法研杯2019阅读理解赛道冠军方案分享(含PPT)

2019年8月17日,由中国中文信息学会社会媒体处理专委会、中国司法大数据研究院等单位主办,科大讯飞股份有限公司、哈尔滨工业大学等机构联合承办的第八届全国社会媒体处理大会 “中国法研杯” 司法人工智能挑战赛之中文法律阅读比赛(SMP-CJRC 2019)在深圳落下帷幕,赛博智能团队的田雨、李欣隆联合北航的张士卫、丁龙翔组成的团队在比赛中获得了第一名的好成绩。
本文首先对赛题进行回顾,然后介绍了团队的获奖方案,最后分享了竞赛答辩PPT。

法研杯 | 图源 : cail.cipsc.org.cn/

团队介绍

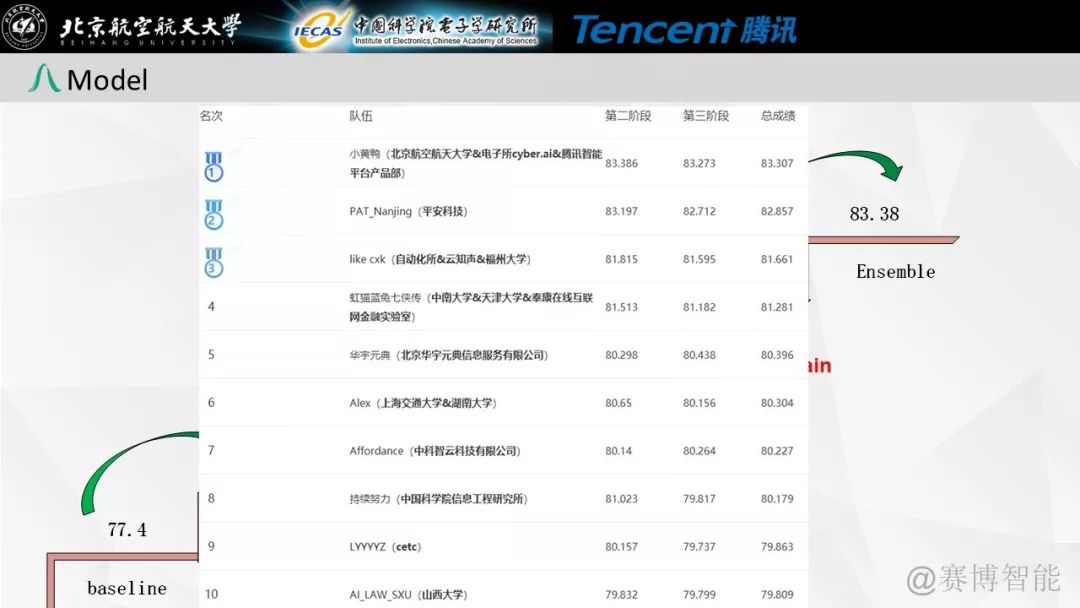
本团队由中科院电子所赛博智能团队的田雨、李欣隆同学,以及北航的张士卫、丁龙翔同学组成。队名是小黄鸭,参与了阅读理解赛道,并在总决赛中获得冠军。

