用深度神经网络(DNN)修复受损的古希腊铭文,DeepMind 探索 AI 与古文字学的融合。
人类文字的诞生标志着历史的曙光,对于我们了解过去的文明和今天生活的世界至关重要。例如,2500 多年前,古希腊人开始在石头、陶器和金属上书写,记录下了包括租约、法律、日历、神谕在内的所有内容,从而令后人详细了解地中海地区。遗憾的是,这种记录是不完整的。
几个世纪以来,许多遗留下来的铭文已被损坏或从原来的位置移走。同时,放射性碳测年法等现代测年技术不能用于这些材料,导致解释铭文变得困难且耗时。
DeepMind 一直探索如何利用 AI 修复古老的语言。2019 年 10 月,DeepMind 联合牛津大学共同打造了 AI 工具 Pythia,它可以通过训练神经网络来修复古希腊铭文中缺失的字符或单词。
今日,在最新一期 Nature 封面文章中,DeepMind 联合威尼斯大学人类学系、牛津大学经典学院的研究者,探索利用机器学习来帮助历史学家更好地解释这些铭文,从而让人们更深入地了解古代历史,并释放 AI 和历史学家之间合作的潜力。
他们提出了首个可以恢复受损铭文缺失文本、识别原始位置并帮助确定创建日期的深度神经网络 —— Ithaca,它是以荷马史诗《奥德赛》中的希腊伊萨卡岛命名,在之前的 Pythia 工具上构建并进行了扩展。
![]()
研究结果表明,当单独使用时,Ithaca 在恢复受损铭文文本方面的准确率达到了 62%。相比之下,参与的历史学家的准确率为 25%,不过他们使用 Ithaca 可以将这一数字提升到 72%。
同时,Ithaca 在识别铭文原始位置方面的准确率达到了 71%,鉴定它们的年代只与真实日期范围相差不到 30 年。历史学家已经使用 Ithaca 重新评估了希腊历史上的重要时期。
此外,为了让广大研究人员、教育工作者、博物馆职员及其他人使用他们的研究成果,DeepMind 与谷歌云、谷歌艺术与文化合作推出了 Ithaca 的免费交互版本。并且,DeepMind 还开源了代码、预训练模型和交互 Colab 笔记本。
![]()
