论文浅尝 | 基于知识库的类型实体和关系的联合抽取

链接:http://hanj.cs.illinois.edu/pdf/www17_xren.pdf
GitHub项目地址:https://github.com/INK-USC/DS-RelationExtraction
动机
现有的利用远程监督进行实体关系抽取的方法中存在以下三个问题:
1、依赖事先训练的命名实体识别工具,而这些工具往往只能识别出少量特定类型的实体,从而限制了领域的扩展;
2、现有方法通常将实体识别和关系抽取分开进行,从而容易造成错误的累积。
3、在通过远程监督方式生成的训练数据中,含有大量的噪音数据,因为其在实体和关系的链接过程中均没有考虑到上下文关系。
贡献
该篇论文的主要贡献分为以下四点:
1、提出了一个新的利用远程监督进行实体关系抽取的框架CoType。
2、提出了一种领域无关的文本分割算法,用来进行文本中 entity mentions 的识别。
3、提出了一个联合嵌入目标函数,用来形式化建模mention-type之间的关联、mention-feature之间的共现关系、entity-relation之间的交叉约束关系。
4、在三个公开数据集上取得了state-of-the-art的效果。
问题定义
给定一个POS标注的语料库D,一个知识库Ψ,一个目标实体类型集合,一个目标关系类型集合,联合抽取的目标就是(1)从语料库D中识别出entity mentions M;(2)利用知识库Ψ生成训练数据;(3)利用和上下文,预测每一个relation mentions的关系类型,以及 entity mentions的实体类型。
方法
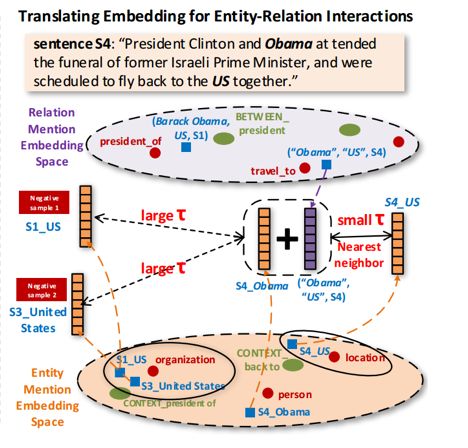
模型框架图如下图所示,其方法主要分为四个部分:
1、使用文章中提出的 POS 约束的文本分割算法对POS标注的语料库D进行实体识别,识别出 entity mentions M。
2、从M中生成候选 relation mentions Z,并对每一个 relation mention 进行文本特征抽取,抽取的文本特征见下文。
