CVPR 2022|旋转小目标新解法,浙大等提出Oriented RepPoints!

极市导读
本文做为保姆级解读,从他的前前身DCN系列网络开始,再回归到他的前身网络RepPoints的基本原理 ,本文主要介绍DCN系列和RepPoints 中与Oriented RepPoints相关的内容,其他的参见原论文,最后再回归到本文的Oriented RepPoints网络。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

前言
与通用目标相比,空中目标通常环境杂乱且目标任意方向非轴对齐。不同于回归边界框方向的主流方法,本文通过利用自适应点表示,提出了一种有效的自适应点学习方法来进行航空目标检测,该方法能够捕获任意方向目标的几何信息。为此,提出了三种定向转换函数,以方便准确的定向分类和定位。同时,本文还提出了一种有效的质量评估和样本分配方案,用于自适应点学习,以在训练期间选择具有代表性的Oriented RepPoints样本,该方案能够从相邻对象或背景噪声中捕获非轴对齐的特征,引入空间约束来惩罚自适应点学习的异常点。在包括 DOTA、HRSC2016、UCAS-AOD 和 DIOR-R 在内的四个具有挑战性的航空数据集上的实验结果上证明了作者方法的有效性。
本文做为保姆级解读,从他的前前身DCN系列网络开始,再回归到他的前身网络RepPoints的基本原理 ,本文主要介绍DCN系列和RepPoints 中与Oriented RepPoints相关的内容,其他的参见原论文,最后再回归到本文的Oriented RepPoints网络。
1.DCN系列
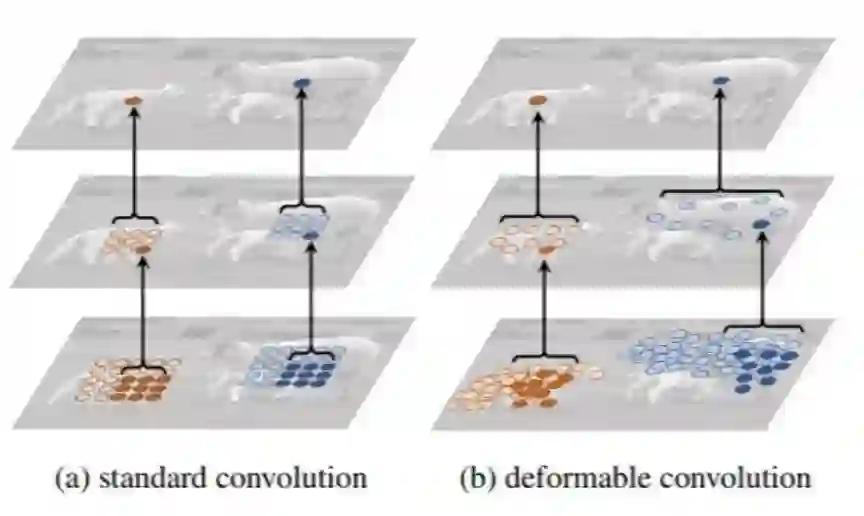
可变形卷积网络(Deformable Convolution Network,DCN)系列算法[1,2]的提出主要解决的问题是我们常规的图像增强、仿射变化不能解决的对象目标多种形式的几何变换问题,如下图:

在DCNv1[1]中,作者提出了可变形卷积(Deformable Conv)和可变形池化(Deformable Pooling)两个模块。DCNv2则是在DCNv1的基础上对两个可变形模块添加权重模块,增强了可变形卷积网络对重要信息的捕捉能力。
1.1 DCN V1
于是DCNv1提出可变形卷积核、可变形ROI池化以及可变形的位置敏感ROI池化,可变形的位置敏感ROI池化是基于上面引申的,原理同可变形的ROI池化相同,这里不单独出来说。
1.可变形卷积其核心思想在于,它不认为卷积核应该是规规整整的矩形,其可以是任意形状的,如下图:
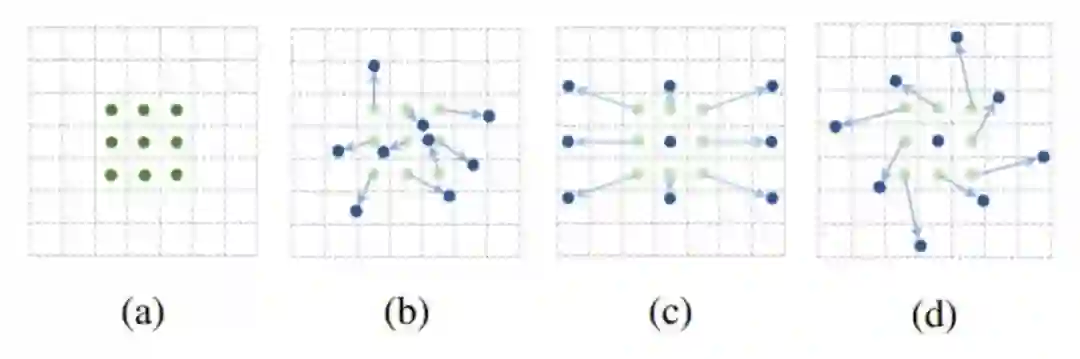
对于每个输出y(p0),都要从x上采样9个位置,(-1,-1)代表x(p0)的左上角,(1,1)代表x(p0)的右下角:
对于传统卷积,公式如下:
对于可变形卷积,卷积的映射是由下式表示的:
在传统卷积的基础上,增加一个偏移量,为啥增加这个呢,看下图:
