系统地解决自然图像合成问题的论文。因此,他的研究对这个领域产生了重大影响。他的一些科研成果,尤其是 CycleGAN,不仅为计算机图形学等领域的研究人员所用,也成为视觉艺术家广泛使用的工具。在CVPR2022上共录用4篇论文。
3 Introduction
视觉对齐,也被称为对应或注册问题,是许多计算机视觉的关键元素,包括光流、3D匹配、医学成像、跟踪和增强现实。虽然最近在两两对齐(图像A与图像B的对齐)方面取得了很大进展,但全局对齐(整个数据集上的所有图像对齐)的问题还没有得到足够的关注。然而,对于需要通用参考框架的任务,例如自动关键点注释、增强现实或编辑传播(参见下图底部行),联合对齐是至关重要的。也有证据表明,在联合对齐数据集(如FFHQ,AFHQ, CelebA-HQ)上进行训练可以产生比在非对齐数据上更高质量的生成模型。

给定一个未对齐图像的输入数据集,GANgealing算法发现所有图像之间的密集对应关系。最上面一行:来自LSUN Cats的图像和数据集的平均图像。第二行:我们学习了输入图像的转换。第三行:GANgealing学习的密集的对应。最后一行:通过对平均的转换图像进行注释,我们可以将用户的编辑传播到图像和视频中。 本文从一系列经典的联合图像集自动对齐的研究中得到启发。特别是,我们受到了learning - miller的无监督固化方法的启发,该方法表明,一组图像可以通过不断地将它们转换成一个公共的、更新的模式来进行对齐。尽管Congealing在简单的二值图像(如MNIST数字)上工作得非常好,但直接的像素级对齐并不足以处理大多数具有显著外观和姿态变化的数据集。
为了解决这些限制,我们提出GANgealing:一种GAN监督算法,可以学习输入图像的转换,使它们进入更好的联合对齐。关键在于利用GAN的潜在空间(在未对齐的数据上训练)自动为空间Transformer生成成对的训练数据。最重要的是,在我们提出的GAN监督学习框架中,空间Transformer和目标图像是联合学习的。我们的空间Transformer是专门训练与GAN图像,并在测试时推广到真实的图像。 我们展示了跨越8个数据集的结果——LSUN Bicycles, Cats, Cars, Dogs, Horses,TVs, In-The-Wild CelebA,CUB——证明了我们的GANgealing算法能够发现跨数据集的精确、密集的通信。我们展示了我们的空间Transformer在图像编辑和增强现实任务中是有用的。在数量上,GANgealing显著优于过去的自监督密集对应方法,在许多SPair71K类别上关键点转移准确度(PCK)几乎加倍。此外,GANgealing有时甚至超过了最先进的通信监督方法。
4 GANgealing算法架构
提出了 GAN 监督学习,这是一个用于学习判别模型及其 GAN 生成的训练数据端到端联合的框架。将我们的框架应用于密集的视觉对齐问题。受经典 Congealing 方法的启发,我们的 GANgealing 算法训练一个空间Transformer,将随机样本从在未对齐数据上训练的 GAN 映射到常见的联合学习目标模式。目标模式已更新,以使空间Transformer的工作“尽可能简单”。
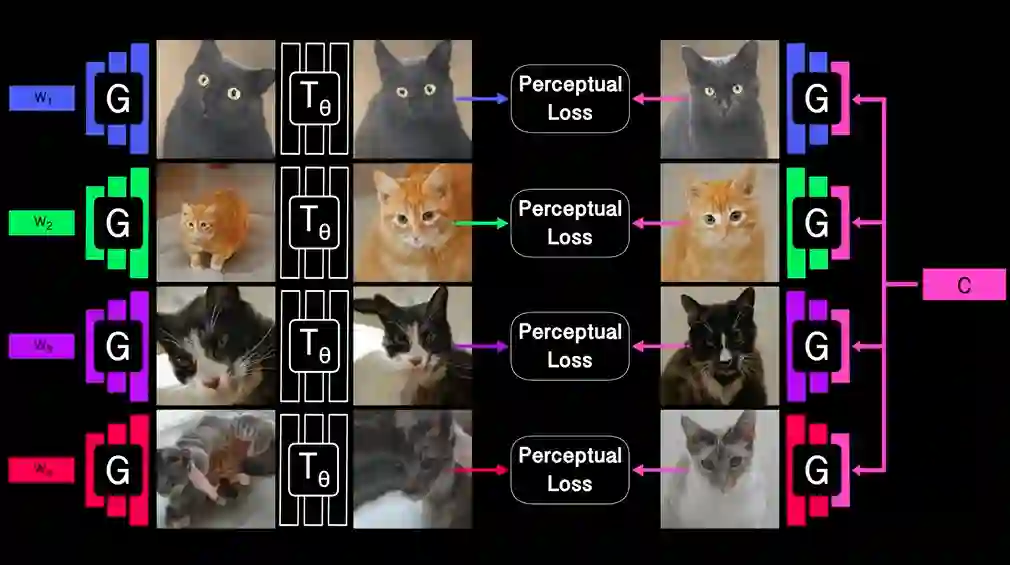
GANgealing 显着优于过去的自我监督对应算法,并且在多个数据集上的性能与(有时甚至超过)最先进的监督对应算法相当——尽管经过培训,但没有使用任何对应监督或数据增强专门针对 GAN 生成的数据。为了精确对应,我们将最先进的监督方法提高了 3 倍。
5 通过联合对齐实现密集对应
我们的 Spatial Transformer 专门针对 GAN 图像进行训练,并在测试时自动推广到真实图像。在这里,我们展示了 Spatial Transformer 对真实 LSUN Cat 图像的学习转换,将它们带入联合对齐。然后我们可以通过凝结的平均图像找到所有图像之间的密集对应关系。

6 使用GANgealing轻松编辑图像
任何东西都可以从我们平均的凝结图像中传播出来。通过将蝙蝠侠面具拖到我们平均凝固的猫图像上,用户可以毫不费力地自动编辑大量图像。

7 与RAFT性能对比
当将每帧应用于视频而不利用任何时间信息时,GANgealing 会产生令人惊讶的平滑结果。与受复合错误影响的 RAFT 等监督光流算法相比,这使得我们的方法非常适合混合现实应用。而且,GANgealing 不需要任何视频注释来传播对象:只需注释一次平均固化图像,您就可以处理任何图像或视频。



