亚军团队:山有木兮
林有夕介绍到团队成员宁缺是竞赛圈最具实力冠军选手 ,唐静是竞赛圈最漂亮的女生。
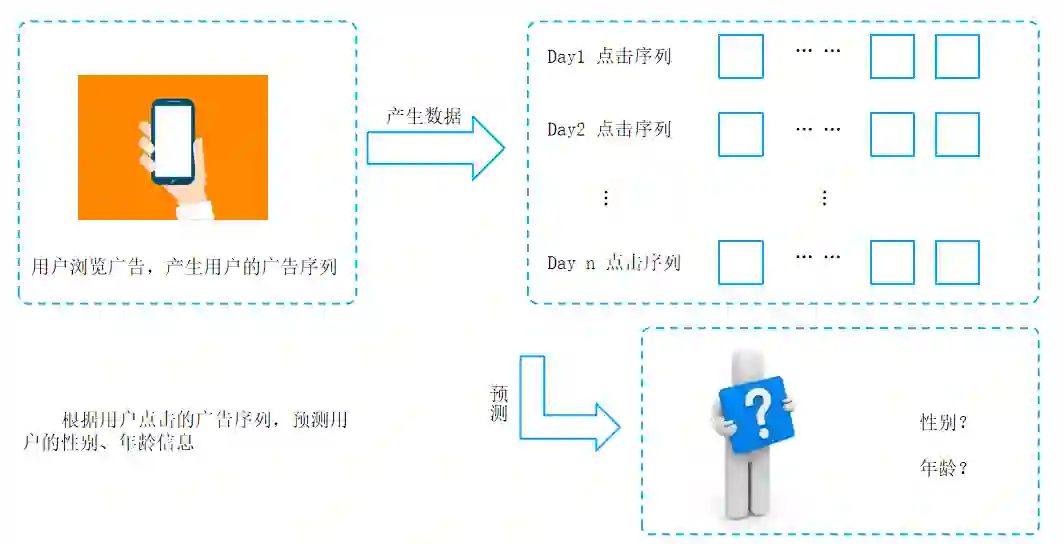
本届算法大赛的题目来源于一个重要且有趣的问题。众所周知,像用户年龄和性别这样的人口统计学特征是各类推荐系统的重要输入特征,其中自然也包括了广告平台。这背后的假设是,用户对广告的偏好会随着其年龄和性别的不同而有所区别。许多行业的实践者已经多次验证了这一假设。然而,大多数验证所采用的方式都是以人口统计学属性作为输入来产生推荐结果,然后离线或者在线地对比用与不用这些输入的情况下的推荐性能。本届大赛的题目尝试从另一个方向来验证这个假设,即以用户在广告系统中的交互行为作为输入来预测用户的人口统计学属性。
我们认为这一赛题的“逆向思考”本身具有其研究价值和趣味性,此外也有实用价值和挑战性。例如,对于缺乏用户信息的实践者来说,基于其自有系统的数据来推断用户属性,可以帮助其在更广的人群上实现智能定向或者受众保护。与此同时,参赛者需要综合运用机器学习领域的各种技术来实现更准确的预估。
