【比赛冠军方案开源】真实场景下身份证复印件OCR信息抽取
【导读】身份证影像文件包含姓名、地址等多项个人基本信息,信息准确度和权威性高,在商业银行中被广泛应用于身份认证、信息采集等领域。然而,商业银行的影像数据来源渠道复杂,时间跨度很大,质量层次不齐,目前市面上的身份证识别模型尚不能满足银行质量参差的影像识别需求。因此,一个具备强抗噪声干扰能力的OCR模型有着极高的商业价值。
赛题简介
赛题名称:《基于OCR的身份证要素提取》
出题单位:兴业银行
赛题奖金:¥10万
技术方向:分类预测, 数据挖掘
赛题背景:市面上的身份证识别模型,尚不能满足银行质量参差的影像识别需求,一个具备强抗噪声干扰能力的OCR模型有着极高的商业价值。
任务描述:根据训练数据,设计针对商业银行身份证识别的OCR系统,识别身份证中姓名、地址、身份证号码和身份证有效日期等信息。
冠军队伍:“鹏脱单攻略队”,后改名为“天晨破晓”
团队成绩:
2019CCF-BDCI大赛 最佳创新探索奖
"基于OCR的身份证要素提取"单赛题冠军
准确率:0.996952
开源方案地址:
https://github.com/Mingtzge/2019-CCF-BDCI-OCR-MCZJ-OCR-IdentificationIDElement

本赛题的任务是准确识别出身份证中包含姓名、出生日期、地址、签发机关等在内的多个关键信息,然而赛题所提供的训练集数据中,图像在亮度、清晰度等方面差别很大,初赛和复赛分别添加不同样式的水印。上述内容都对关键信息的提取带来了巨大的挑战。
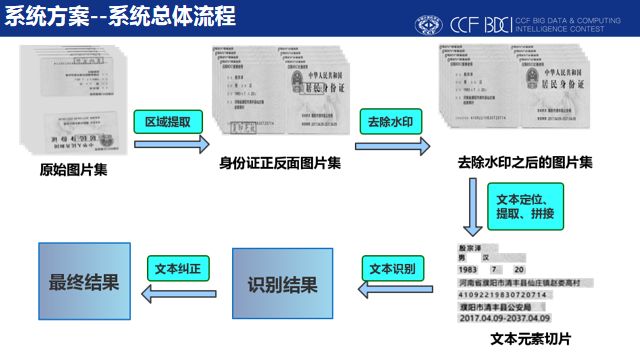
我们的系统采取了将传统计算机视觉算法与深度学习方法相结合的方案,通过模板匹配、腐蚀膨胀、二值化等传统的方法,从原始不规则的数据集中得到规则身份证图片的切片,简单快速,效果出色。接着规则的身份证图片输入到去水印模块中,去除水印带来的干扰。然后将处理后的图像输入到文本识别模块中,对各个文本元素进行识别。为了进一步提高识别的准确率,最后将识别的结果输入到文本纠正模块中,对识别出错的文本信息根据事先设定的规则进行最大程度上的纠正,输出最终识别的结果。
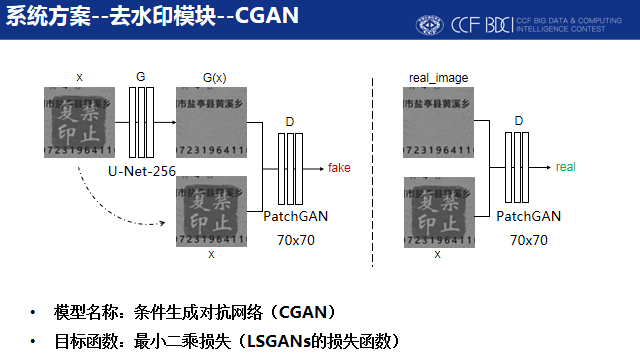
去除水印的过程在一定程度上可以看做是图像恢复的工作,而生成对抗网络能够有效处理这类任务。我们采用条件生成对抗网络来完成去除水印的工作,生成器输入带水印的图片,生成去除水印之后的图片,判别器对生成不带水印的图像和真实不带水印的图像进行真伪的判别,输入原始带水印的图像作为条件约束,通过判别器和生成器之间的对抗训练,提高生成器的能力,改善去除水印的效果。

最终去水印的效果如图所示,可以看到我们的去水印模块在不同亮度、模糊程度、透明度的图像上都有非常出色的表现。即使一些图片人眼无法识别出被遮挡的文字内容,我们的模型也依然能够很大程度上恢复出被遮挡的信息,大大减小了文本识别的难度。
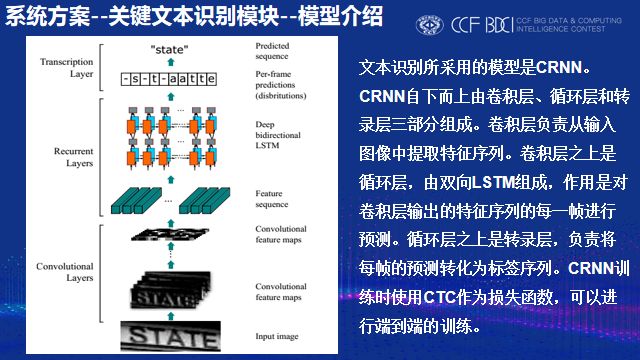
文本识别的模型采用的是CRNN。我们的识别模型可以识别6030个字符(包含汉字、部分标点、阿拉伯数字),由于训练出一个鲁棒的模型需要大量数据,因此训练过程中使用了生成图片用于训练,同时在训练过程中随机调整图片亮度、对比度,达到数据增强的效果。
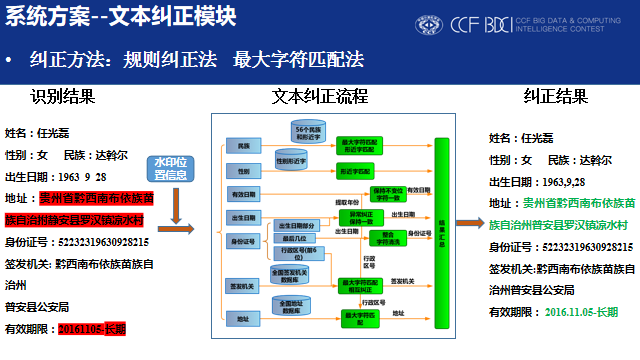
身份证上很多信息都有着明确的组成格式要求,如果能够充分利用这些先验条件,即使一些文本识别出错,我们也能够将其纠正,得到正确的结果。我们的文本纠正模块采用了规则纠正法和最大字符匹配法,规则纠正法利用了身份证中不同关键信息的冗余,比如身份证号码中包含出生年月日信息,前六位包含省市县三级行政区域的信息,可以用来与住址,签发机关相互纠正;
民族信息使用相近字来纠正,在这个纠正过程中,我们搜集了全国的行政区号,签发机关,具体地址信息(具体到村级),用于辅助纠正。而对于性别和民族的识别结果,则通过最大字符匹配法进行纠正。

我们提出的文本识别方案识别准确率高,各个模块之前相对独立,灵活性好,即使更换不同的文本识别场景,依然能够快速部署,完成相关的识别任务。此外,我们的方案抗干扰的能力好,训练的方法通用,更换其他样式的水印干扰,水印去除模块也能够有效完成去干扰的工作。如果使用更出色的去模糊方法,文本识别的准确率还能有望得到进一步的提高。


点击“阅读原文”,了解使用专知,查看5000+AI主题知识资料