对于左图来说,传统的卷积并不能完整的表示羊的特征,右图采用可变形卷积,充分获取羊的特征。这个偏移量是位置的偏移量,比如卷积核某个点一开始位于(-1,-1)这个位置,有了偏移量后,可能在(-1,2)的位置,另外偏移量可能是个浮点型,所以上式中的x这个特征值需要通过双线性插值的方法来计算。如何获得这个偏移量呢?通过训练学习得到,如下图。
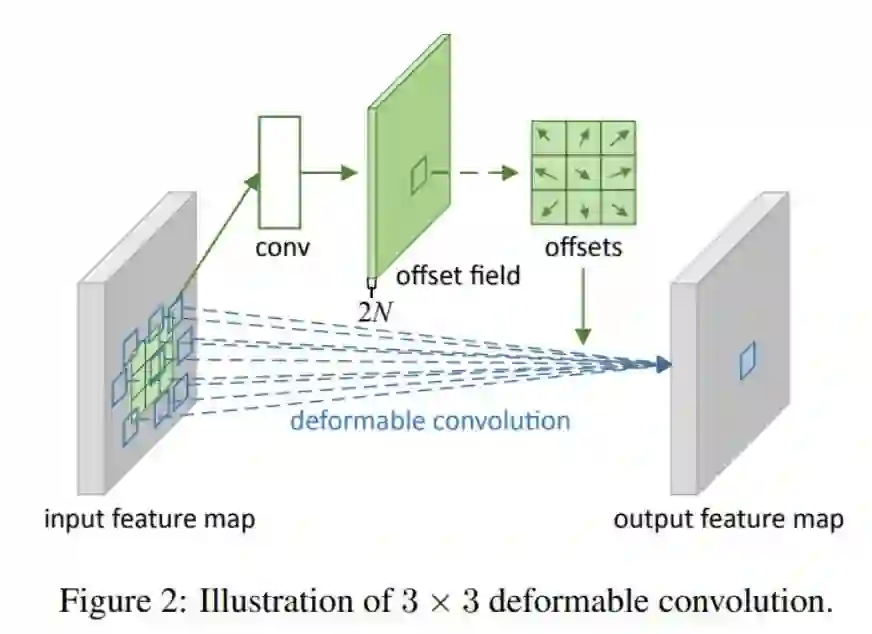
对于输入一张5x5x3的feature map,假设原来的卷积是3x3,inchanel和outchannel均是3,输出维度仍是5x5x3,现在为了学习偏移量,需要重新定义一个3x3的卷积,如上图,这里inchannel仍是3,但是输出的outchannel需要是2倍,即6,因为他需要输出x和y两个方向的偏移量,获得每个点偏移量后,即获得△Pn,因为△Pn不一定是整数,所以需要基于输入的特征值双线性插值获得x(p0+pn+△Pn)值,后面和普通的卷积一样,权值相乘后相加。以上可变形卷积可以自适应的学习感受野,学习与目标区域感兴趣的区域。
2.可变形ROI池化
可变形的ROI池化原理同可变形卷积相同,一般ROI池化是faster RCNN中引入的,是在操作中将ROI划分成k x k个子区域,对每个子区域取平均值或者最大值,可变形的ROI池化则是在区域划分上增加偏移量,有k x k个子区域则有kxk个偏移量,与可变形卷积不同的是,这里的偏移量通过fc全连接层得到,通过fc层生成2xkxk个值,前面kxk个为kxk个x的偏移量,后面是y的偏移量,后面基于偏移量获得kxk个子区域相对之前的位置,再去做池化操作。
3.可变形卷积网络DCN v1
目标检测网络或者分割网络往往可以分成两个部分:特征提取模块和head输出模块。其中在特征提取模块和head输出模块中的普通卷积可以用可变形卷积替代。在池化上也是,如Faster RCNN的ROI池化可以使用可变形ROI池化。
1.2 DCN v2
DCN v2 作者可视化了DCNv1的结果:

图中发现可变形卷积会引入无用的上下文信息,其感受野容易超出目标范围,干扰特征提取,为此作者提出了DCNv2解决此问题:
-
使用更多的可变形卷积; -
在DCNv1的基础上添加每个采样点的权重; -
针对可变形卷积的训练,为了让其更好的学习,通过RCNN指导Faster RCNN做知识蒸馏。这里主要讲第二点。DCN v1给普通卷积的采样点增加偏移,v2在此基础上还允许调节每个采样位置或者bin的特征的权值,就是给这个点的特征乘以个系数,位于(0,1)之间,如果系数为0,就表示这部分区域的特征对输出没有影响,这个系数也是通过训练学习得到,这样在可变形卷积的输出通道由之前的2N增加到3N:
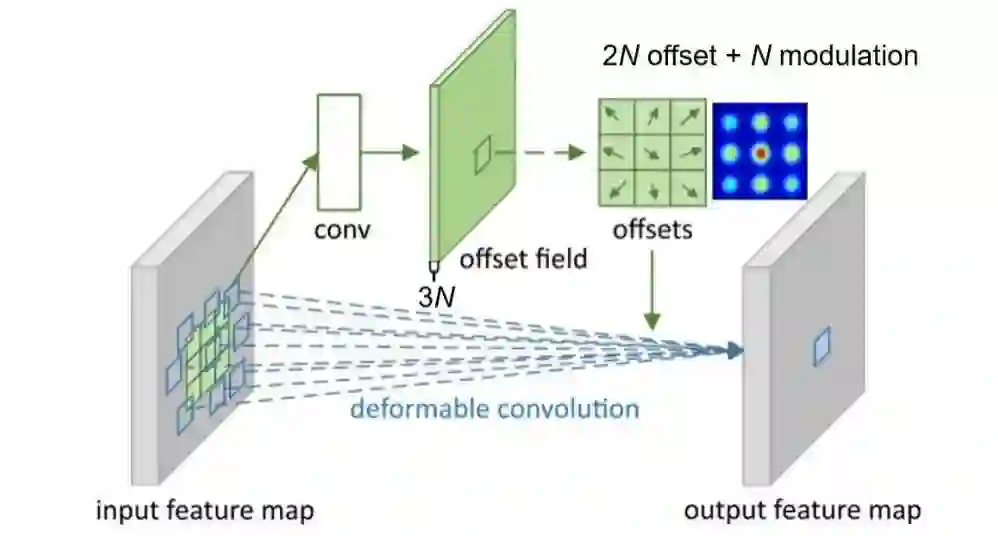
在可变形ROI池化中,也是通过增加权重输出:

个人感觉DCNv2最大的创新点在于提出了对采样点的权重。

上图是使用DCN v2的可视化结果,相对于DCN v1,其ROI区域更能反映目标区域。同时作者在coco和imagenet上均做了实验,涨点明显,详情可以去看原文[3]。
2.RepPoints
