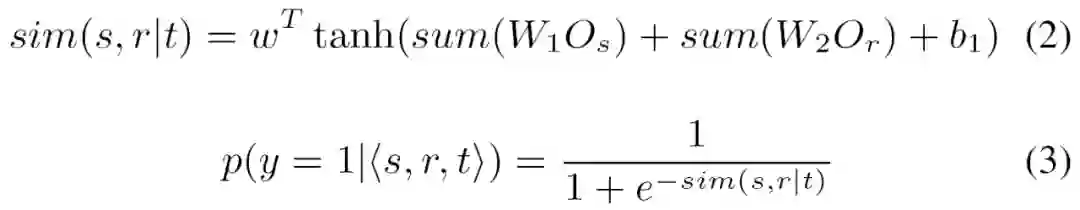本文转载自公众号:知识工场。
作者:蒋海云,复旦大学2016级计算机博士生,研究方向为知识图谱与自然语言处理。目前已在 IJCAI,AAAI,ACL,DASFAA等会议上发表文章。
IJCAI 2019(The 28th International Joint Conference on Artificial Intelligence)将于当地时间8月10日至8月16日在中国澳门举行。作为人工智能领域最顶级的国际学术会议之一,本次会议投稿量有 4752 篇,接收率为 17.8%。知识工场实验室发表“关系抽取”相关论文一篇,名为《Relation Extraction Using Suervision from Topic Knowledge of Relation Labels》,以下为具体内容:
![]()
1、Introduction
关系抽取旨在基于文本上下文识别出实体对的语义关系。这些关系通常是预先定义好的。例如,给定实体对[ Microsoft, Bill Gates ]和句子“Bill Gates co-founded Microsoft withhis childhood friend Paul Allen”,我们希望抽取出关系“ founder ”。