Ithaca 交互版本:https://ithaca.deepmind.com/
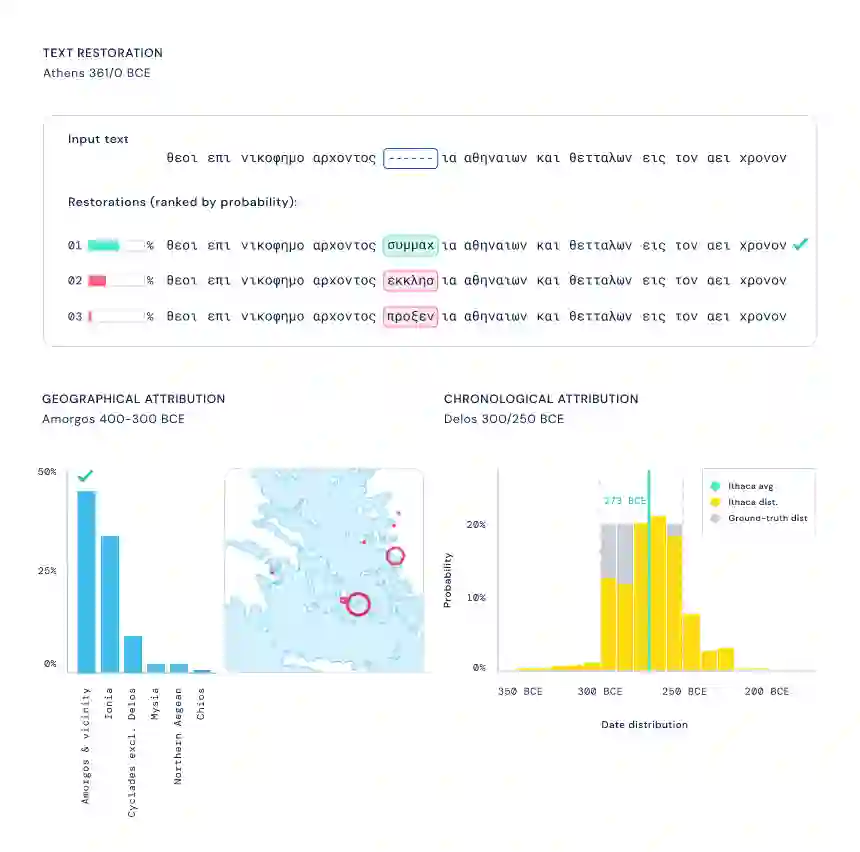
下图 1 中修复的铭文(IG I3 4B)记录了一项关于雅典卫城(Acropolis of Athens)的法令,日期为公元前 485/4 年。
![]()
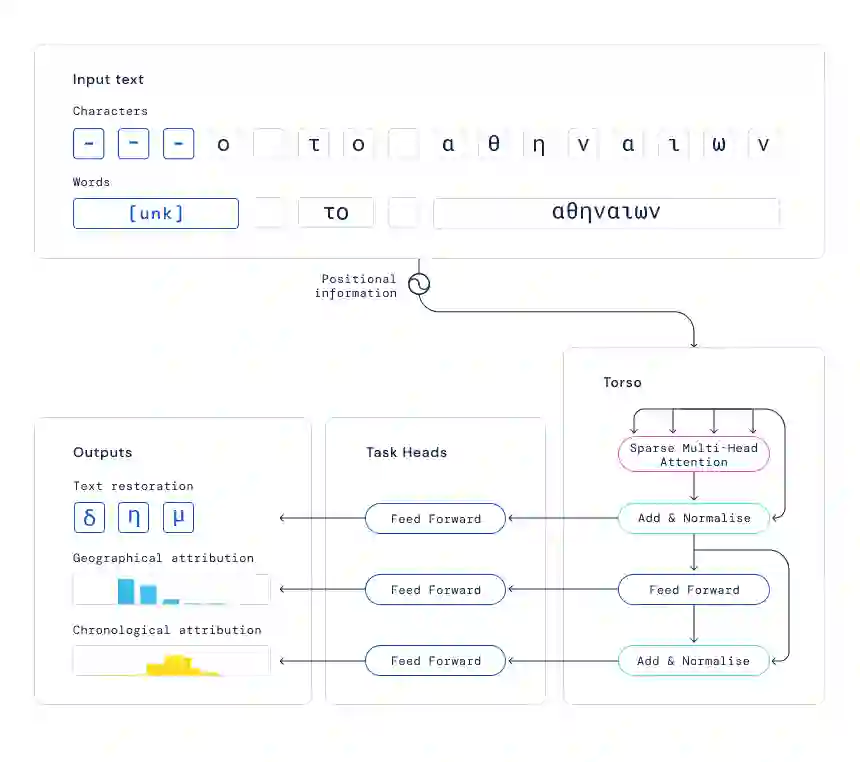
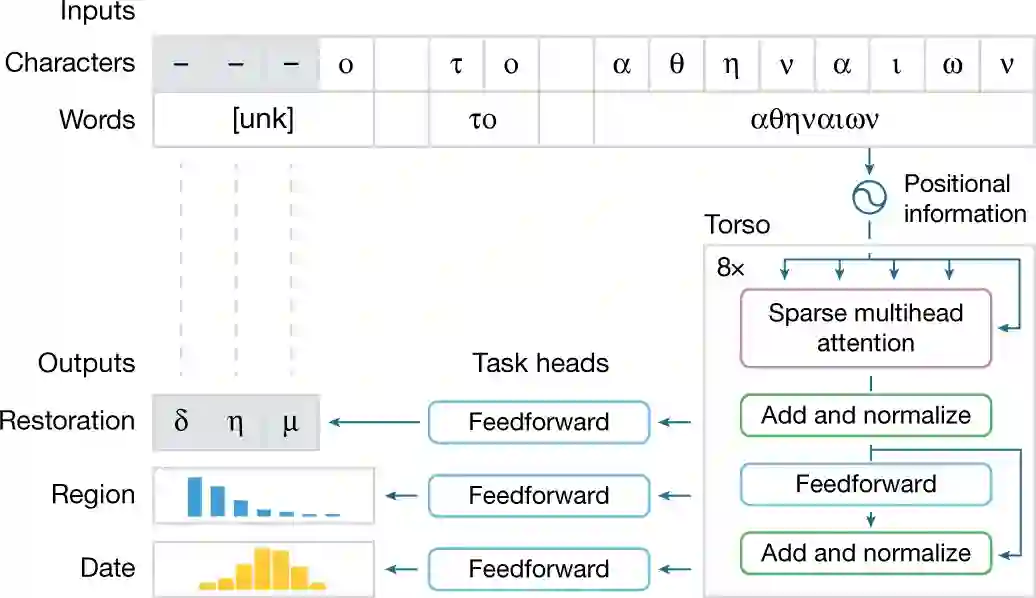
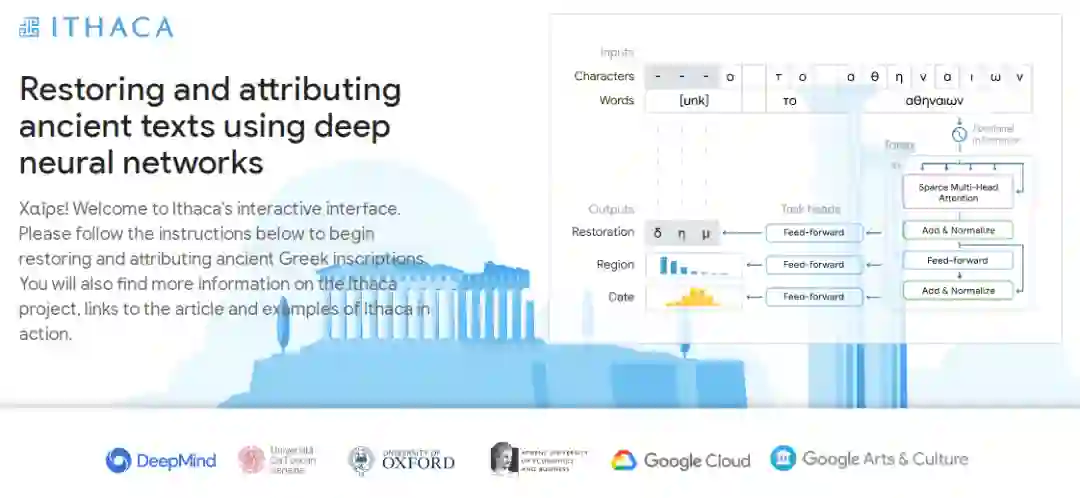
下图 2 为 Ithaca 的架构。文本受损部分用符号「-」表示,并人为损坏了字符
![]() 。
提供输入后,Ithaca 恢复了文本,并识别出文本编写的时间和地点。
。
提供输入后,Ithaca 恢复了文本,并识别出文本编写的时间和地点。
![]()
研究者相信,这只是 Ithaca 这类工具应用的开始。
他们目前正在研究针对其他古语言训练的 Ithaca 版本,历史学家也已经可以在当前架构中使用他们的数据集来研究其他古书写系统,比如阿卡德语、古埃及世俗体、希伯来语和玛雅语言。
该研究使用机器学习进行铭文识别,他们提出了 Ithaca,这是一种经过训练的深度神经网络架构,可以同时执行文本恢复、地理归因和时间归因任务。
Ithaca 是在最大的希腊铭文数字数据集上训练完成,该数据集由帕卡德人文学院 (PHI)提供,这是一个非营利基金会,成立于 1987 年,该机构旨在为基础研究创建工具人文学。通常来讲,自然语言处理模型使用单词进行训练,它们在句子中出现的顺序以及单词之间的关系可以提供额外的上下文和含义。然而 Ithaca 的铭文损坏严重,丢失了大部分文本块。为了确保模型有效,该研究使用单词和单个字符作为输入。模型核心为稀疏自注意力机制,用来并行计算这两个输入(单词和单个字符)。
![]()
为了最大限度地发挥 Ithaca 作为研究工具的价值,该研究还创建了许多视觉辅助工具,以确保 Ithaca 的研究结果易于被历史学家解读:
恢复假设:Ithaca 为文本修复任务生成几个预测假设,供历史学家利用自身专业知识进行选择;
地理归属:Ithaca 通过为历史学家提供所有可能预测的概率分布来显示其不确定性,而不仅仅是单个输出。因此,Ithaca 返回代表其确定性水平的 84 个不同古代区域的概率。可以在地图上将这些结果可视化,以阐明古代世界可能存在的潜在地理联系;
时间归属:当需要确定一篇文献的年代时,Ithaca 会产生从公元前 800 年到公元 800 年预测日期分布,这可以使历史学家了解模型对特定日期范围的可信度,提供有价值的历史见解;
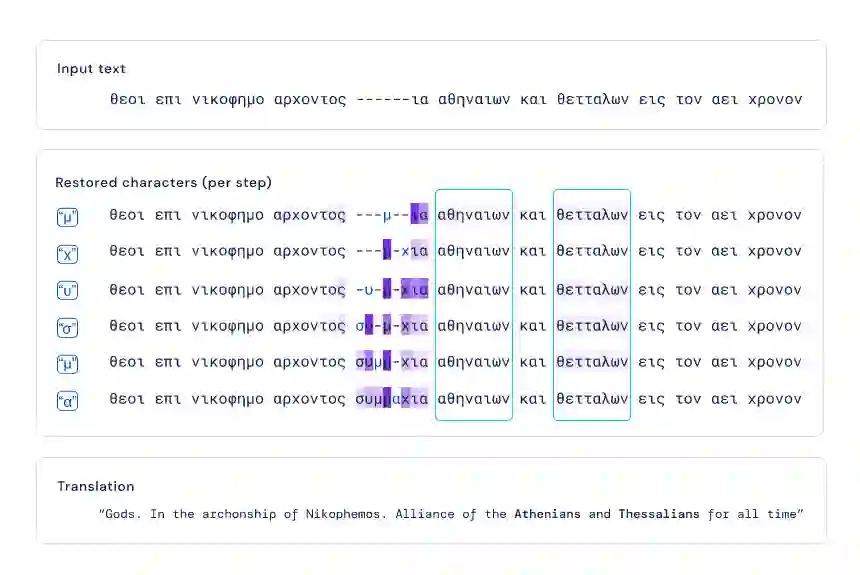
显着图:为了将结果传达给历史学家,Ithaca 使用计算机视觉中常用的一种技术来识别哪些输入序列对预测的贡献最大,输出以不同颜色强度突出 Ithaca 预测缺失文本、地点和日期的单词。
![]()
为了训练 Ithaca,该研究开发了一个 pipeline 来检索未处理的 PHI 数据集,该数据集由 178,551 个铭文转录文本组成。每个 PHI 铭文都被分配了一个唯一的数字 ID,并标有与写作地点和时间相关的元数据。PHI 共列出了 84 个古代区域,而年代信息以多种格式记录,从历史时代到精确的年份间隔,用多种语言编写。PHI 数据集在经过处理和过滤后,该研究得到新数据集 I.PHI,据了解这是最大的机器可操作铭文多任务数据集,包含 78,608 个铭文。
由于部分铭文文字丢失,该研究将字符和单词作为输入,用特殊符号 [unk] 表示损坏、丢失或未知的单词。接下来,为了实现大规模处理,Ithaca 的主干是基于 transformer 的神经网络架构,它使用注意力机制来衡量输入的不同部分(如字符、单词)对模型决策的影响过程。通过将输入字符和单词表示与它们的顺序位置信息连接起来,注意力机制得到输入文本的每个部分的位置。