RepPoints 是一种新的目标表示方法,是基于可变形卷积的一种延伸,在目标检测场景中,一般有anchor base和anchor free两种思路,在anchor base 算法中,如faster RCNN、Yolov3、v4、v5等模型效果往往受限于anchor的参数配置,如anchor的大小、正负样本采样等。在anchor free 算法中,也分为两种思路,anchor-point的算法和key-point的算法,anchor-point通过预测目标中心点(x,y)及边框距中心点的距离(w,h)来检测目标,典型的此类算法有Yolov1,FCOS等,而key-point方法是通过检测目标的边界点,如:角点,再将边界点配对组合成目标的检测框,此类算法包括CornerNet等。
Reppints可以看做这两种思路的结合。它同anchor-point一样,在feature map的每个location位置,以该location做为中心,去预测一个box,但是它预测的不是类似FCOS那样的到box四个边界的距离,而是预测的一系列reppoints,然后通过把这些点映射为box得到最终的结果。它提供了更细粒度的定位和更方便的分类。
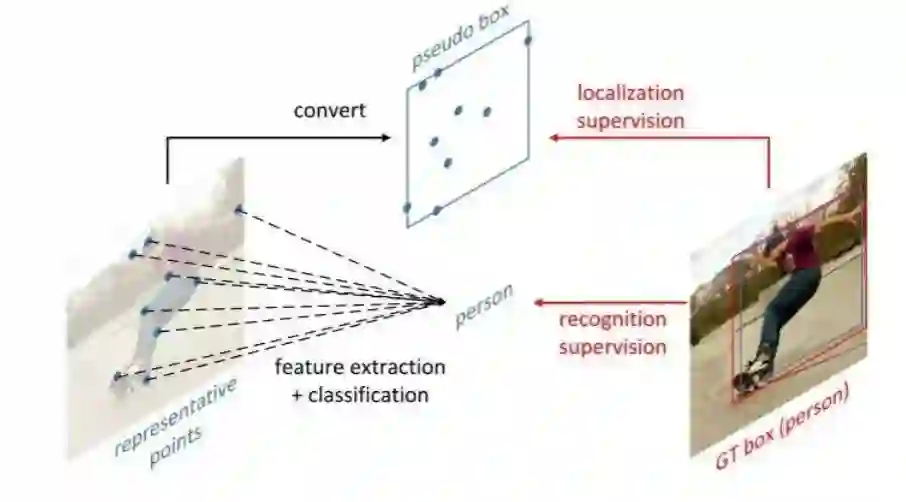
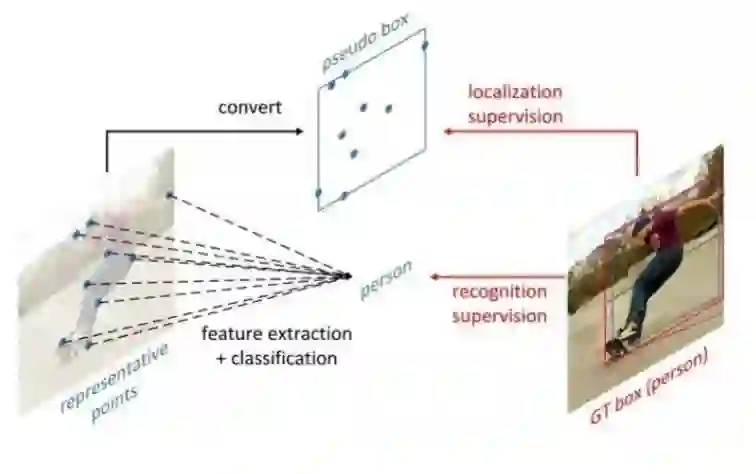
如图所示,RepPoints是一组点,通过学习自适应地将自己置于目标之上,该方式限定了目标的空间范围,并且表示具有重要语义信息的局部区域。
2.1 原理
与Yolov1一样,如一张640640的图片,在backbone提取特征过后,如果经过5次下采样后,feature map成2020的长宽,yolov1的做法是将2020映射到原图上,有2020的网格grid,每个网格32*32的像素,默认为目标的中心点落在的所在grid负责预测该目标,该grid下采样到feature map上就成了一点,那我们只需要预测出四个维度:目标中心点(x,y)偏移该grid中心点多少,以及目标的长宽即:
就可以预测出目标的具体位置。所以feature map的channel维度上需要学习(x,y,w,h)4个channel来对目标定位。
与Yolov1不同的是,RepPoints需要预测出9个点,即在每个feature map对应的location位置,网络需要学习出9组偏移量,如下图所示:
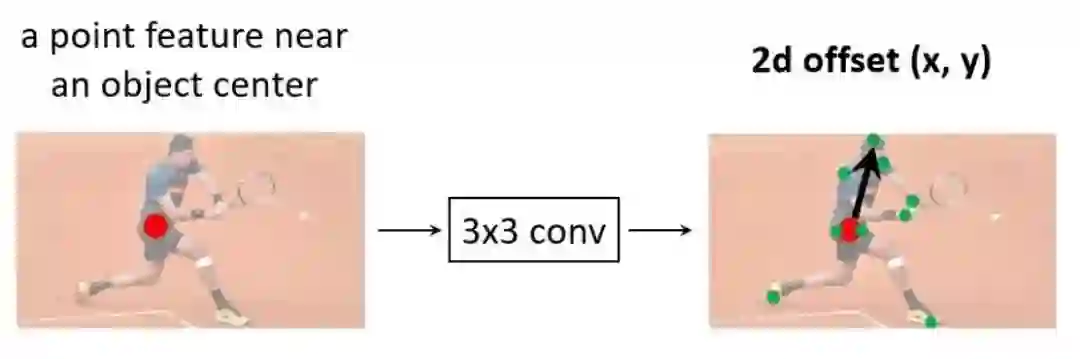
如20x20长宽的feature map,共有400个点,对于每个点需要预测出9个点,来调整样本点的位置:
(△xk,△yk)分别为预测点相对于中心点的偏差,n一般取9,怎么去学习这个偏差值呢,这块和可变形卷积DCN原理相同。
综上可以发现其实这个检测思路和FCOS和YOLO等有一点点像,都是把每个位置作为中心点,作者认为Yolov1这类检测虽然也是anchor free,但是需要4d空间(x,y,w,h),这里只需要二维空间(x,y),即9个点的坐标,似乎9个点去还原一个box有点多余,理论上两个点就可以还原一个box了,但是作者认为学习9个点计算出的box更准确,他发现这9个点经常落在极点或者对语义表达很有帮助的地方,如下图。
