论文浅尝 - ICLR2020 | Pretrained Encyclopedia: 弱监督知识预训练语言模型
论文笔记整理:陈想,浙江大学博士,研究方向为自然语言处理,知识图谱。

Wenhan Xiong, Jingfei Du, William Yang Wang, Veselin Stoyanov.Pretrained Encyclopedia: Weakly Supervised Knowledge-Pretrained Language Model
来源:ICLR2020
链接:https://arxiv.org/abs/1912.09637
Motivation
近年来在大规模数据集上预训练的的语言模型(以BERT和XLNET为代表)在多项NLP任务上达到SOTA水平。研究发现预训练,过程可以使模型学到语言的语法和语义信息并迁移至下游任务。有趣的是,经过预训练的模型在需要基础语言和对现实世界进行推理的任务上也能获得较好的效果。
但是,现有的预训练目标通常是在token级别定义的,并没有明确的以实体为中心的知识建模。在本文中,作者调查了是否可以进一步实施预训练模型,以专注于现实世界实体的百科知识,以便它们可以更好地从自然语言中捕获实体信息,并应用于改进与实体相关的NLP任务。
与此同时,目前的预训练语言模型通常专注于基于最大似然估计(MLE)的Masked Language Model(MLM)作为目标任务,即采用的“生成式模型”。然而MLM的损失计算都是基于token-level的,对于高层次的抽象理解较难学习到。
因此本文提出了尝试将判别式的对比学习目标函数作为NLP预训练的目标,具体的,采用Replaced Entity Detection(RED),基于维基百科用相同类型的其他实体的名称替换原始文档中的实体提及,训练模型区分正确的实体提及和随机选择的其他实体提及以设法让模型能够理解entity-level的特征。相比先前的工作采用的利用外部知识库获取实体知识的方法,该方法能够直接从非结构化文本中获取真实世界的知识。
Model/Methods
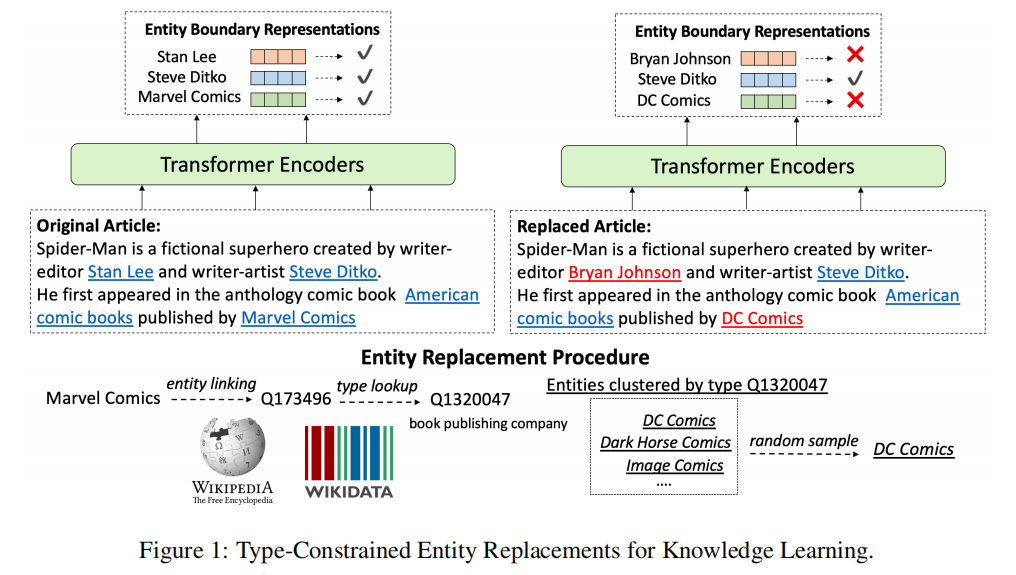
(1)数据准备
使用英文维基百科作为训练数据,文档中的实体根据维基百科中的锚链接和Wikidata(三元组知识库)的实体名来识别。即首先检索由锚链接注释的实体,然后通过字符串匹配它们在Wikidata中的名称,以检索其他提到这些实体的地方。通过此方法可以使用现成的实体链接工具,很容易扩展至其他语料库
(2)替换策略