3、通过联合嵌入,将 entity mentions、relation mentions、文本特征、实体关系类型嵌入到两个空间中去(实体空间以及关系空间),使得在每一个空间中,距离比较近的object拥有比较近的类型。
4、通过学习好之后的嵌入空间,评估测试集中每一个 relation mention 的关系类型以及每一个entity mention m 的实体类型。
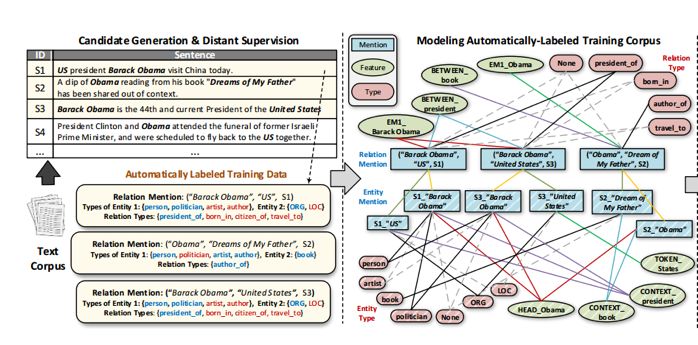
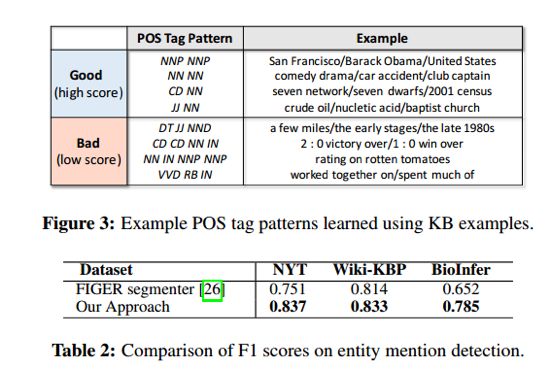
1、 Entity Mention 抽取
文章提出了一种领域无关的文本分割算法,他的方法是通过计算切片质量函数来衡量这个片段是一个entity mention的概率,该切片质量函数由短语质量和POSpattern质量组成,并利用 D_L 数据来训练该模型的参数。
其工作流程主要分为以下四步:
从语料库 D 中挖掘频繁共同模板,包括短语模板和词性模板,并通过设置阈值的方式,进行模板的初步筛选。
从语料级别的一致性和句子级别的词性特征抽取特征训练两个随机森林分类模型,用于评估候选的短语模板和词性模板的分值。
根据目前的特征权重参数,找到切片质量函数得分最高的片段切割方式。
计算修正特征,更正参数,不断迭代2-4步,直到收敛。
切片评估函数如下:
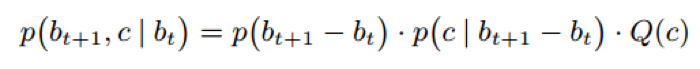
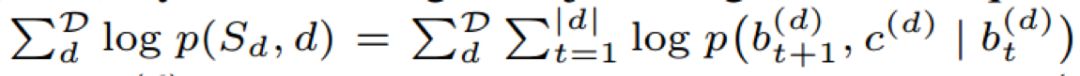
2、 Relation Mention 抽取
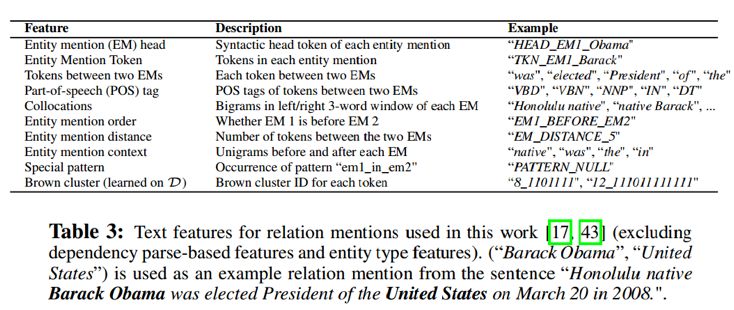
方法如下,对于来自一个句子s的实体对 (m_a,m_b),构建两个候选relation mentions z_1=(m_a,m_b,s) 和 z_2=(m_b,m_a,s)。在抽取30%无法链接到KB的relation mentions作为反例(None relationlabel),抽取30%无法链接的entitymentions建模None entity label。然后对relationmention 进行文本特征抽取,文本特征如下。
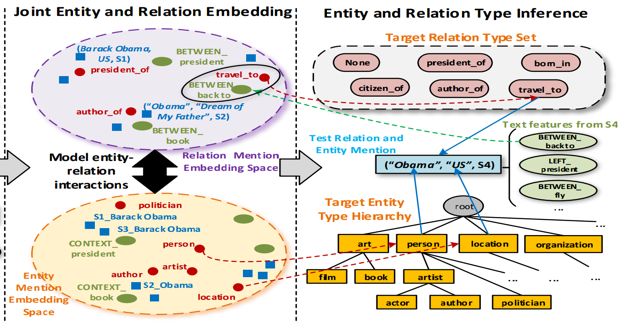