2.2 RPdet
综上,作者设计整个检测器架构如图:
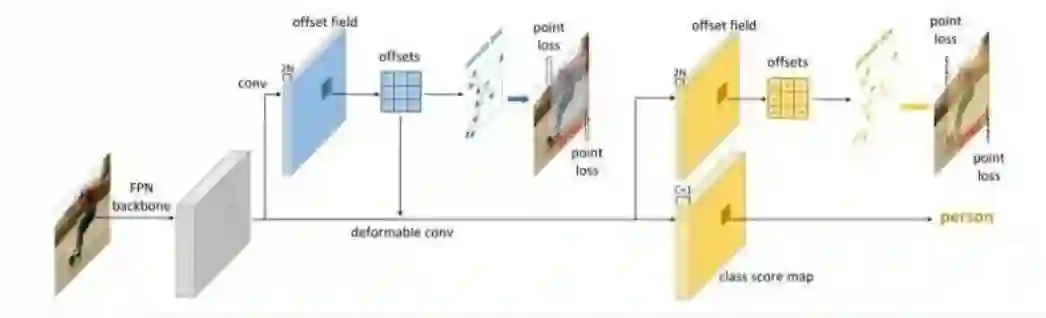
总体上,该方法是基于全卷积网络实现的,输入图像经过FPN主干网络后,经过一次3x3的可变形卷积,预测的offset经过坐标计算,得到第一次的RepPoints,可形变卷积继续提取特征,再预测得到offset和每个位置的分类结果,由offset计算得到细化后第二次的RepPoints。最终将每个位置的RepPoints转换预测框,加上分类结果,得到目标检测的结果。具体的实现网络如图:
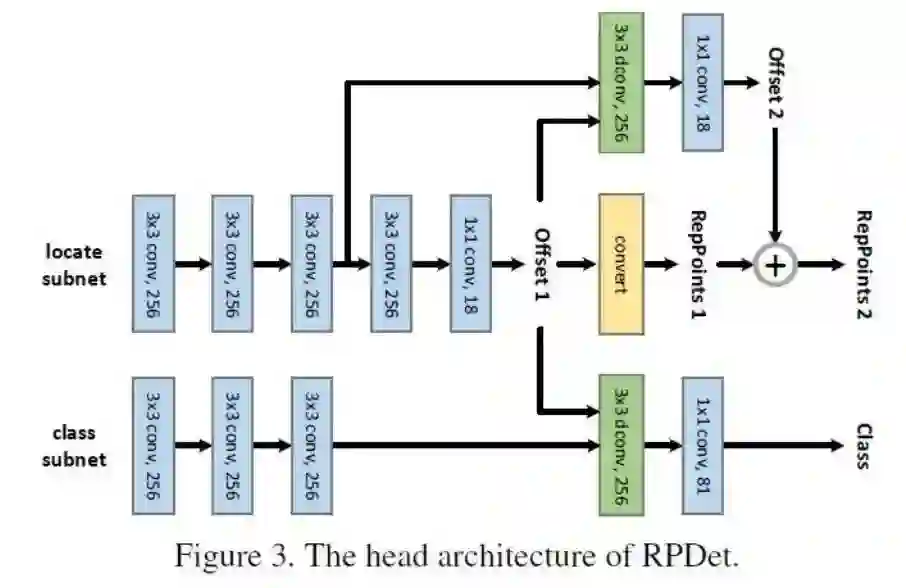
即Class分支仅使用Offset1的输出值,而卷积独立进行。Offset2则继续使用Offset1子网络的特征图。Class分支和Offset2分支都使用了可形变卷积。目标表示的演化过程如下:
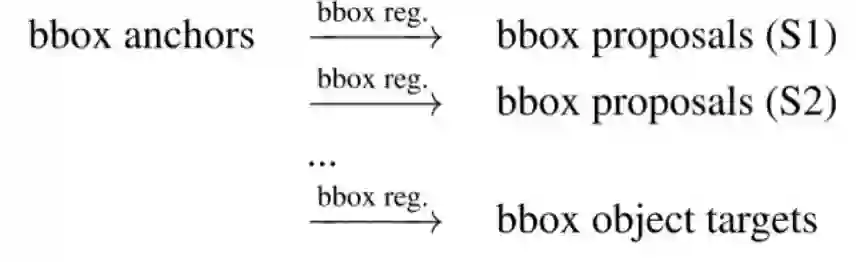
RepPoints检测器由两个基于可变形卷积的识别阶段构成,思路同faster RCNN一样,不断的修正目标检测位置:

2.3 loss
根据上面location学习的点,怎么把reppoints转化为box来衡量检测结果和gt的差异,这里作者给出了几种不同的思路:
-
Min-max function:在所有点中找最小和最大值,获得囊括所有点的外接矩形框; -
Partial min-max function:选取部分点进行上述操作 -
Moment-based function:求出所有样本点的均值和方差,通过另外两个全局学习的系数将均值和方差还原为box。
作者通过得到box和gt的top-left与bottom-right之间的smooth l1误差来监督,实验发现,这三种思路得到的结果差异比较小(在0.1%内)。
定位loss计算时,将RepPoints按照转换函数,转换为预测框,然后使用smooth L1 Loss。第一次和第二次RepPoints的定位损失均只计算正样本。
总的来说,第一次RepPoints计算一次定位损失,同时考虑分类损失。使第一次RepPoints的训练额外结合了分类的监督信息,这一点和可形变卷积的过程一致。第二次RepPoints再计算一次定位损失,但是不计算分类损失了。
RepPoints在19年时,感觉借鉴了很多faster RCNN的思路,最大的亮点是增加了对于可形变卷积的监督。可形变卷积有很强的表达能力,很好的性能,因此尝试加强对于可形变卷积的监督,增加可形变卷积的特征点和目标检测中物体的联系。即可形变卷积中的特征点,经过设计训练后,是可以具有一定的显式语义信息的。
RepPoints中的特征点倾向于表示物体的中心点和极点,可以看做是一种关键点检测的过程,不过因为通过gt框去监督,相对来说对关键点的监督较弱。但是关键点只是一种可视化结果,可能其学习的是无法表达的语义信息,所以如果真的直接基于关键点去监督,反而可能画蛇添足,缺少泛化性。