竞赛排名 | 图源 : cail.cipsc.org.cn/
赛题背景
机器阅读理解(Machine Reading Comprehension)是近期自然语言处理领域的研究热点之一,也是人工智能在处理和理解人类语言进程中的一个长期目标。它是指让机器阅读文本,然后回答和阅读内容相关的问题。阅读理解是自然语言处理和人工智能领域的重要前沿课题,对于提升机器智能水平、使机器具有持续知识获取能力具有重要价值,近年来受到学术界和工业界的广泛关注。
赛题描述
裁判文书中包含了丰富的案件信息,比如时间、地点、人物关系等等,通过机器智能化地阅读理解裁判文书,可以更快速、便捷地辅助法官、律师以及普通大众获取所需信息。
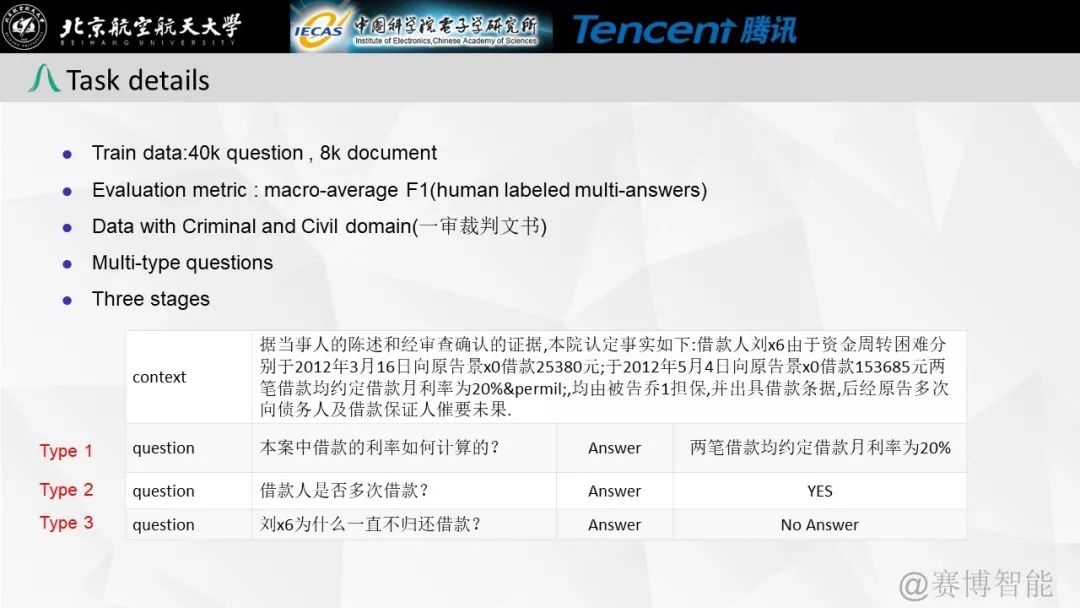
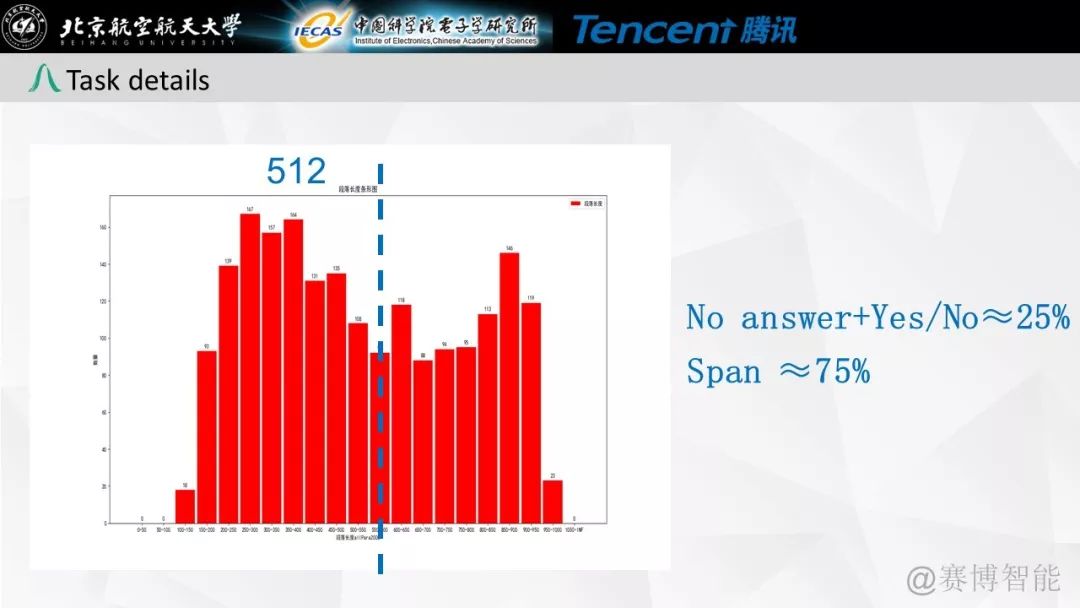