如图1所示,进行实体替换时首先需通过Wikidata知识库确定其实体类型,并随机选取该实体类型下的其他实体替换原实体,每个实体会通过同样的方式进行10次替换,生成10个不同的负例。相邻实体不会被同时替换,以避免多个连续的负例组成了符合事实的描述。
(3)训练目标
对于在上下文C中提到的某个实体e,我们训练模型进行二进制预测,以指示该实体是否已被替换:
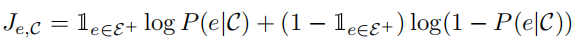
Experiments
本文在事实补全、四个与实体相关的问题回答数据集(WebQuestions,TriviaQA,SearchQA和QuasarT)和一个标准的细粒度实体类型数据集设置了实验。实验及结果介绍如下:
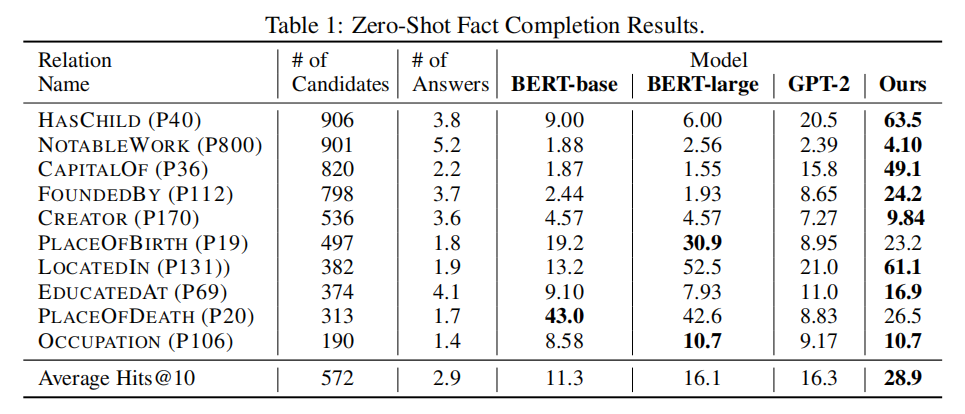
(1)事实补全任务
基于Wikidata中的事实三元组,筛选了10种重要关系,人工构建三元组的自然语言表述,以此训练模型进行实体补全。本文对每种关系构建了1000例数据,对比了使用生成式语言模型目标进行预训练的原始BERT和GPT-2,使用传统三元组补全任务的评估指标hits@10进行评估,结果如下:
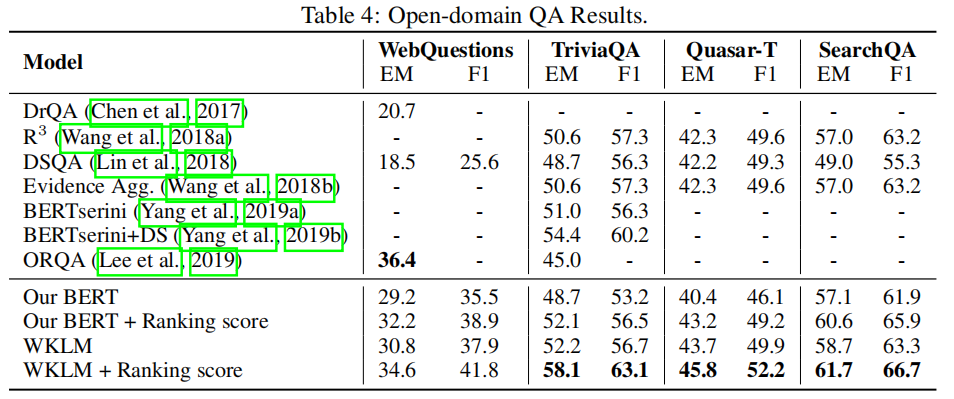
(2)QA
本文在4个基于实体答案的开放领域问答数据集上进行了微调实验,如表4所示,WKLM在3个QA任务上达到了SOTA,说明了基于实体替换的判别式对比学习的有效性。
(3)实体类型判别
该任务的目标是从自然语言句子中发现所提到的实体的细粒度类型信息,模型在远程监督训练数据上进行了最小化二元交叉熵损失的训练
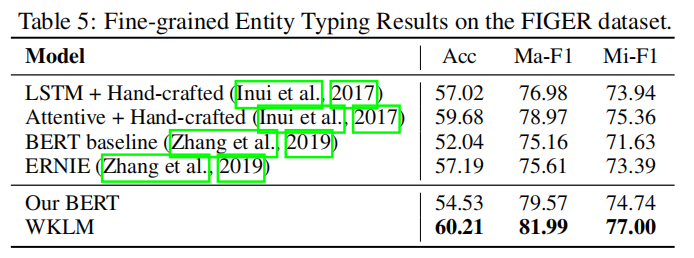
(4)消融研究
该部分主要验证本文提出的实体替换目标函数相对于原始BERT的效果有明显提升,以及不同程度上搭配BERT原始的MLM loss对应的效果。
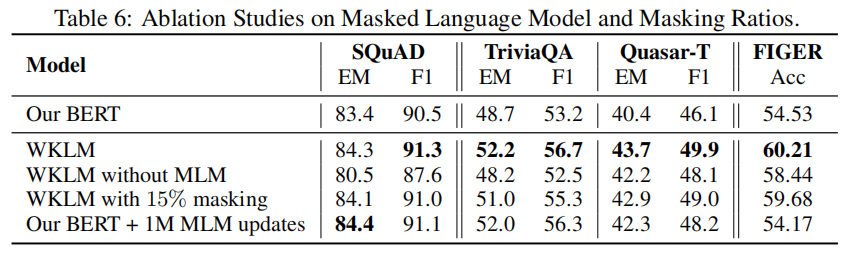
结果表明提出的实体替换目标有效提高了模型在QA和实体类型判别任务上 的性能,而对于遮蔽语言模型任务,过高或过低的遮蔽比例均会不同程度上 损害模在QA任务上的表现。
Conclusion
本文提出将判别式的对比学习目标函数作为NLP预训练目标,通过完善的实验证明了这一训练范式的有效性和可行性,即对于更注重实体相关信息的NLP任务,采取本文提出的对比式实体替换目标进行预训练优于生成式的遮蔽语言模型预训练。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。