3 Oriented RepPoints
接下来来到本文的重中之重Oriented RepPoints,Oriented RepPoints则是在RepPoints的基础上改进了三种定向转换函数,以方便更准确的定向分类和定位。同时,本文针对RepPoints对关键点的监督较弱进行改进,提出了一种有效针对自适应点的质量评估和样本分配方案(APAA),用于对自适应点的监督,以在训练期间选择具有代表性的Oriented RepPoints样本,该方案能够从相邻目标或背景噪声中获取非轴对齐的特征,同时引入空间约束来惩罚自适应点学习过程的异常点。
自适应点学习
在可变形卷积获得目标的9个采样点后,怎么转换成带角度的边界框呢,Oriented RepPoints在RepPoints基础上改进了三个转换函数:
-
MinAeraRect:在采样点中选择具有最小面积的旋转四边形; -
NearestGTCorner:通过gt的四个角点,找到分别距离gt四个角点最近的采样点作为预测点,连接的四边形作为边界框; -
ConvexHull:通过Jarvis March【12】算法,找到包围所有采样点的外接多边形;
值得注意的是,NearestGTCorner 和ConvexHull是可微的,所以作者将其用于训练优化时候,MinAeraRect是不可微的,作者将其在推理的时候使用,在gt的监督,通过分类和定位损失驱动,采样点自适应地向目标的语义关键和几何特征方向移动,同时自适应点也将角度信息学习进去,通过转换函数已经将角度信息考虑进去,也无需再去对旋转角度单独回归。
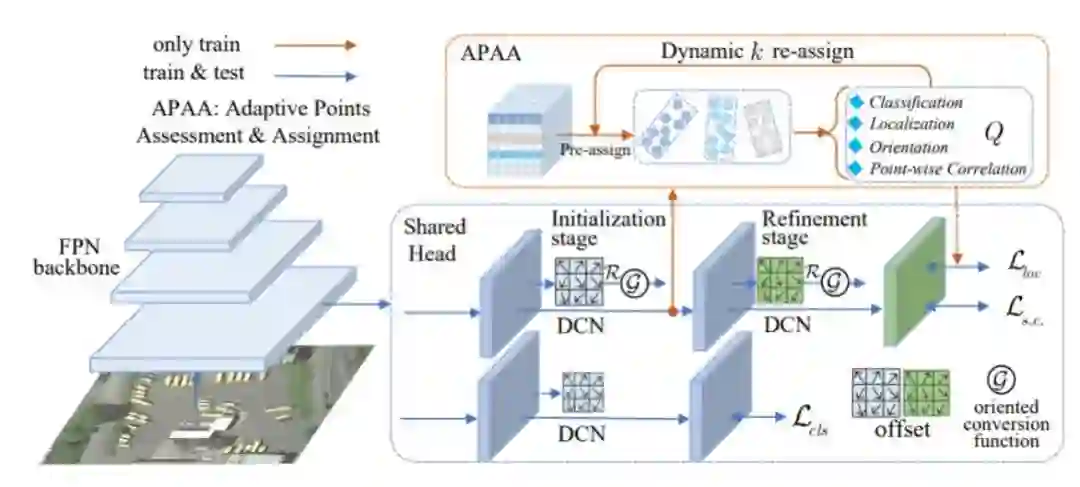
整体网络架构同RepPoints一样,由两阶段组成,第一阶段通过中心点生成多个自适应采样点,第二阶段,通过损失函数进一步精确定位,同样分类只在第一步进行:
和 为损失权重, 为分类损失,计算公式如下:
为采样点的预测的类别的置信度, 为对应 gt 的类别, 是使用 focal Loss, 是整个采样点集合的数量,和分别是两个阶段的回归 loss,对于每个阶段 为: 为已经转换方向的 box 的回归损失, 为空间约束损失 :
使用 GIOU loss,因为航拍图像中背景杂乱以及类别的多样性,部分学习到的点容易 受到具有强关键特征的背景或相邻目标的影响,这些点可能会移到 gt 之外。为了便于 脆弱点捕获目标的几何特征,作者引入空间约束来惩罚边界框外的自适应点。令 表 示惩罚函数。空间损失 计算如下:
定义如下: 为对每个 box 包含的采样点数, 为在 外的采样点数,令 表示 的几何中心。给定边界框外的采样点 ,惩罚项定义如下:
自适应点的评估与分配
在RepPoints 中,即使是学到了语义特征和几何特征点,因为最后需要转换成box,通过gt对box监督完成模型训练,缺乏对自适应点的监督,这里对其进行改进,在训练阶段,对学习到的特征点进行评估,将选择高质量的自适应点做为正样本参与下一阶段。
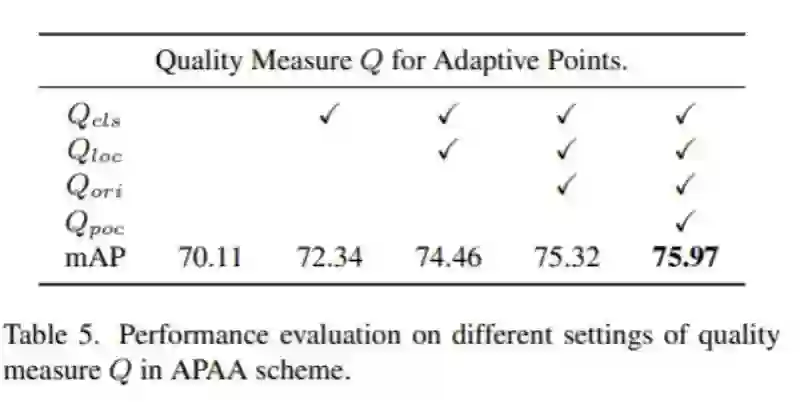