3、 实体和关系的联合嵌入
该部分方法主要包含三个部分:
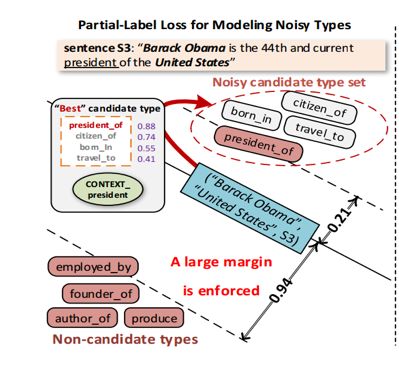
通过一个margin-base的loss函数来建模由噪音的mention-type之间的关系。
通过一个second-order proximity idea来建模mention-feature之间的贡献。
通过translation based embedding loss思想来建模实体-关系之间的约束关系。
3.1建模Relation Mentions
假设1:对于两个relation mentions,如果他们共享的文本特征越多,那么他们则更可能具有相似的类别,即在低维空间中比较接近,反之亦然。
形式化的说,文章应用second-orderproximity来建模该假设。
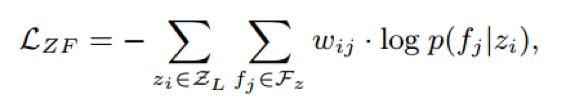
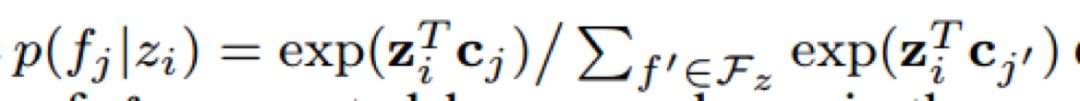
z_i 表示relation mention向量,c_j 表示文本特征向量。p(f_j |z_i) 表示由 z_i 生成 c_j 的概率。w_ij 表示语料库 D 中 (z_i,c_j) 的共现频率。
在基于远程监督生成的训练数据中,一个 relation mention 对应多个候选关系类型,基于假设1,可能会产生不同类型的mention具有相似的低维向量表示。因此需要将relation mention和它候选的标签之间关系是否是真的加入到模型之中,从而提出了假设2。
假设2:一个relation mention在低维空间中应该同它最可能的候选类型比较接近。
形式化定义如下,
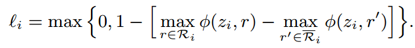
Φ(z_i,r' )表示relation 和关系 r' 之间的点积。
最终,建模relation mentions的目标函数如下所示:

3.2 建模Entity Mentions
Entity Mentions 建模过程如 Relation Mentions 几乎相同,其目标函数如下。
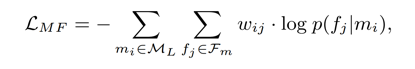
