论文浅尝 | 远程监督关系抽取的生成式对抗训练

动机
远程监督关系抽取方法虽然可以使用知识库对齐文本的方法得到大量标注数据,但是其中噪声太多,影响模型的训练效果。基于 bag 建模比基于句子建模能够减少噪声的影响,但是仍然无法克服 bag 全部是错误标注的情形。为了换机噪声标注,本文提出基于对抗神经网络的方法,尝试从自动标注数据中清除噪声。实验结果表明,本文提出的方法能够有效去除噪声,提升远程监督方法的抽取性能。
方法框架
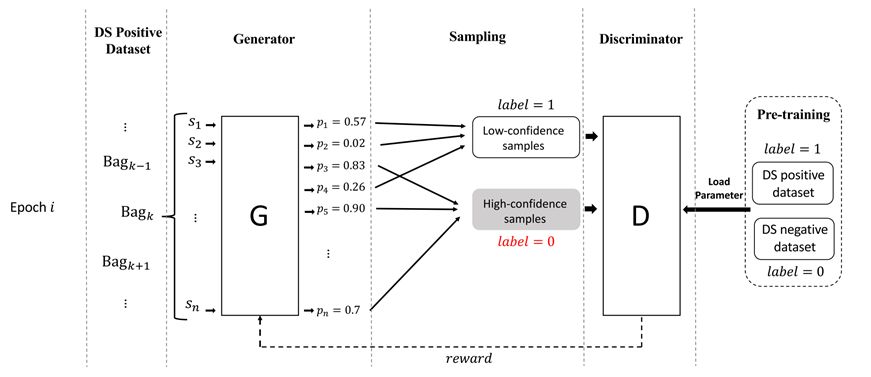
本文提出的方法包括一个生成器和一个判别器,他们的功能是:
生成器:生成器用于将关于关系 r 的有噪声的数据 P 划分成两组:表示正确标注数据的TP和表示错误标注数据的 FP。模型会输出每个句子是正确标注的概率,然后依据该概率抽样,得到 TP,剩余的作为 FP。
判别器:评价生成器生成的数据划分的好坏。评价的方法是:首先使用标注为关系 r 的数据 P 和非 r 的数据 N 对判别器做预训练。在评价生成器的划分 TP FP 时,有意颠倒 TP FP 的标签,即 TP 标记为负例,FP标记为正例,从而形成错误的训练数据,使用该数据继续训练判别器,看看该判别器性能下降情况。判别器性能下降越多,说明颠倒标签的TP FP越错误,也就是TP FP越正确。
对抗过程是:生成器生成数据划分之后,判别器通过训练过程来评价该划分的好坏,并将结果反馈给生成器。生成器根据反馈生成更好的数据,从而更大程度地降低判别器的判别能力。
实验
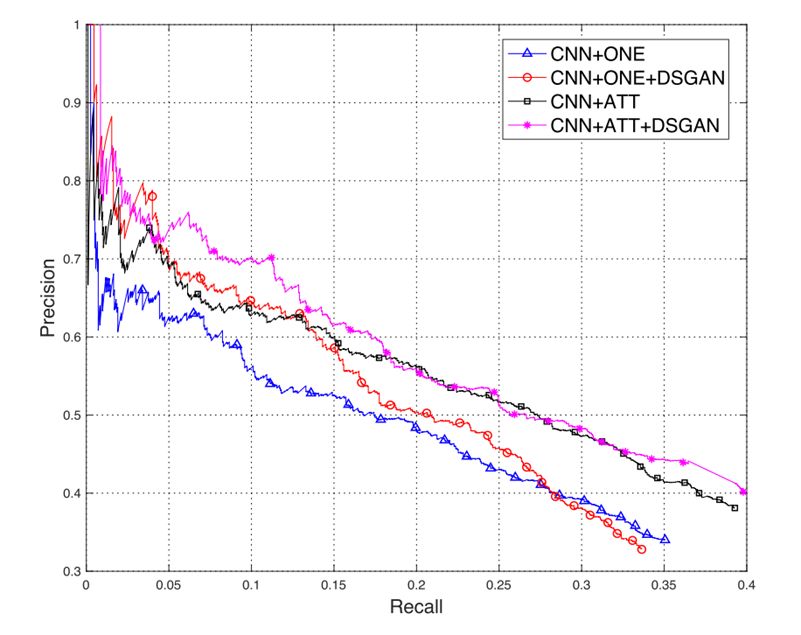
实验部分分析了训练过程中生成器和判别器的收敛情况、以及去噪效果。在去噪效果方面,从下面的 P-R 图可以看出,在去噪后的数据上训练得到的模型比在去噪前的数据上训练的模型效果更好。
笔记整理:刘兵,东南大学计算机学院博士,研究方向为机器学习、自然语言处理。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。


