ACL 2020 | 用于链接预测的开放知识图谱嵌入

©PaperWeekly 原创 · 作者|舒意恒
学校|南京大学硕士生
研究方向|知识图谱
当前大量的知识图谱都是通过文本直接构建的。由于当前的知识图谱构建方法的局限性,其中难免包含对同一实体或关系的多种表述。

论文标题:Can We Predict New Facts with Open Knowledge Graph Embeddings: A Benchmark for Open Link Prediction
论文来源:ACL 2020
论文链接:https://www.aclweb.org/anthology/2020.acl-main.209/


链接预测是知识图谱上需要推理的一个常见任务。它的目标是预测知识图谱上缺失的事实。而当前知识图谱嵌入模型已成功用于预测知识图谱中的缺失事实。

相比于一般的知识图谱,开放知识图谱包含丰富的概念知识。开放知识图谱可能包含更多的噪声,并且事实知识可能更加不确定。
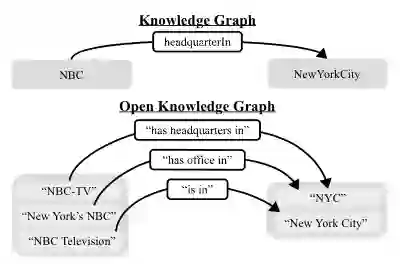
如图,一般的知识图谱(curated KGs)对比开放知识图谱(open KGs)。

因此,该准则需要(1)待评价三元组的头实体和尾实体的注解,以及(2)这些实体的全面的表述集合。

构建开放链接预测的基准测试
作者将其提出的基准测试,称为 OLPBENCH,它基于 OPIEC [1] 构建,后者是一个最近发布的数据集,它从英文维基百科的文本构建得到。
短关系通常归属于长关系。
长关系更少地被简单的应用于知识图谱构建方法的模式所捕捉。
自动提取的实体注解,对于短关系来说略显嘈杂。
VALID-ALL:没有人类的工作
VALID-MENTION:其中有部分人类的工作。
VALID-LINKED:大多数是人类的工作。
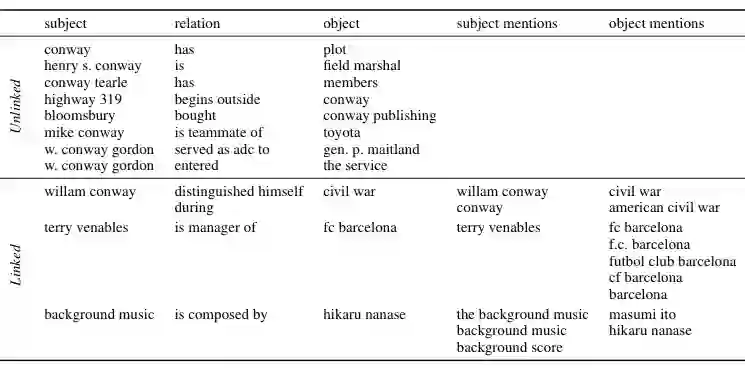
如图是 OLPBENCH 中链接数据与非链接数据的样例。
作者使用了三个级别的泄漏移除方法,称为 SIMPLE、BASIC 和 THOROUGH,即简单的、基本的和彻底的泄漏移除。例如,训练数据中存在三元组 (i, k, j) 的情况:
-
简单移除:只有三元组 (i, k, j) 被移除,i 和 j 的其他表述不被移除。 -
基本移除:三元组 (i, k, j) 和 (j, k, i) 都被移除,i 和 j 的其他表述也都被移除。 -
彻底移除:在基本移除的基础上,按以下模式移除评估数据中的三元组: (i, *, j) 和 (j, * i),即删掉两实体间任何方向的任何形式的关系,例如,三元组 (“J. Smith”, “is player of”, “Liverpool”).
(i, k + j,∗) 和 (∗, k + i, j),例如,三元组,(“J. Smith”, “is Liverpool’s defender on”, “Saturday”).
(i + k + j, ∗, ∗) 和 (∗, ∗, i + k + j),例如,三元组 (“Liverpool defender J. Smith”, “kicked”, “the ball”).

作者使用一个通用的模型架构,它组合了关系模型和组合函数。关系模型用于对三元组的评分,组合函数用于对一个实体或关系的多个 token 的组合。
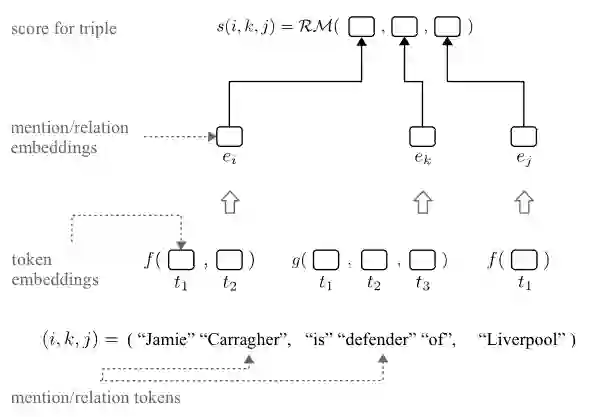
使用组合的知识图谱嵌入模型。三元组的 token 首先被分别的嵌入,然后组合为一个表述或关系嵌入。最后,一个知识图谱嵌入模型被用于计算三元组的分数。


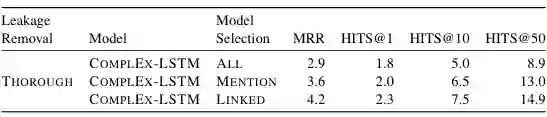
如图是测试集上的结果,同时利用实体和关系的 ComplEx-LSTM 超越了作为对比的 PRED-WITH-ENT / PRED-WITH-REL。同时,泄露移除的程度越大,链接预测的效果越差,一定程度说明现有方法不能很好地处理开放知识图谱。人类对数据集的干预同时对模型表现的提升有影响。
如图是验证集上的结果。效果略高于测试集。

作者提出了开放链接预测任务,以及一种构建开放链接预测基准测试的方法,并构建了一个基准测试 OLPBENCH。作者研究了评估事实的泄露、非关系信息和实体知识对链接预测任务的影响,并通过实验证明其方法预测出的事实基本是新的事实,而不是知识图谱中原有的。

参考文献
更多阅读



#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。




