搜狐图文匹配算法大赛_方案分享

向AI转型的程序员都关注了这个号👇👇👇
大数据挖掘DT数据分析 公众号: datadw
参加这次比赛的初衷是作为机器学习课程的大作业,这两天写了课程报告,所以将报告内容修改了一下进行分享。
我所在的团队(“中国国家跳水队”,排名如队名,一度严重跳水)获得了初赛第3, 复赛第9, 决赛第6的成绩,正好擦边获得了三等奖。(小编:比赛的时候取个好名字有多重要:)
主要分为三个部分,分别为比赛背景介绍,团队主要方案介绍,其他方案介绍。其中最后一部分包含了一些其他队伍在决赛赛后分享时提到的思路。
比赛背景介绍
此部分主要内容摘自比赛官网,详细内容见比赛官网
https://biendata.com/competition/luckydata/
主要任务
参赛队伍利用组委会给定的搜狐新闻文本内容和相应的新闻配图等数据集来训练模型(数据集规模为10万条新闻和10万张新闻配图)。比赛要求在给定新的新闻内容集合和新的图片集合之后(数据集规模为2万条新闻和2万张新闻配图),参赛队伍能为每一篇新闻找到匹配度最高的10张图片,并且给出相应的排序。在复赛时,训练数据集的规模提高到了125w。
测评方案
根据参赛队伍提供的答案,计算每条数据i的ndcg值ndcg(i),得分为
思路分析
拿到这个问题,第一个思路就是设计一个模型来衡量文本和图像之间的相似度。所以我们认为需要分别将文本和图片进行编码,获得相同长度的向量表示,然后再用某种距离度量来衡量两者之间的相似性。在我们的方案中,选择了余弦距离来衡量向量之前的相似度,效果要比欧式距离好。我们的方案思路示意图如下图所示。
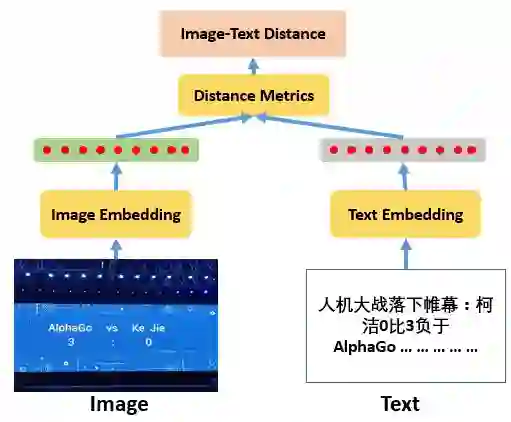
文本编码
首先是文本编码模型,经过分析我们认为文本编码模型的重点包括如下几点:
文本向量能有效代表文本内容
文本向量之间的距离要有区分度
文本向量不要太长,以节省后续的存储空间以及计算开销
因此,经过很多不同方法的尝试,最终我们选择了非常简单的一个方案,如下图所示。首先使用中文分词工具对文本进行分词,然后在训练集上训练tf-idf(一种加权词袋模型),将文本转为稀疏的向量表示,最后使用PCA模型对文本向量进行降维,得到一个1000维的文本向量。
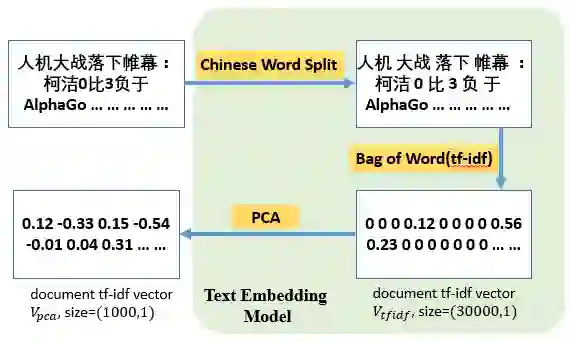
图像编码
图像编码我们也选择了很简单的方案,使用了VGGnet加上一层额外的全连接层,使得输入为一张图片(224*224),输出为一个1000维的图像向量。