传统的方法通常将关系抽取建模为分类问题或者标注问题。在这些方法中,不同的关系标签往往被视为不同的 ID。例如,在关系分类中,每个 ID 代表多分类问题的一个类别( class )。给定一个样本,模型将其映射到一个或多个关系 ID 。然而,关系标签包含着非常丰富的语义信息,这些语义信息被现有的关系抽取模型所忽略。我们认为,充分建模关系标签的语义信息并将其作为关系分类的监督信号,有望进一步提升关系抽取性能。
很显然,仅仅靠关系标签这个词组本身很难挖掘出太多的语义信息。因此,我们需要引入额外的信息作为关系的背景知识。为了克服这一挑战,本文求助于主题模型。对于预定义关系,我们通过相应的训练句子集合进行主题建模,进而从训练数据中挖掘出关系的主题知识。我们的基本假设是:对于每个关系,其标注句子集合包含几个潜在主题,并且这些主题在语义上与关系是相关的。通过主题建模,我们提取前k个带权重的主题词来表示关系的语义。因此,关系的主题知识被具体化为带权重的词袋( weighted bag of words, WBoW )。不难理解,每个主题词都刻画了关系的某些方面,而词的权重则刻画了它对关系的重要性。因此,一个被标注为该关系的句子应该匹配关系的某些重要方面。
![]()
图1中给出了一个例子来说明主题知识如何为关系抽取( RE )提供有效的监督信息。对于图左边的四个句子,我们希望推断这些句子是否表达了 CEO 关系。对于人类而言,我们知道第一句和第二句明确表达了这种关系,而第三句则较弱地表达了关系。进一步地,第四句则完全没有表达这种关系。通过引入CEO的主题知识,我们发现第一句和第二句与 CEO 关系的大多数重要主题词匹配,而最后一句与其中任何一个主题词都不匹配。因此,主题知识提供的语义信息能有效地支持关系推理。