在比赛期间,主办方将为参赛者提供一组用户在长度为 91 天(3 个月)的时间窗口内的广告点击历史记录作为训练数据集。每条记录中包含了日期(从 1 到 91)、用户信息(年龄,性别),被点击的广告的信息(素材 id、广告 id、产品 id、产品类目 id、广告主id、广告主行业 id 等),以及该用户当天点击该广告的次数。测试数据集将会是另一组用户的广告点击历史记录。
提供给参赛者的测试数据集中不会包含这些用户的年龄和性别信息。本赛题要求参赛者预测测试数据集中出现的用户的年龄和性别,并以约定的格式提交预测结果。
大赛会根据参赛者提交的结果计算预测的准确率(accuracy)。年龄预测和性别预测将分别评估准确率,两者之和将被用作参赛者的打分。
测试数据集会和训练数据集一起提供给参赛者。大赛会将测试数据集中出现的用户划分为两组,具体的划分方式对参赛者不可见。其中一组用户将被用于初赛和复赛阶段除最后一天之外的排行榜打分计算,另一组则用于初赛和复赛阶段最后一天的排行榜打分计算,以及最后的胜出队伍选择。
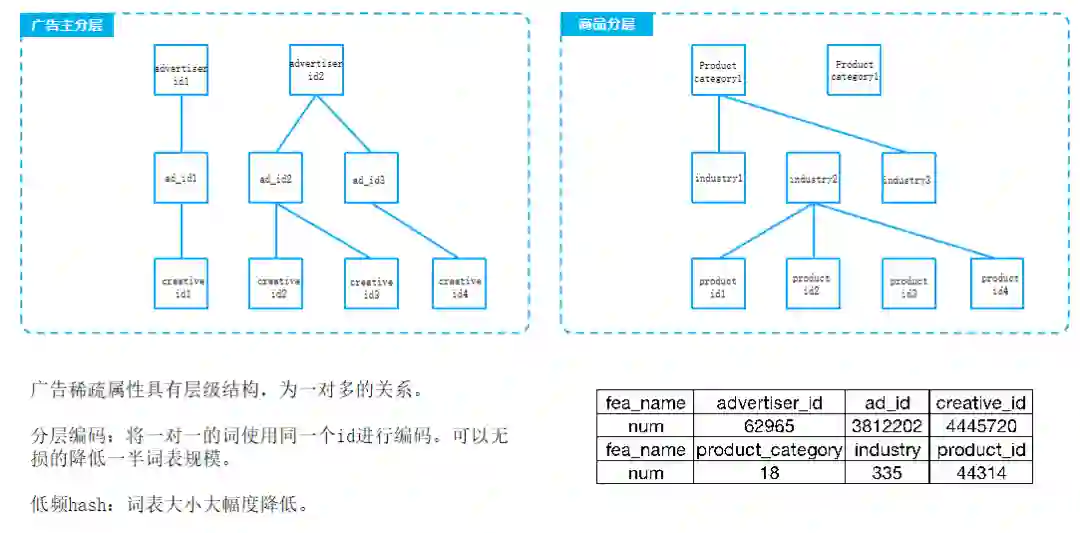
对所有的creative 进行编码。如果该广告主仅有一个adid ,则该adid 使用广告主id,如果有多个,则保留adid编码。以此类推。只有多对一关系的下级编码才会获得新的编码。
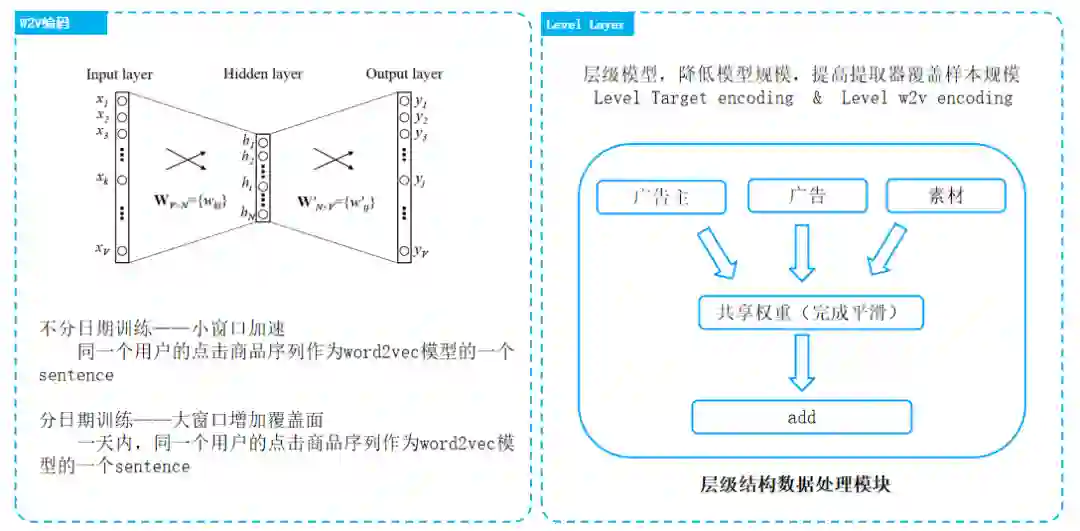
该编码可以对于层级数据具有良好的词表压缩能力。且保持信息0损失。(原理类似于分词)
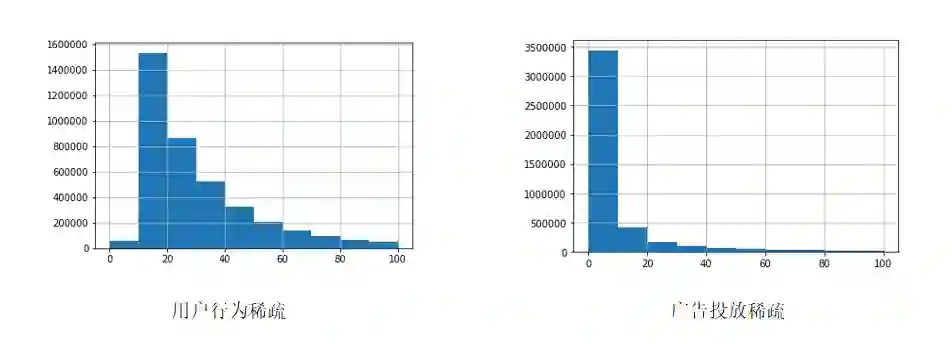
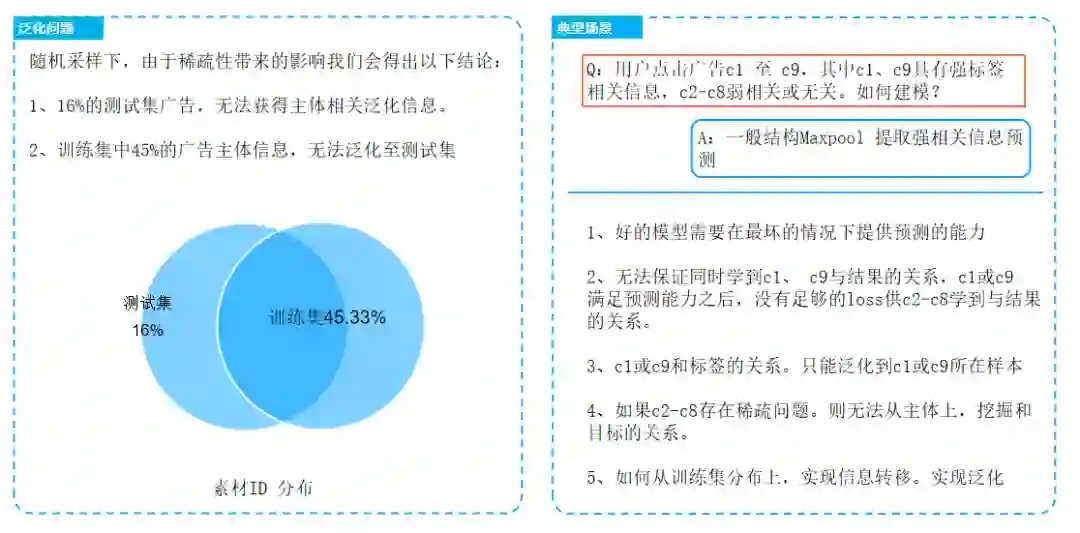
id长尾特性+为现实意义明确的实体的场景下:相似度流派完胜统计流派,id为现实意义明确的实体时,往往具有很丰富的信息,在分布较为稀疏时,往往基于低频特征无法很好的学习到id的具体信息。所以需要稠密化转化。
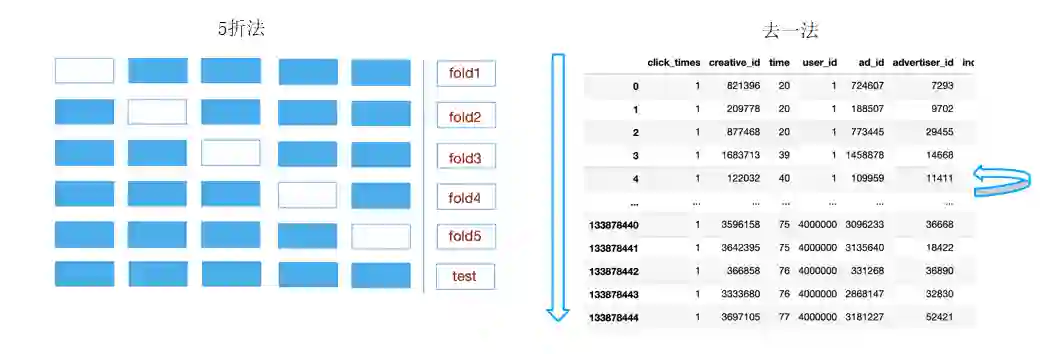