自适应点的质量评估: 作者定义了一个质量度量 来从四个方面评估学习到的自适应点。包括每个定向点集的分类和定位能力 . 、方向对齐能力 和逐点相关能力 因此. 的推导如下:
其中:
即分类损失函数,反应了自适应点与 gt 之间的置信度的兼容性,同理 使用基于 IOU 的回归损失函数:
由于 为空间位置距离的度量,它对角度变化不敏感,尤其是对于航拍图像中的物体。为了保证方向对齐性,作者先采用 MinAeaRect 转换函数从学习的点集中获得四个空间 角点 ,然后从两个相邻的角点以等间隔对有序点集 (默认为 40 个 点) 进行采样。同样,为 ground-truth 角点 也等间隔生成 40 个点组成 。因此, 定义如下:
由于 为空间位置距离的度量, 它对角度变化不敏感, 尤其是对于航拍图像中的物体。为了保证方向对齐性,作者先采用 MinAeaRect 转换函数从学习的点集中获得四个空间 角点 ,然后从两个相邻的角点以等间隔对有序点集 (默认为 40 个 点)进行采样。同样,为 ground-truth 角点 也等间隔生成 40 个点组成 。因此, 定义如下:
其中:
为了保证 Oriented RepPoints 的采样点集上的逐点关联,作者提取逐点特征并采用特 征向量之间的余弦相似度作为学习自适应点的相关度量 令 表示第 组自适应 点向第 个自适应点特征向量。 和 分别表示归一化的特征向量和所有来自第 个 点集特征向量的平均值:
其中 表示自适应点的数目。默认设置为 9 。基于上述符号,第 个点集的 Qpoc 可以 表示为逐点特征多样性, 如下所示:
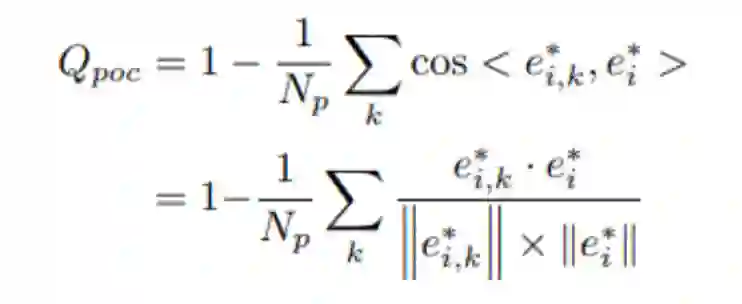
动态top k 标签分配
基于每个自适应点的质量评估 ,在训练阶段,每次迭代时,选择 top 自适应点做为 RepPoints 的样本点,对于每个目标, 在第一阶段时,根据质量评估分数,对所有自适 应点做排序,为了检索高质量的自适应点样本,设置一个采样率 ,将每次迭代的前 个样本分配为训练的正样本, 其计算公式为:
其中 表示每个目标在第一阶段的自适应点集样本总数。在训练阶段, 通过可变形卷积 在第一阶段获得基于基于中心点的自适应点分布,在第二阶段,提出的自适应点评估和 分配 (APAA) 方案用于根据质量度量 选择高质量的点样本,只有被选择的适应点参与框的回归。
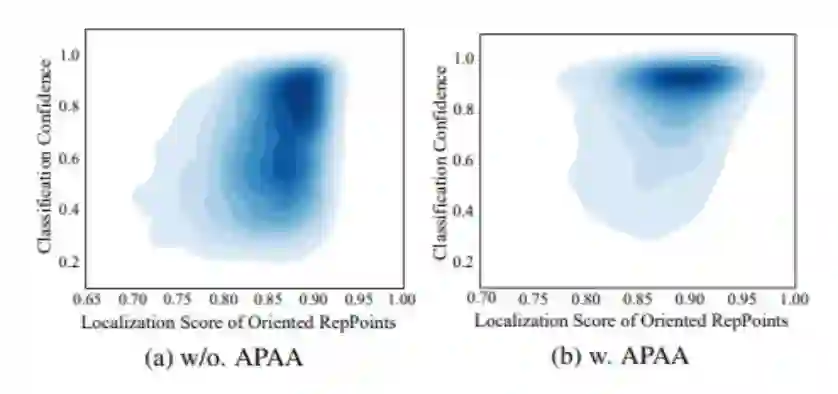
如图所示,APAA 方案使检测器能够预测高质量的Oriented RepPoints,以提高分类置信度和定位分数。同时APAA仅用于训练,在推理阶段不会产生额外的计算量。
实验
作者在DOTA、HRSC2016、UCAS-AOD 和 DIOR-R 在内的四个的航空数据集上进行试验,主干网络采用ResNet50和ResNet101和FPN,并基于各个维度做对比实验,效果对比明显,相关参数参见论文。
质量评估参数
基于自适应点质量Q的topK自适应选取,选取不同的采样率的影响:

图中采样率为0.4时,map微涨点。
