论文浅尝 | Open world Knowledge Graph Completion

来源:AAAI2018
论文链接:https://arxiv.org/pdf/1711.03438.pdf
代码链接:https://github.com/bxshi/ConMask
本文解决知识库补全的问题,但和传统的 KGC 任务的场景有所不同。以往知识库补全的前提是实体和关系都已经在 KG 中存在,文中把那类情况定义为 Closed-World KGC。从其定义可以发现它是严重依赖已有KG连接的,不能对弱连接有好的预测,并且无法处理从 KG 外部加入的新实体。对此这篇文章定义了 Open-World KGC,可以接收 KG 外部的实体并链接到 KG。论文提出的模型是 ConMask,ConMask 模型主要有三部分操作:
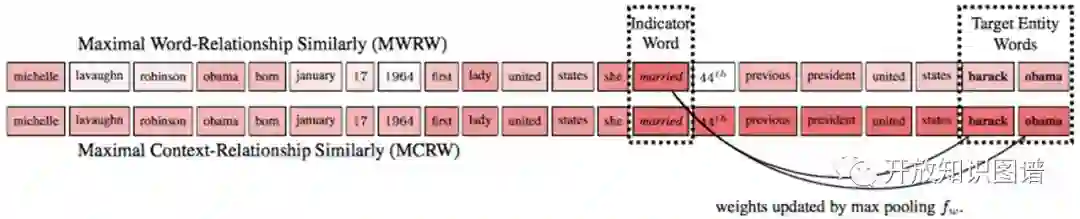
(1) Relationship-dependent content masking:强调留下和任务相关的词,抹去不相关的单词; 模型采用attention机制基于相似度得到上下文的词和给定关系的词的权重矩阵,通过观察发现目标实体有时候在权重高的词(indicator words)附近,提出 MCRW 考虑了上下文的权重求解方法。