最直接的做法:构建标签预测解,由模型实现平滑,并结合特征矫正。Kfold:将样本划分为k份,对于其中每一份数据,我们都用另外k-1份数据提取标签分布特征,复杂度K * On;去一法:统计全局概率分布,去除当前行样本复杂度On
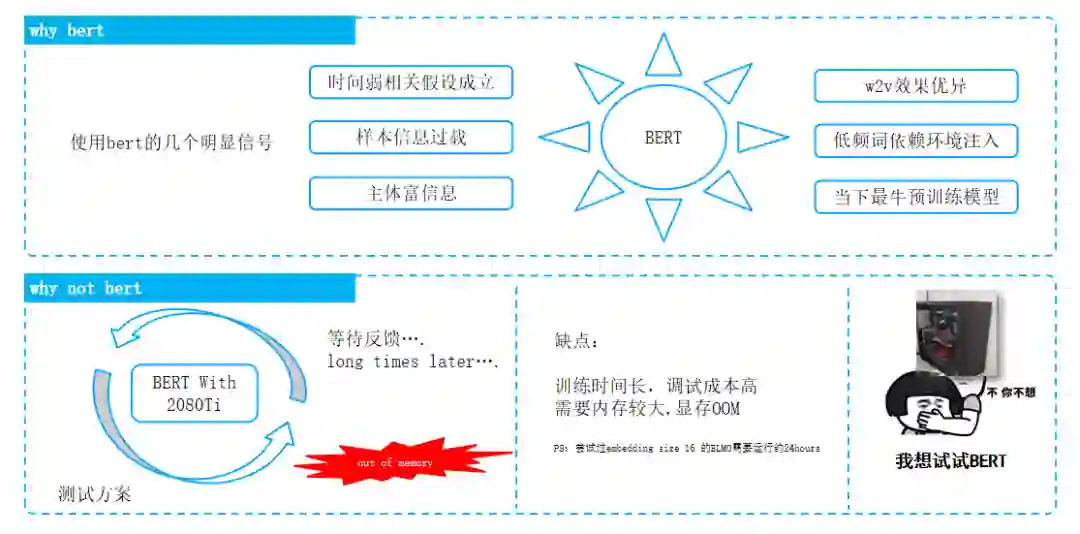
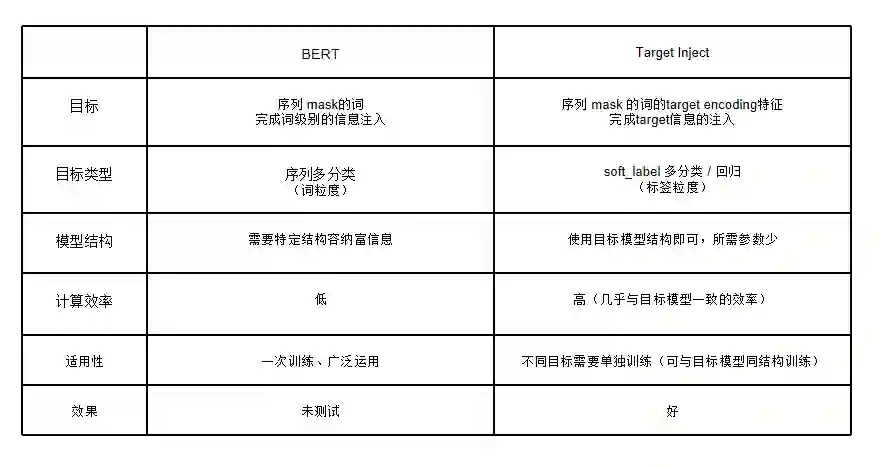
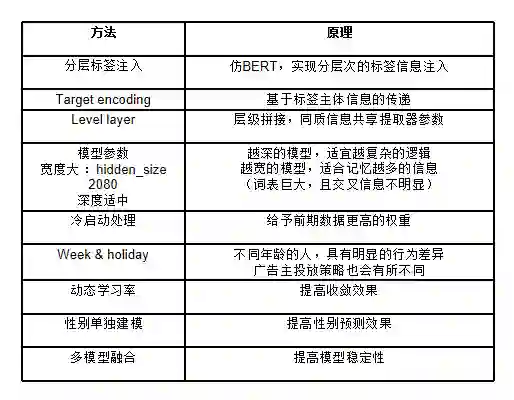
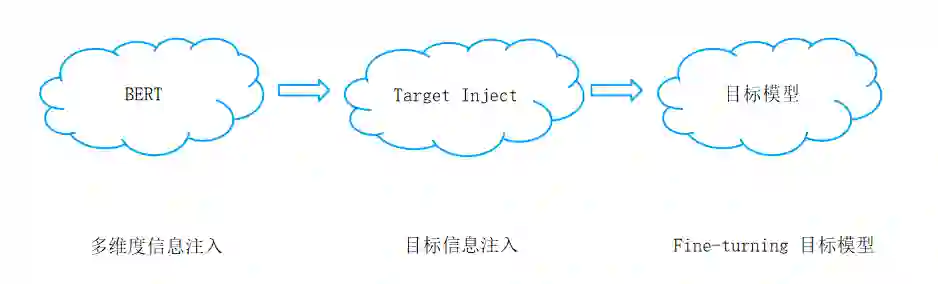
BERT 可以实现将词级别的完整信息注入,理想情况下可获得单个词的丰富的多维度信息,而针对当前场景,是否可以实现一种只将target 紧密相关的信息注入的方法?从而大幅度降低模型规模。
具体,把需要的信息注入就可以了。全空间不见得好。目标就预测个性别、年龄,看来自己造个针对这个数据集的玩法了,并计划取名为Focus\target bert。
模型可以不切换状态连续训练,经测试发现,在标签预测阶段,学习率降低50倍,效果明显,具有fine-turning的特性。