2、Overview
![]()
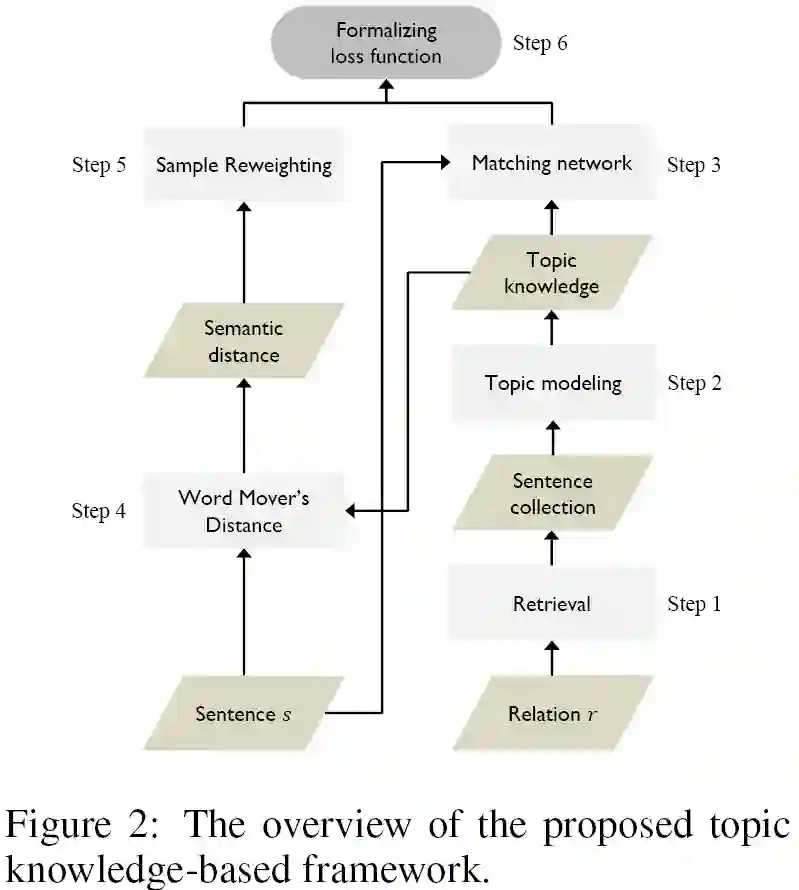
我们在图2中给出了应用关系的主题知识的框架流程图。主要步骤如下。
步骤1:从训练句子中检索关系r的所有句子。
步骤2:获取 r 的主题知识,即通过主题建模从r的标记句子集合中提取前k个加权主题词。
步骤3:为句子-关系对( s; r )建立深度匹配网络。
步骤4:基于主题知识,通过 Word Mover Distance( WMD )计算 s 和 r 之间的语义距离 d ( s,r )。
步骤5:根据语义距离 d ( s,r ) 计算样本的重要性权重。
步骤6:基于深度匹配网络和样本重要性权重建立损失函数。
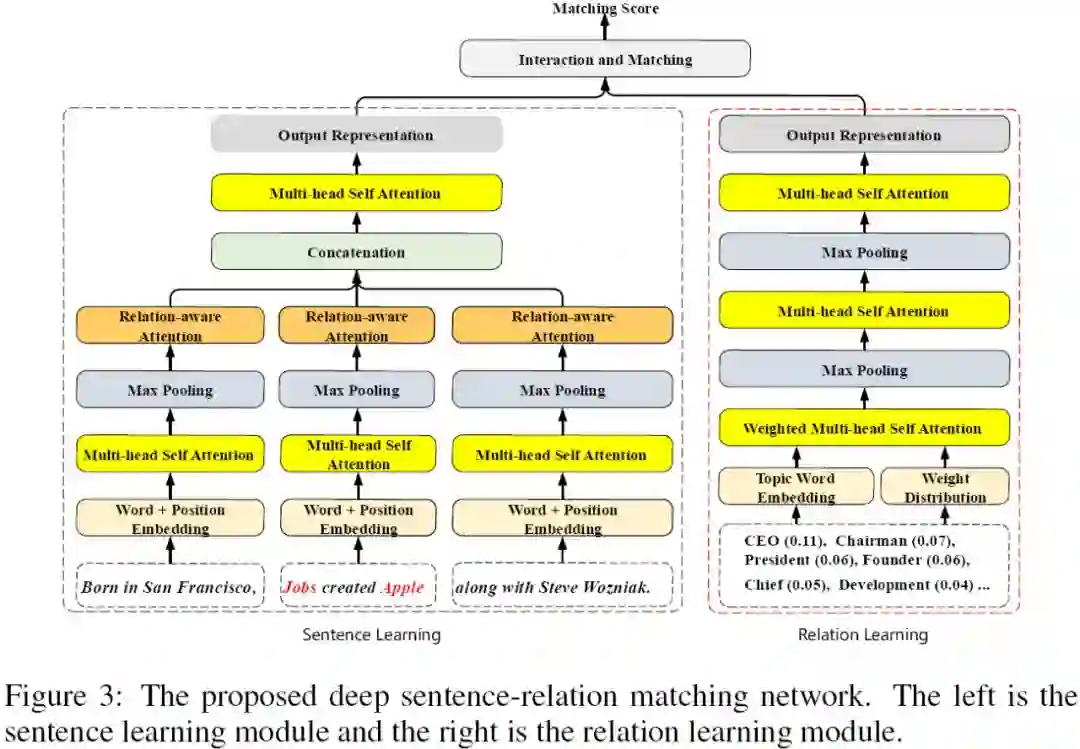
3、Framework Sentence-Relation Matching Network
![]()
整个句子关系匹配网络包括三部分:
句子学习模块,关系学习模块以及句子关系匹配模块。
句子学习模块。
按照头尾实体的位置,我们将句子分成三部分。
主要原因有两个。
第一:
在一个句子中,表达实体对关系的往往位于实体对之间。
因此,每部分对于关系推理的贡献是不一样的。
第二,为了后续注意力机制的处理,将句子分块可以显著提升效率。
句子学习模块主要采用多头的注意力机制( multi-head self-attention )。