使用不同样本分配方案的对比:
消融试验
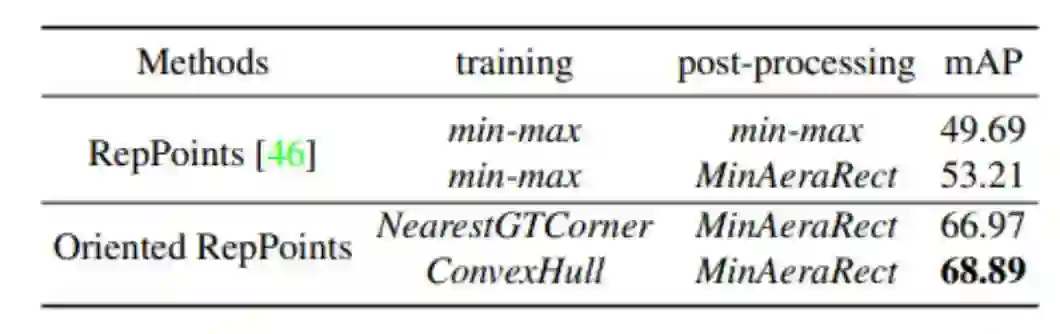
定向转换函数:
基于ResNet50和FPN的主干网络的消融试验如下:Oriented RepPoints与纯RepPoints对比如下,通过自适应点的转换函数到对应的box中,不同的转换函数的影响如下,图中可看出,通过可微分NearestGTCorner和ConvexHull转换函数训练,MinAeraRect 推理,Oriented RepPoints可以达到66.97%和68.89%的map,说明定向转换函数对于空中目标检测的重要性。
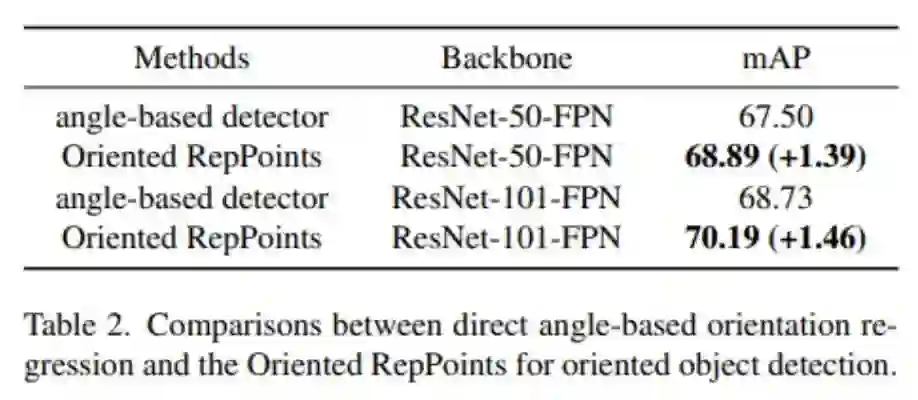
基于角度检测器的对比:
为了检查自适应点的有效性,作者将其与基于锚点的检测器上的基于角度的方向回归进行了比较。基于角度直接回归的检测器在第一阶段为每个特征图位置预设一个矩形锚点,在第二阶段细化锚点预测的带角度的box,以获得定向box。发现Oriented RepPoints相对于直接回归角度的检测器,map平均上涨至少1个点。
空间约束的评估:
将其与未使用空间约束的baseline方法进行比较, 如图所示。空间约束尤其是对于具有弱特征表示的空中物体,例如 HC(直升机),以及与背景相似的物体,例如 BD、BR和 RA效果提升明显。主要是空间约束对跳出gt框的自适应点强制惩罚。
APAA 框架:
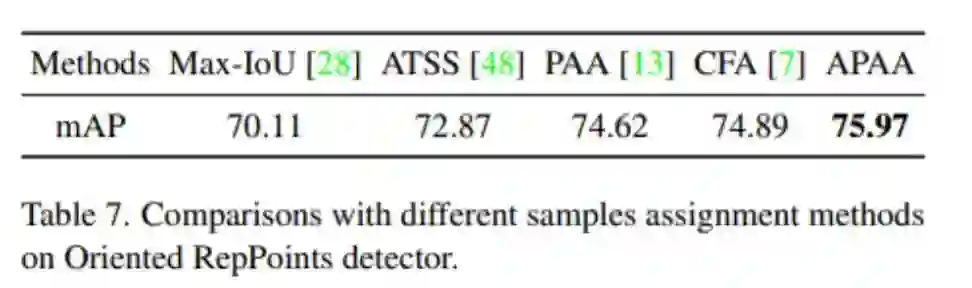
作者提出APAA 方案与其他样本分配方案训练检测器后推理结果对比,包括 Max-IoU [13],ATSS [14]、PAA [15] 和 CFA [16]
不同数据集
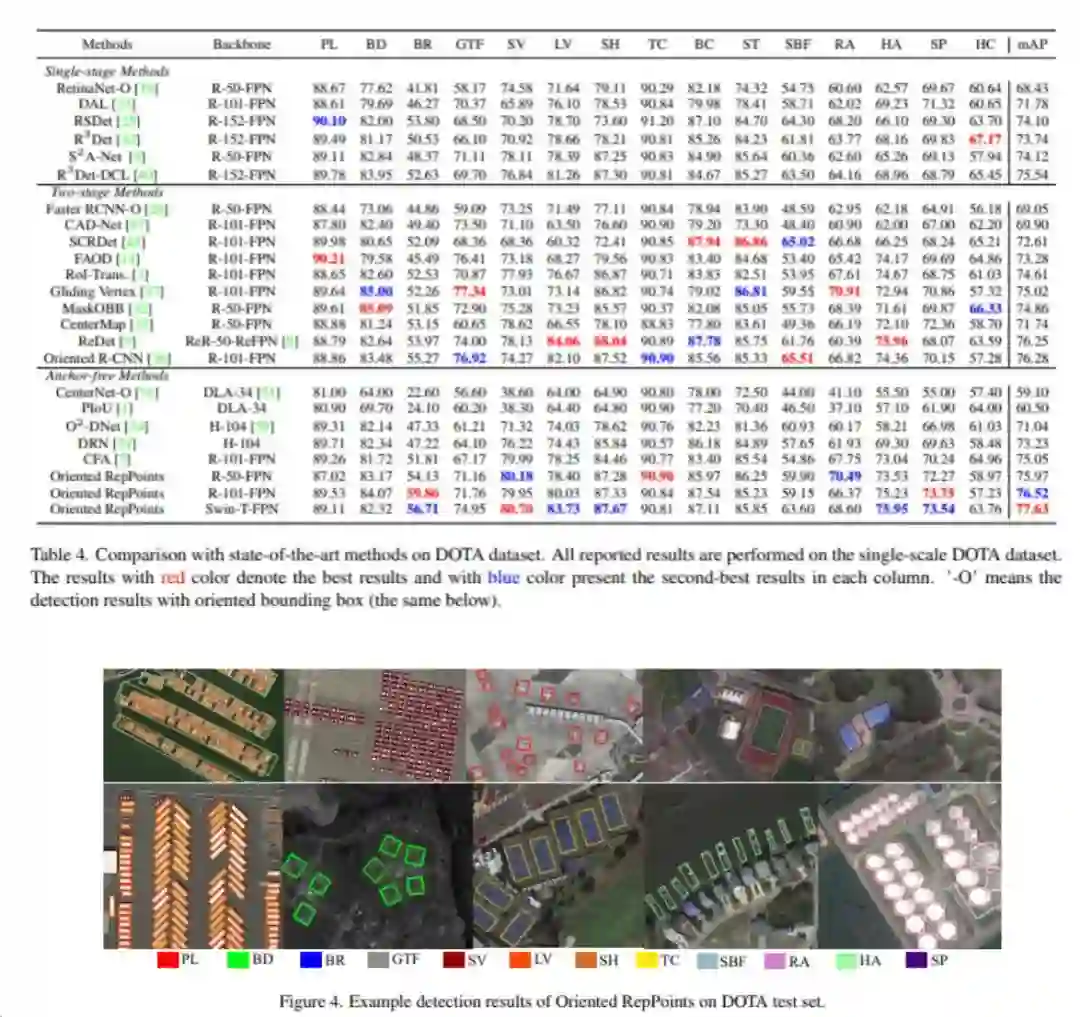
DOTA数据集:
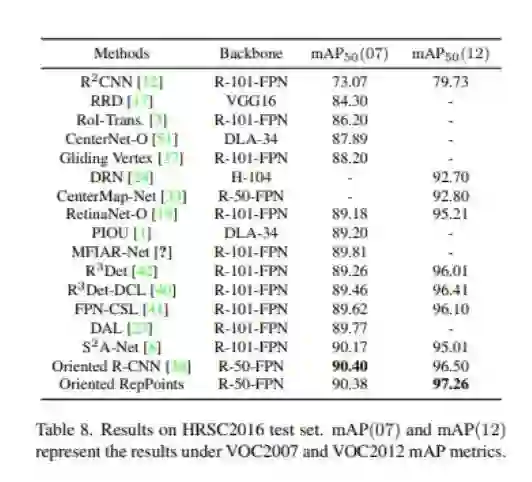
HRSC2016数据集:
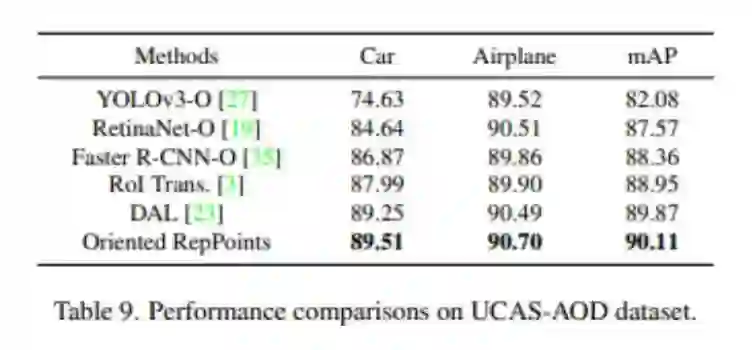
UCAS-AOD数据集:
DIOR-R数据集:

方向精度评价
在DOTA数据集上,使用ResNet-50-FPN做为主干网络,使用所有类别对角度的平均误差做为评估标准:

对比发现,Oriented RepPoints方向误差最小,精度最高。
结语:
综上,本文与RepPoints对比,创新点在于两点:一是改进了三个转换函数,在RepPoints基础上做了改进,二是提出APAA框架,通过对每个自适应点的质量评估,选取质量最高的K个自适应点参与第二阶段的精确定位,和Faster RCNN的思路异曲同工,同时自适应点也将角度信息学习进去,通过转换函数已经将角度信息考虑进去,也无需再去对旋转角度单独回归。
论文地址:
https://arxiv.org/pdf/2105.11111.pdf
https://arxiv.org/pdf/1703.06211.pdf
https://arxiv.org/pdf/1811.11168.pdf
https://arxiv.org/abs/1904.11490