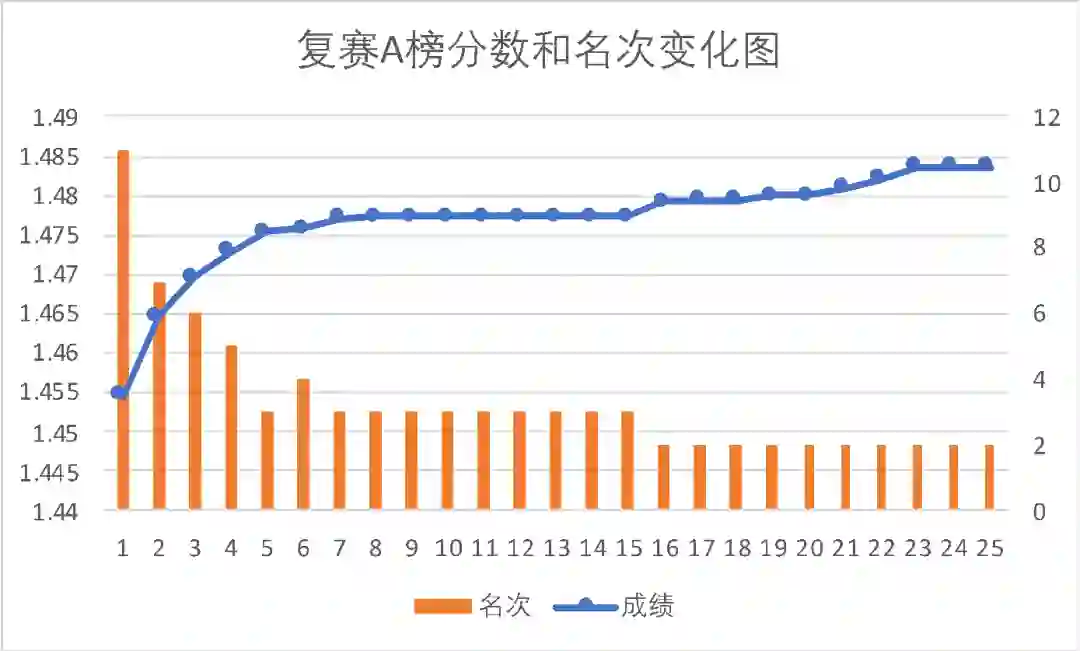
1、复赛正式参与比赛,从160名左右,一周内进入前三
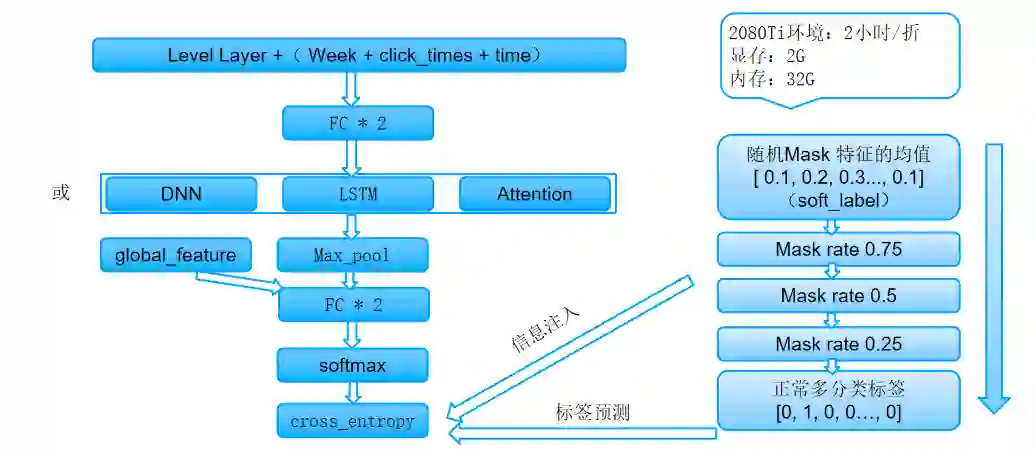
1、对序列进行采样或计算加权,越往前的广告具有越大的权重。
2、序列翻转后入LSTM模块,输出并使用last_output特征。
启示一:
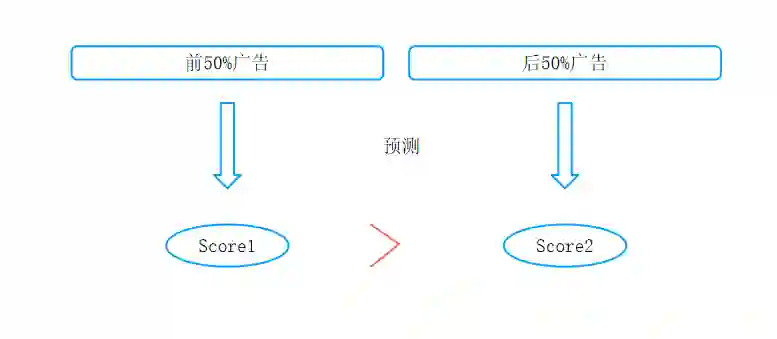
前期用户点击行为较少,所以按照用户基础属性进行推荐。后期用户具有点击行为后,按照行为进行推荐,如果基础属性未包含标签,则说明基础属性之间具有更高的关联性
启示二:
如果前期广告依赖标签进行推荐,则形成了信息穿越。该样本不能用来建模。
1、在信息损失等较坏情况下具有良好预测能力。每条样本都应为此付出贡献。
2、特征或特征之间应该具有相互备份容灾的能力,具有丢失情况下的恢复能力。这个过程中形成的
相互记忆的中间态,具有
桥梁的作用,具有更强的泛化能力。
1、稀疏实体富信息现象,容易形成信息孤岛、空岛。如何将此类信息拆解分发或者注入。
是接下来研究的重点。
从而实现由记忆到泛化的转变。
![]()
进群请添加AINLP小助手微信 AINLPer(id: ainlper),备注竞赛
![]()
推荐阅读
这个NLP工具,玩得根本停不下来
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
从数据到模型,你可能需要1篇详实的pytorch踩坑指南
如何让Bert在finetune小数据集时更“稳”一点
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
Node2Vec 论文+代码笔记
模型压缩实践收尾篇——模型蒸馏以及其他一些技巧实践小结
中文命名实体识别工具(NER)哪家强?
学自然语言处理,其实更应该学好英语
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。
![]()
阅读至此了,分享、点赞、在看三选一吧🙏