再品 Attention Is All You Need
Abstract
文本提出一个全新的特征提取器——Transformer,其完全摒弃了循环(recurrence)和卷积(convolutions)的结构,仅仅依赖attention机制就能在多个任务上达到SOTA的效果。
Model Architecture
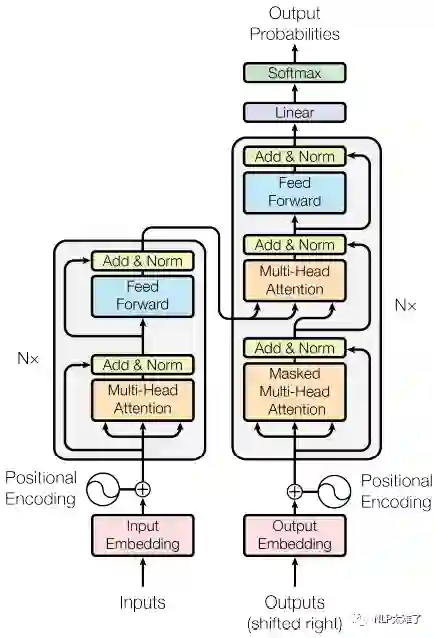
1. Encoder and Decoder Stacks
Encoder:
Encoder由6个相同的层堆叠而成,每个层又有两个子层:第一个子层是multi-head self-attention机制层,第二个子层是position-wise fully connected feed-forward network(FCFFN)。在每个子层,都应用了残差连接(residual connection),然后再加一个layer normalizatoin。
Decoder:
整体上和Encoder部分相同。不同之处是:
-
在第一个子层(multi-head self-attention)和第二个子层(position-wise FCFFN)之间,额外多了一个 multi-head self-attention层——将从Encoder传过来的结果进行multi-head attention操作,该层也叫作 Encoder-Decoder Attention。 -
修改了第一个子层的multi-head self-attention为 masked multi-head self-attention。这里 masking的作用是,让对位置 处的预测仅仅依赖于位置 处之前的输出(其实这里我也没有搞懂masking的作用是什么...)。
那么,Transformer的整体架构如图1所示:
2. Multi-Head Self-Attention
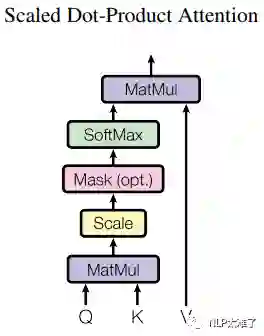
2.1 Scaled Dot-Product Attention
Scaled Dot-Product Attention一般翻译做"缩放点积attention"。我们假定query和key的维度都为 ,value的维度为 ,query、key和value均为向量。
一般,在attention机制中,我们使用一个query和一组key做点积(dot-product),然后再对该结果套用一个softmax得到一组权重(weights),将该权重应用到一组value之上,得到的就是我们的attention。
在本文中,Scaled Dot-Product Attention的做法基本上和上述相同,除了多了一个将query和key的点积结果除以 的操作,即**缩放(scaled)**操作。在实际使用中query有多个,为了能同时对这些query进行attention操作,将这些query拼成一个矩阵 。同理,由keys和values我们可以得到 和 。“缩放点积attention”过程可视化为图2所示。本文的Scaled Dot-Product Attention操作可以用公式描述成如下:
原文也解释了使用"缩放"操作的原因:当 很大时, 和 的点积结果会变得很大,其方差也会很大,这会让softmax函数的梯度变得异常的小,将点积结果除以 可以抵消这个影响。这是因为,我们可以把softmax公式写成:
softmax函数是在定义域上是可微的,那么对其求导,就得到梯度:
显然无论是 还是 时, 和 都会很大( 和 的点积结果很大),那么 都是负值且很小。
另外,原文中也探讨了additive attention和dot-product attention的异同。
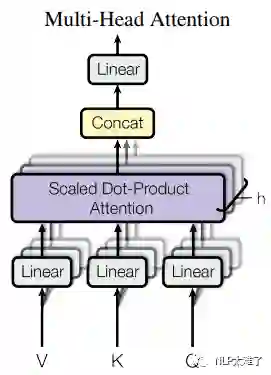
2.2 Multi-Head Attention
接下来我们阐述怎么在上面的“缩放点积attention”的基础上进行“多头attention”操作。
首先将Q、K和V进行 个不同的线性变换操作,得到
这里进行初始线性变换的Q, K, V的 和 的长度为原始值的 ,因为最后进行了一个concat操作。另外,需要注意的是,所谓Self-Attention,是因为Q,K,V均为相同的。
3. Position-wise FFN, Embedding and Softmax
3.1 Position-wise FFN
和其他所有的全连接层类似,这里的全连接包含了两次变化,使用的是ReLU激活函数。形式化描述如下公式:
3.2 Embedding and Softmax
作者使用了预训练的向量(learned embeddings)来表示输入和输出tokens,维度大小为 。在Decoder输出的最后,使用了一个线性映射变化和一个softmax来将输出转换为概率。此外,两个embeddings层和线性变化使用的都是同一个权重矩阵。
4. Positional Encoding