此外,关系敏感的注意力机制( relation-awareattention )旨在将学习到的句子特征中关系敏感的部分抽取出来,从而降低噪声的影响。
关系学习模块。
关系学习模块的输入是关系的主题词集合。
在该模块中,我们仍采用自注意力机制。
但值得注意的是,在输入词袋中我们考虑了每个词的先验权重,因此,我们希望在自注意力机制学习中将该先验权重考虑进去。
这在 weighted multi-head self-attention 中实现。
句子关系匹配模块。
基于学到的句子表示和关系表示,我们采用简单的全连接操作实现匹配建模。
其中,匹配函数为:
![]()
其中,Os 是句子 s 的特征矩阵,Or 是关系 r 的特征矩阵。
p(y=1|<s,r,t>) 表示句子 s 在表达实体对 t 的关系 r 的概率。
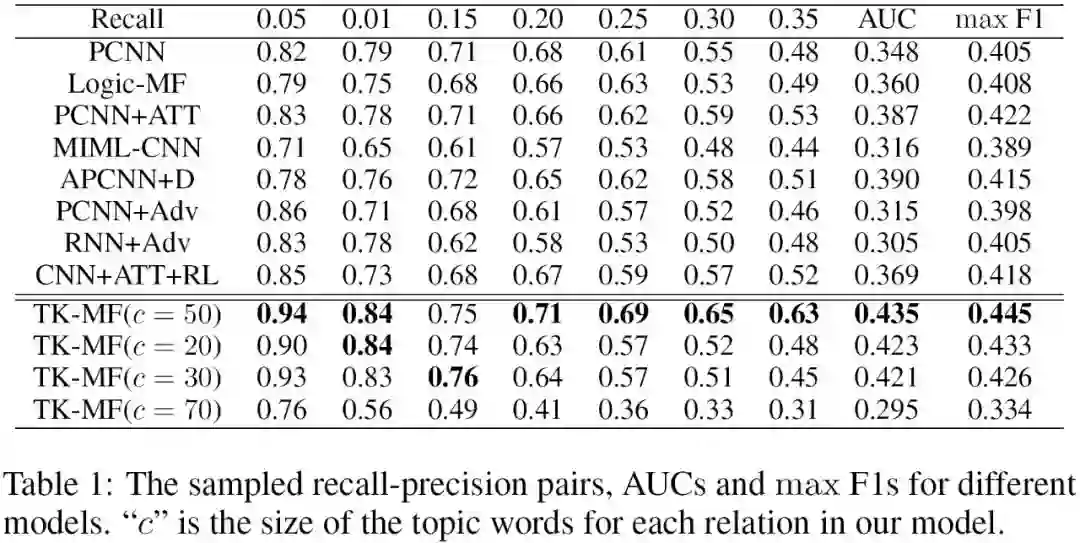
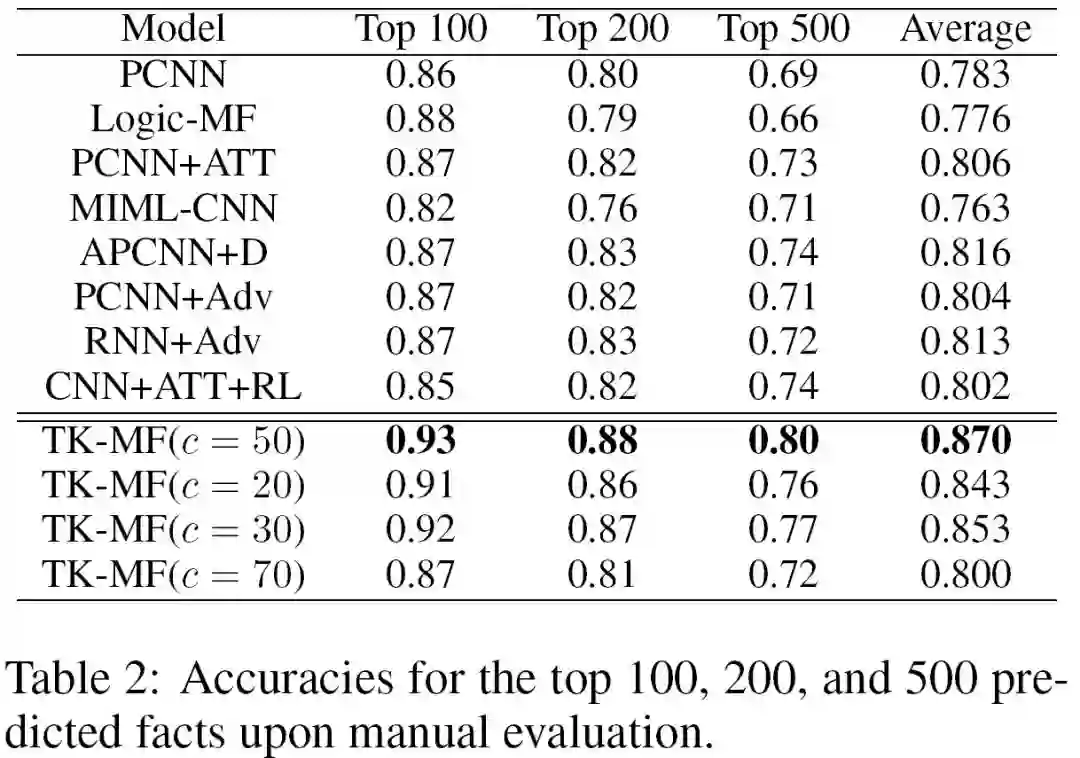
4、Experiments
![]()
![]()
5、Conclusion
在本文中,我们挖掘关系标签的主题知识来表示其语义信息,这为关系抽取提供了有效的监督。
进一步地,我们提出了一种新的深度匹配网络。
值得注意的是,我们的框架适用于许多采用分类的NLP任务,这也是我们未来工作的主要研究方向。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。
![]()
点击阅读原文,进入 OpenKG 博客。