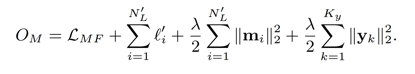
3.3 建模Entity和Relation之间的交互
假设3:对于一个relation mention z={m1,m2,s},m1的嵌入向量应该近似于m2的嵌入向量加上z的词嵌入向量。
形式化如下所示,
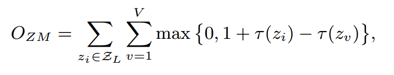
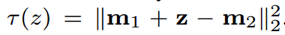
4、 联合优化问题
将上诉三个损失函相加,求他们的最小值。
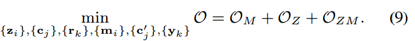
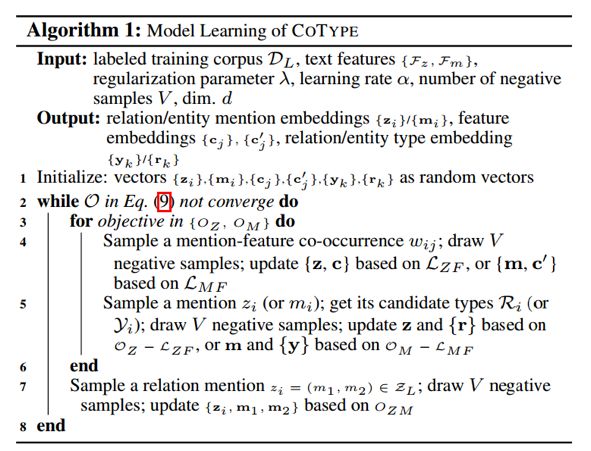
文章中使用了次梯度方法来求解该联合优化问题,算法如下图所示。
5、 模型推断
在进行推断的过程中,对于关系类别,采用最近邻的方式查找,对于实体的类别,采用自顶向下的方式查找。在查找的过程中,利用特征来表示mention,计算mention的嵌入向量同实体类别和关系类别的相似度即可。
实验
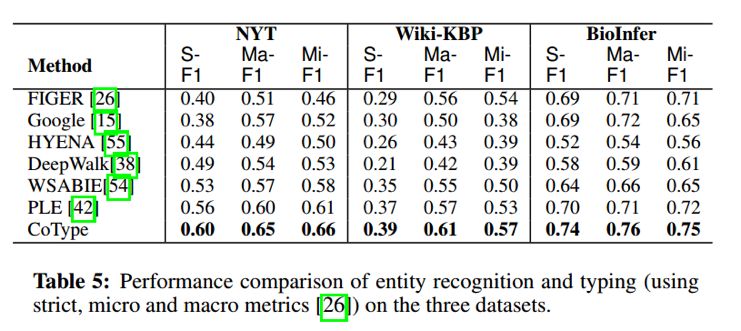
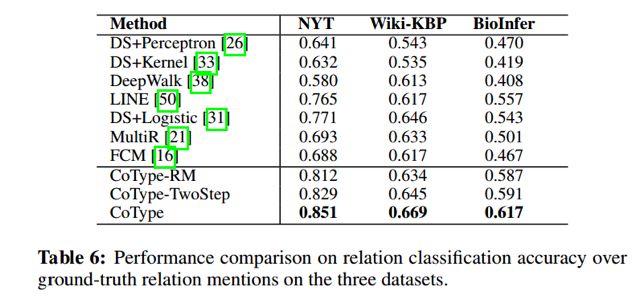
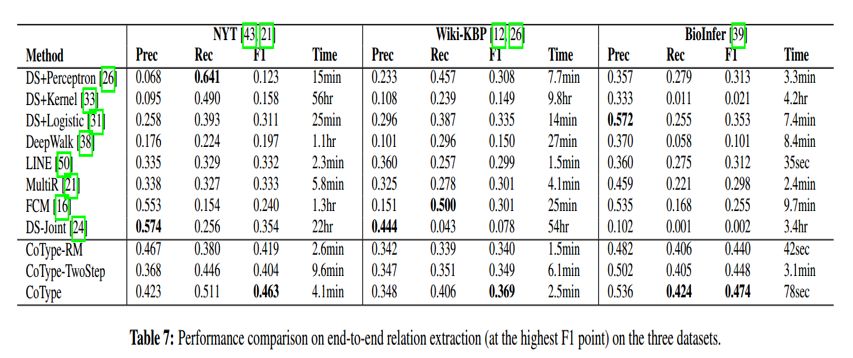
作者在NYT、Wiki-KBP、BioInfer三个数据集上,对实体类型识别、关系分类、关系抽取三个任务进行了实验,取得了比较好的结果。
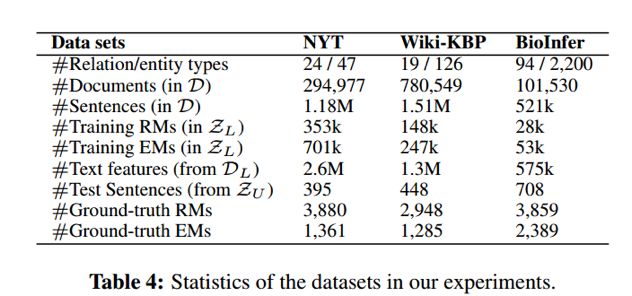
(1)数据集
(2)实验结果
总结
文本提出了一种领域无关的利用知识库通过远程监督方式进行关系抽取的模型框架,包括了一种领域无关的文本分割算法用于识别实体,一个联合嵌入目标函数用来形式化建模 mention-type之间的关联、mention-feature之间的共现关系、entity-relation 之间的交叉约束关系。
论文笔记整理:王狄烽,南京大学硕士,研究方向为知识图谱、知识获取。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。