Ithaca 的主干由堆叠的 transformer 块组成:每个块输出一系列处理后的表示,其长度等于输入字符的数量,每个块的输出成为下一个块的输入。主干的最终输出被传递给三个不同的任务头,分别处理恢复、地理归属和时间归属。每个头都由一个浅层前馈神经网络组成,专门针对每个任务进行训练。在图 2 所示的例子中,恢复头预测了三个丢失的字符;地理归属头将铭文分为 84 个区域,并且按时间顺序的归属头将其追溯到公元前 800 年至公元 800 年之间。
![]()
该短语的前三个字符被隐藏,Ithaca 提出了修复建议,同时,Ithaca 还预测了铭文的地区和日期。
如下表 所示,对于恢复任务,Ithaca 始终优于竞争方法,获得 26.3% 的 CER 和 61.8% 的 top 1 准确率。具体来说,与人类专家相比,Ithaca 实现了 2.2 倍(即更好)的 CER,而与 Pythia 相比,Ithaca 的 top 20 预测实现了 1.5 倍的性能提升,准确率为 78.3%。
值得注意的是,将历史学家与 Ithaca 组合时,借助 Ithaca 辅助的人类专家的 CER 为 18.3%,top 1 准确率为 71.7%,与原始人类专家 CER 和 top 1 相比,提高了 3.2 倍和 2.8 倍。
关于区域归属,Ithaca 的 top 1 预测准确率为 70.8%,top 3 的预测准确率为 82.1%。最后,对于时间归属,从真实日期间隔到人类基线预测的平均时间是 144.4 年,中位数是 94.5 年,但 Ithaca 中位距离仅为 30 年。
![]()
原文链接:https://deepmind.com/blog/article/Predicting-the-past-with-Ithaca
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


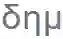 。
提供输入后,Ithaca 恢复了文本,并识别出文本编写的时间和地点。
。
提供输入后,Ithaca 恢复了文本,并识别出文本编写的时间和地点。