到目前为止,模型中并没有可以准确学习到序列位置信息的神经网络组件。为了能学习到序列中相对或者绝对的位置信息,实际上有两种选择:positional encoding和learned positional embedding。本文采取了前者。
在实际使用过程中,positional encoding的维度和embeddings的维度大小均设置为 ,然后会将两者相加(sum)。如图1中底部部分所示。作者对不同的频率应用sin和cos函数,公式如下:
其中, 即position,意为token在句中的位置,设句子长度为L,则 ; i 为向量的某一维度,例如 , 出处。
Positional Encoding的每一维对应一个正弦曲线,其波长形成一个从 到10000* 的等比级数。这样做的理由是,作者认为这样可以使模型更易学习到相对位置,因为对于某个任意确定的偏移值 , 可被表示为 的一个线性变换结果。
5. Training
在Transformer的训练过程中,也有一些很有意思的tricks,值得在这里提一提。
5.1 Warmup
本文在这里的做法是:先在模型初始训练的时候,把学习率设在一个很小的值,然后warmup到一个大学习率,后面再进行衰减。所以,刚开始是warmup的热身过程,是一个线性增大的过程,到后面才开始衰减。
5.2 Regularization
1). Residual Dropout
在前面已经叙述过,在每个网络子层处,都使用了残差连接;另外,前面没有提过的是,在Encoder和Decoder中将embeddings和positional encodings相加后的和也使用了dropout。
2). Label Smoothing
即标签平滑,目的是防止过拟合。论文中说,标签平滑虽会影响ppl(perplexity),但能提高模型的准确率和BLEU分数。
Conclusion
-
它本质上是一个seq2seq的结构,仅仅依赖self-attention,完全摒弃CNN和RNN; -
Encoder中包含两个子层,第一个子层是Multi-Head Self-Attention,第二个子层是一个全连接层; -
Decoder中包含三个子层,第一个子层是Masked Multi-Head Self-Attention,第二个子层是Encoder-Decoder Attention,第三个子层是一个全连接层; -
值得注意的是,上述的每个子层中,都用到了残差连接和Layer Normalizatoin;
Read More
这里推荐一些超棒的适合进阶的Transformer相关博文和知乎讨论:
博文:
-
碎碎念:Transformer的细枝末节( https://zhuanlan.zhihu.com/p/60821628) -
[整理] 聊聊 Transformer( https://zhuanlan.zhihu.com/p/47812375) -
《Attention is All You Need》浅读(简介+代码)( https://kexue.fm/archives/4765) -
香侬读 | Transformer中warm-up和LayerNorm的重要性探究( https://zhuanlan.zhihu.com/p/84614490)
知乎讨论:
-
为什么Transformer 需要进行 Multi-head Attention?( https://www.zhihu.com/question/341222779/answer/814111138) -
Transformer使用position encoding会影响输入embedding的原特征吗?( https://www.zhihu.com/question/350116316/answer/863151712) -
如何理解Transformer论文中的positional encoding,和三角函数有什么关系?( https://www.zhihu.com/question/347678607/answer/835053468) -
神经网络中 warmup 策略为什么有效;有什么理论解释么?( https://www.zhihu.com/question/338066667/answer/771252708)
Reference
Attention Is All You Need(https://arxiv.org/abs/1706.03762)
本文转载自公众号:NLP太难了,作者小占同学
推荐阅读
互联网新闻情感分析复赛top8(8/2745)解决方案及总结
清华THUNLP多标签分类论文笔记:基于类别属性的注意力机制解决标签不均衡和标签相似问题
Transformer详解《attention is all your need》论文笔记
AINLP-DBC GPU 云服务器租用平台建立,价格足够便宜
我们建了一个免费的知识星球:AINLP芝麻街,欢迎来玩,期待一个高质量的NLP问答社区
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。