开源代码地址:
https://github.com/LiWentomng/OrientedRepPoints
https://github.com/microsoft/RepPoints
参考:
[1] https://www.zhihu.com/question/303900394/answer/540818451
[2] https://zhuanlan.zhihu.com/p/395200094
[3] https://zhuanlan.zhihu.com/p/103070923
[4]https://blog.csdn.net/justsolow/article/details/105971437?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_utm_term~default-0.pc_relevant_default&spm=1001.2101.3001.4242.1&utm_relevant_index=3
[5] https://blog.csdn.net/qq_21949357/article/details/102656708
[6] https://zhuanlan.zhihu.com/p/64522910
[7] https://zhuanlan.zhihu.com/p/260656201
[8] https://zhuanlan.zhihu.com/p/136175181
[9] https://blog.csdn.net/qq_30146937/article/details/104530348
[10] https://www.zhihu.com/question/322372759/answer/670961802
[11] https://www.jiqizhixin.com/articles/2019-10-30-3
[12] https://blog.csdn.net/shungry/article/details/104340363/
[13]《Faster r-cnn: Towards real-time object detection with region proposal networks》
[14]《Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection》
[15] 《Probabilistic anchor assignment with iou prediction for object detection.》
[16]《Beyond bounding-box: Convexhull feature adaptation for oriented and densely packed object detection》
公众号后台回复“CVPR 2022”获取论文打包合集下载~

# 极市平台签约作者#

所向披靡的张大刀
公众号:所向披靡的张大刀
知乎:所向披靡的张大刀
热爱生活、工作,一枚女工程师的自我修炼之路。