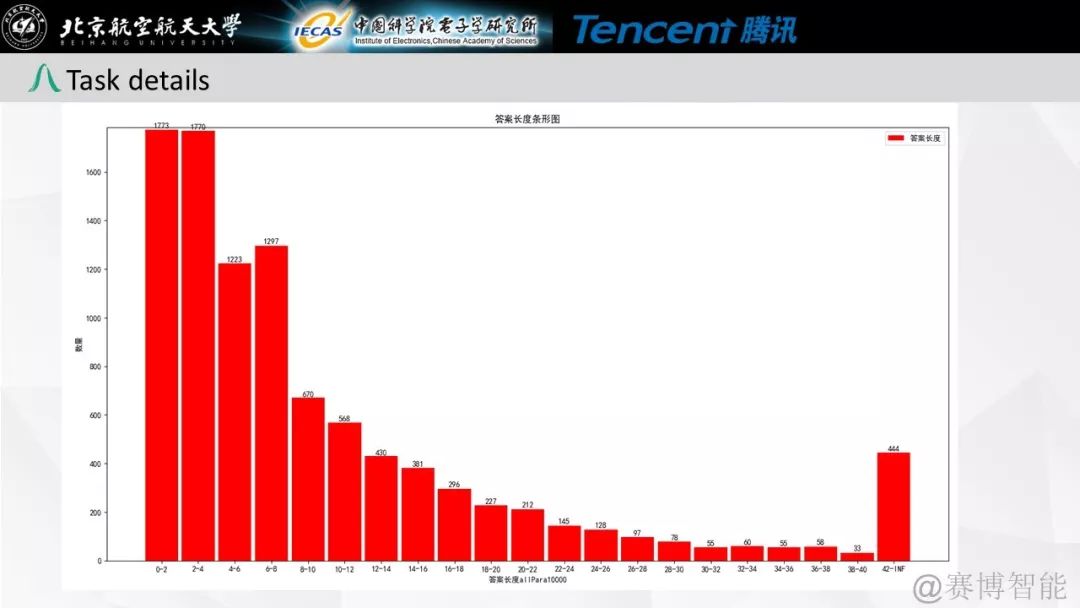
本任务是首次基于中文裁判文书的阅读理解比赛,属于篇章片段抽取型阅读理解比赛(Span-Extraction Machine Reading Comprehension)。为了增加问题的多样性,参考英文阅读理解比赛SQuAD和CoQA,本比赛增加了拒答以及是否类(YES/NO)问题。
本任务采用与CoQA比赛一致的宏平均(macro-average F1)进行评估。对于每个问题,需要与N个标准回答计算得到N个F1,并取最大值作为其F1值。
模型介绍
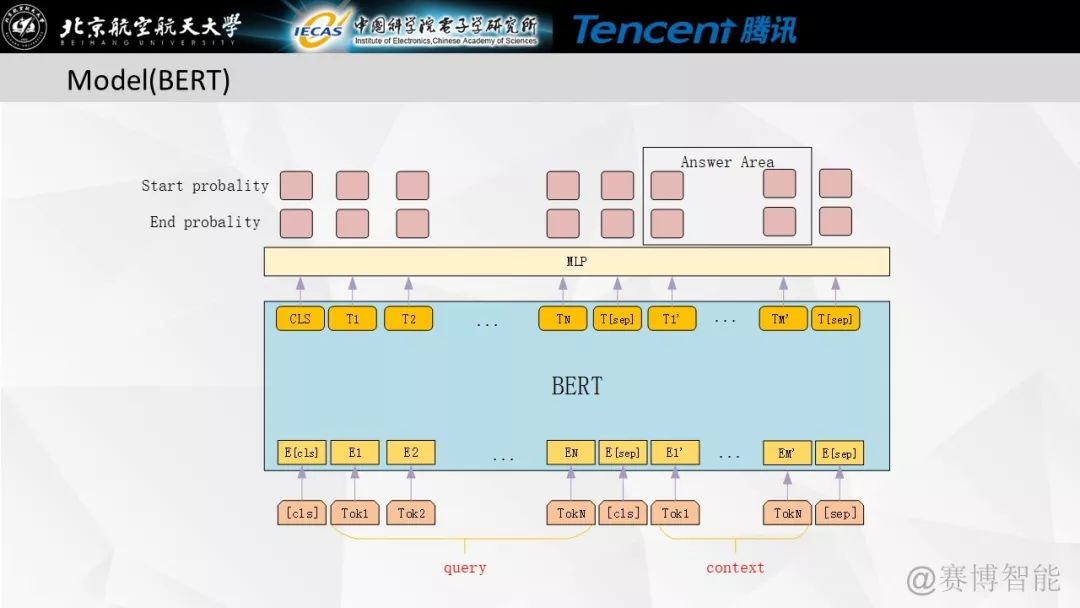
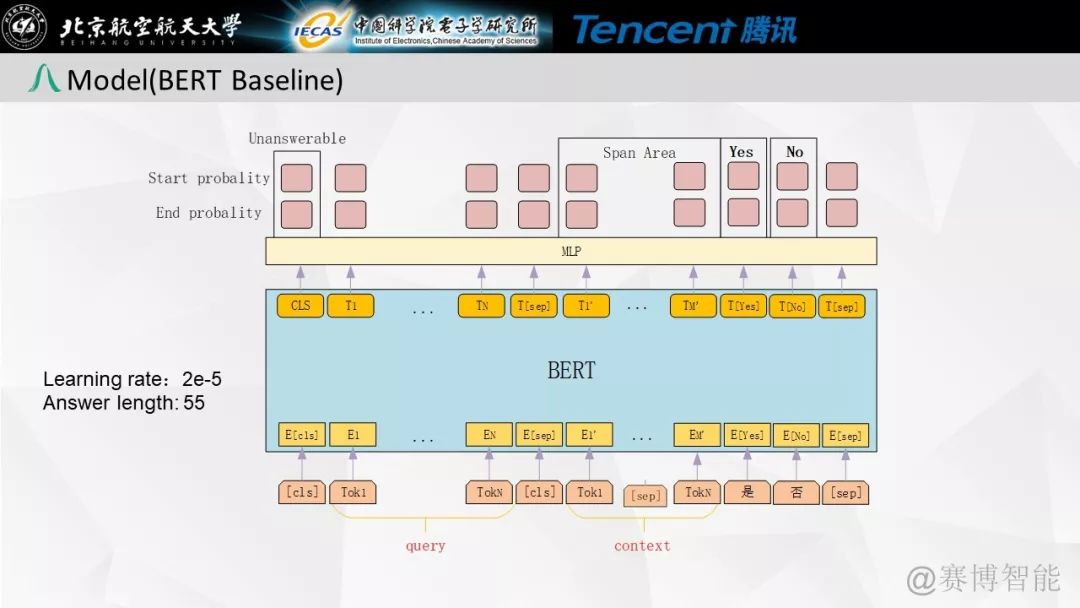
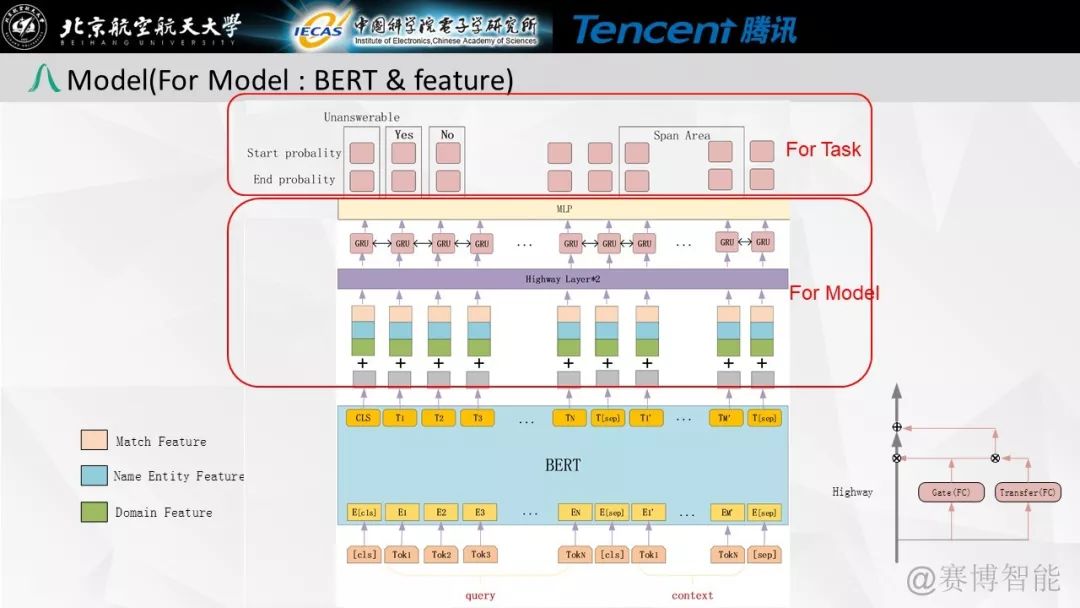