(2) Target fusion:从相关文本抽取目标实体的 embedding(用FCN即全卷积神经网络的方法);这个部分输入是masked content matrix,每层先有两个 1-D 卷积操作,再是sigmoid激活函数,然后是 batch normalization,最后是最大池化。
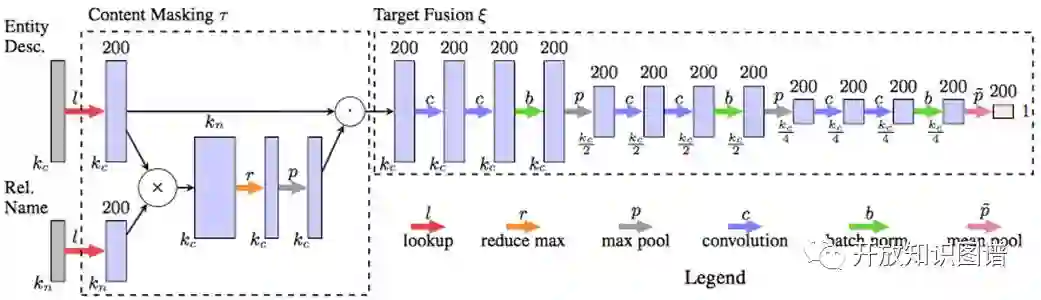
为避免参数过多,在得到实体名等文本特征时本文选用语义平均来得到特征的 embedding 表示
(3) Target entity resolution:通过计算 KG 中候选目标实体和抽取的实体的 embedding 间的相似性,结合其他文本特征得到一个 ranked list。本文设计了一个 list-wise ranking 损失函数,采样时按 50% 比例替换 head 和 tail 生成负样本,S 函数时 softmax 函数
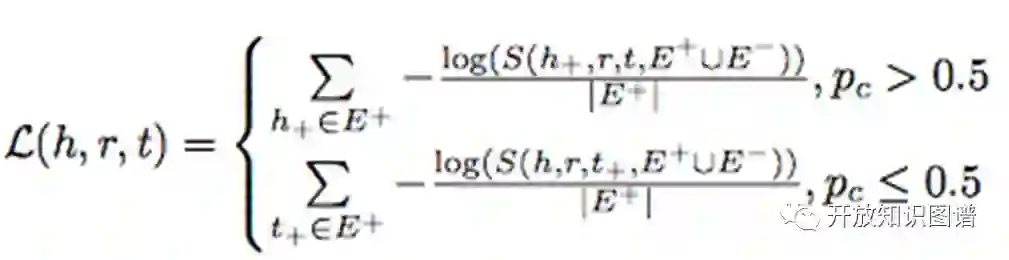
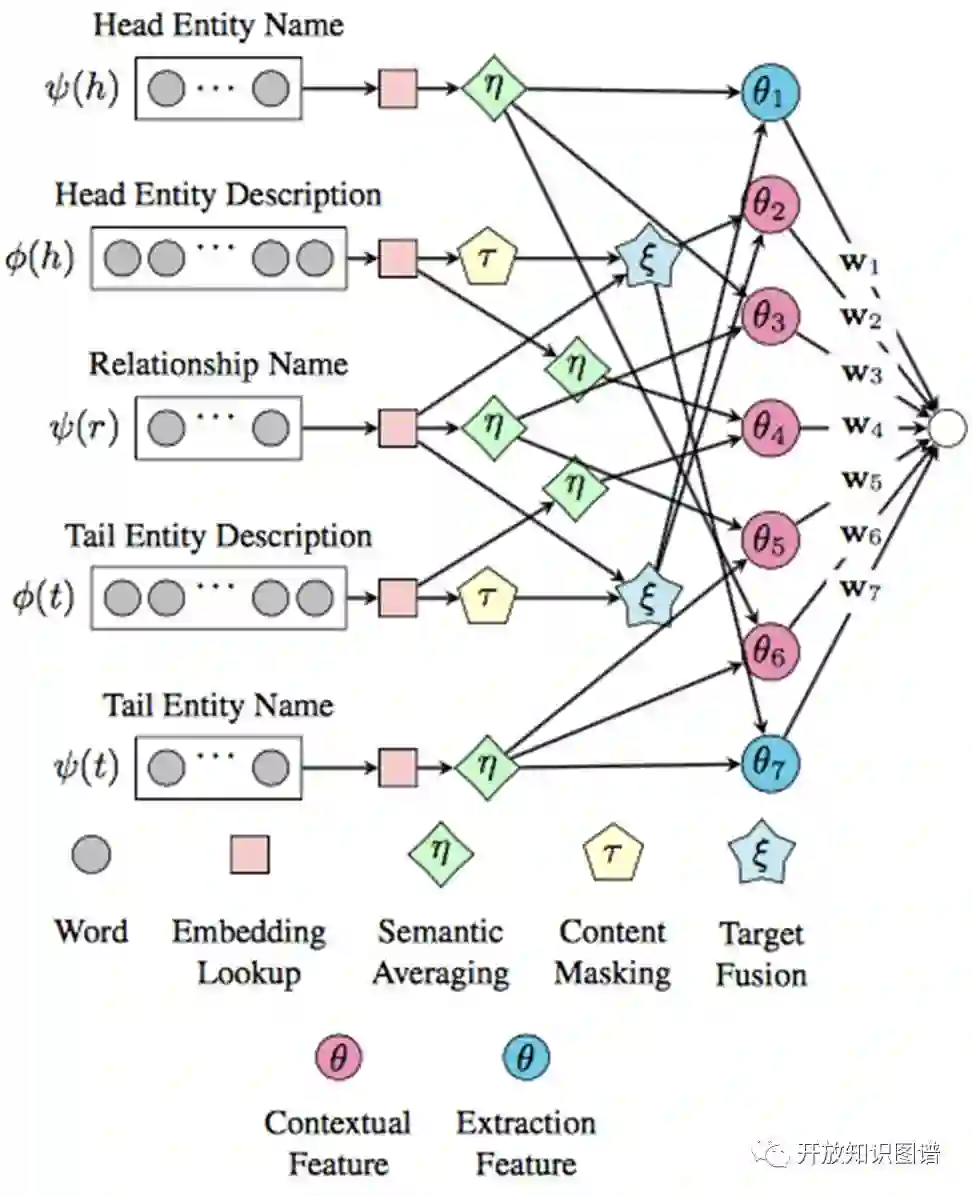
论文的整体模型图为:
本文在 DBPedia50k 和 DBPedia500k 数据集上取得较好的结果,同时作者还添加了 Closed-World KGC 的实验,发现在 FB15k,以及前两个数据集上效果也很不错,证明了模型的有效性。
笔记整理:李娟,浙江大学博士在读,研究兴趣为知识图谱,表示学习。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。