模型训练
那么为了使得对应的文本和图片向量有较小的距离,我们对图像编码模型,即VGGnet进行了训练。训练使用的label即图片所对应文本的文本向量,训练使用的loss function为 1-cos.
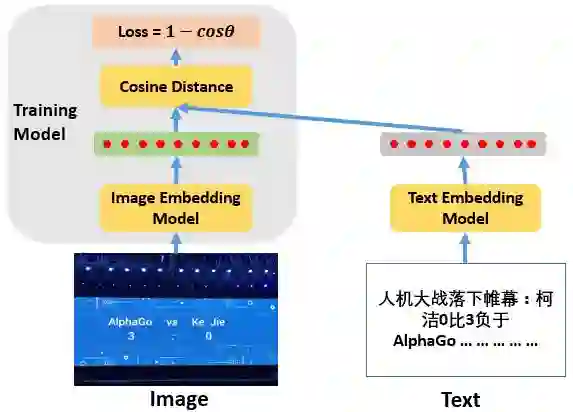
模型预测
在测试集上进行结果预测时,使用文本编码模型对所有文本进行编码,使用图像编码模型对所有图片进行编码。分别得到
实现
具体的代码因为写的比较乱,就不放出来了,思路其实也比较简单。我们的代码全部都是用python写的。文本分词使用了jieba工具库,词袋和PCA等使用了sklearn的相关函数。图像编码模型使用tensorflow1.0实现。
其他方案
上述的方案在初赛表现很不错,获得了第三名的成绩,但到了复赛后效果就变差了,最终只达到了第九名。决赛时我们还添加了OCR算法作为上述模型结果的补充
OCR
使用OCR的出发点是很多新闻的配图都包含与新闻文本内容相关的文字,所以使用OCR识别并进行匹配可以对这部分新闻进行图片匹配。我们使用了Google的Tesseract来进行中文OCR的识别。该模型的精度实在是比较一般。最后达到的分数大概只有商业OCR识别的一半不到。但比赛要求使用开源代码,所以我们就使用了Tesseract。因此,我们在决赛时使用的是OCR匹配加上上述图文模型的融合模型。
对于OCR,其他组有不同的做法,记得有一个组是先训练了一个文本检测器,即先检测文本在图片中的位置,再进行OCR识别,效果就好了很多。
不同的文本编码方案
图片编码方面,大家基本都很一致,就是使用CNN网络进行特征提取,使用的网络包括VGG和Inception等。文本编码方面就有不少不同的方案,有直接使用tf-idf向量作为本文向量的,也有先对文本提取关键词,然后进行Fisher Vector编码的(具体细节也记不清了..),还有使用LDA模型的。
本文来自 微信公众号 datadw 【大数据挖掘DT数据分析】
推荐系统方案
这个方案很有意思,前面有好几组使用了类似的方案,而我们组从头到尾都没想到过这个方案。。。以下对这个思路进行介绍,由于我也没有实现过,所以可能细节会有出入。
该方案的编码方式与别的方式类似,也是文本编码得到文本向量,图片编码得到图片向量(预训练网络)。在进行测试时,对于一个测试集文本向量,将它与训练集中的所有文本进行距离计算,找到最相似的K个训练集文本,然后就可以得到对应的K个训练集图片向量,再将所有测试集图片向量与这K个训练集图片向量衡量相似度,就可以找到该测试集文本最匹配的10张测试集图片。
这个思路在决赛上的表现很好,而且应该是训练集越大效果越好(复赛提供了125w的训练数据)。该方法的主要瓶颈在于计算量很大,需要高效的进行索引和匹配,记得有一组将该方法从20小时(Python)优化到了70分钟(C++)。也是非常厉害啊。
总结
最后吐槽一下我认为比赛里一些不太合理的地方,首先是 ”专门为某条新闻制作的包含大量文本的配图” 我认为是不应该包含在图文匹配的数据集合里的,因为在用实际场景中使用算法进行新闻图文匹配时,逻辑上文本和图片都是预先存在的。其次是复赛时官方提供的数据集有点太大了,125w的图片-文本数据集对计算资源的要求过高。。复赛后面我们也只能随机抽取一个子集来进行模型训练。
当然此次比赛收获还是很多的,主要是对文本处理和编码的一些基本做法有了一定的认识,也认识了一些朋友。比赛本身的任务也是非常有趣也非常困难的问题,与VQA和Image Captioning都有点相似,希望之后能看到相关的学术工作~
via http://blog.csdn.net/wzmsltw/article/details/73330439
人工智能大数据与深度学习
搜索添加微信公众号:weic2c

长按图片,识别二维码,点关注
大数据挖掘DT数据分析
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注