我们的模型结构如下图所示,设计该网络的核心就是将google的bert输出接上词性等特征加上一层传统的highway与GRU后通过MLP来判断答案的label与Span的位置。
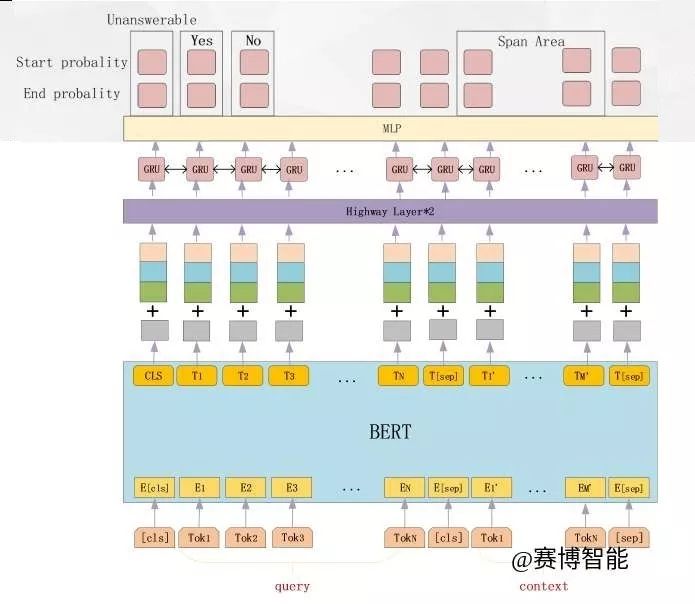
模型整体结构图
我们将整个模型中较为有效的策略概括为以下几点:
1
bert模型的fine-tune
由于本任务是司法相关的阅读理解任务,在google发布的bert-base-chinese上,针对本次任务,基于全部民事文书和刑事文书,以及去年的法研杯数据对原预训练模型重新进行了fine-tune。使其更加适合于该阅读理解任务。相对于原google发布的模型,效果有很大的提升。
2
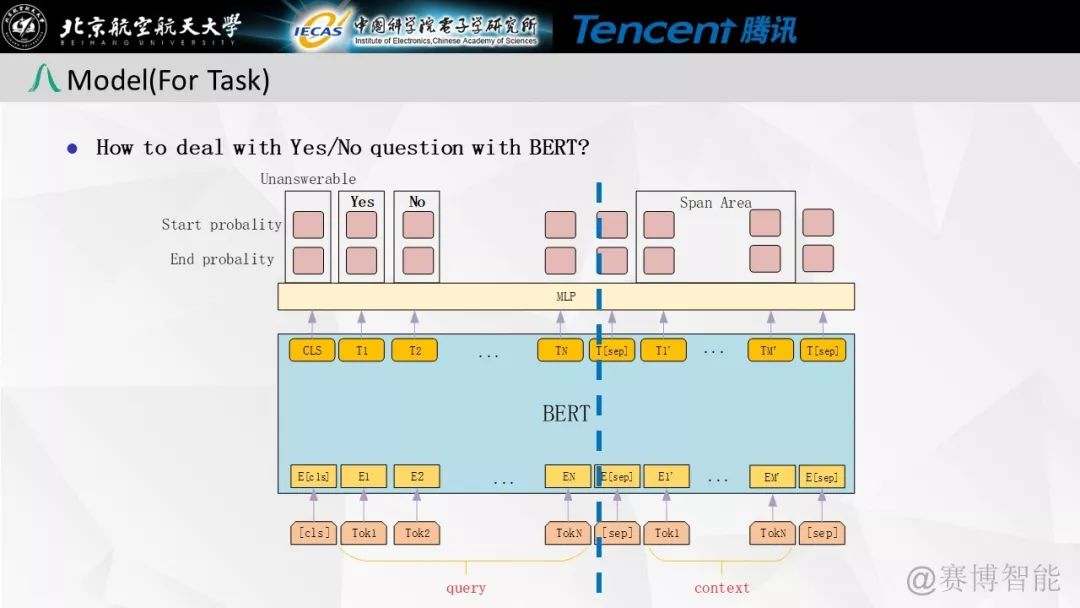
是否类问题的解决方案
由于是否类问题在原文中找不到正确答案,按照原来的抽取式阅读理解的方式来寻找答案相关段落以及答案位置是不可取的。团队的策略是通过tf-idf方式,对比原问题与段落中的每一句来寻找答案相关段落,从而对模型进行训练。提供了一种可取的是否类问题解决方案。
3
数据增强方案
在不可回答问题上,通过命名实体识别来替换其中的人名,地名来增加负向问题数据量。并通过交换问题位置来增加负向问题数据量。
在可回答问题上,通过神经网络模型,获取更多的正向问题。
4
阈值调整
在竞赛中,通过调整是否可回答的阈值解决不平衡数据集的问题。
后续展望
比赛的时间总是不够用的,我们认为模型仍有很大的提升空间。未来,我们会尝试从以下几个方面入手:
1
是否类问题的解决
传统的tf-idf方法虽然有效,但仍然不是最优解,我们会继续研究如何更有效的解决是否类问题。
2
命名实体上的缺陷
当前命名实体识别技术仍不能高效准确的抽取到所有相关实体,导致在数据增强以及多维特征上仍有很大问题。
3
数据可否回答的判断问题
经验证,使用verfiy机制对问题的可否回答进行进一步判断,可以得到很大的提升。我们会尝试将verfiy机制融入模型中,测试其效果。
4
预训练模型问题
本次比赛只使用了最简单的base版bert模型,没有尝试Ernie以及wwm版的bert模型,未来我们会进一步的探索。
答辩PPT分享
最后,分享竞赛答辩的PPT,方便大家交流。


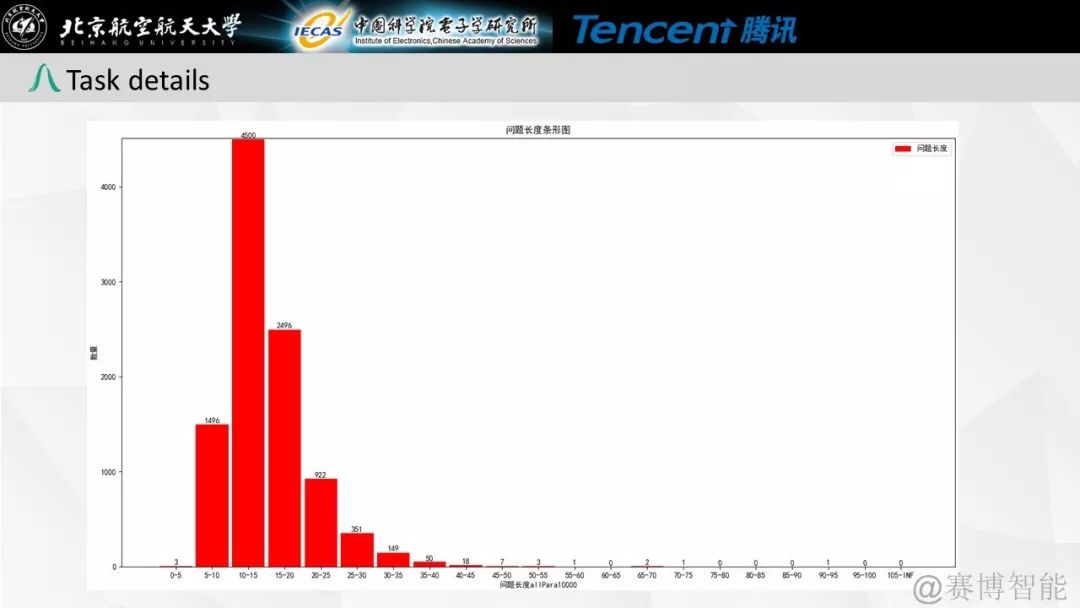







作者简介
田雨,直博生,2018年由大连海事大学保送至中国科学院大学。研究方向为关系抽取与阅读理解。
作者:田大雨
编辑:田大雨

本文转自公众号“赛博智能”,点击阅读原文直达原文链接。





