CVPR 2022|打破传统的跟踪范式!南大开源MixFormer:端到端目标检测新模型

极市导读
本文介绍了一篇单目标跟踪(VOT)领域的新工作-基于 transformer 的简洁的端到端模型 MixFormer,该工作已经被CVPR 2022收录。该工作打破了传统的跟踪范式,通过模板与测试样本混合的backbone加上一个简单的回归头直接出跟踪结果,并且不使用框的后处理、多尺度特征融合策略等。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文介绍一下我们在单目标跟踪(VOT)领域的新工作 MixFormer——基于 transformer 的简洁的端到端模型。MixFormer打破了传统的跟踪范式,通过模板与测试样本混合的backbone加上一个简单的回归头直接出跟踪结果,并且不使用框的后处理、多尺度特征融合策略、positional embedding等。目前在 LaSOT, TrackingNet, VOT2020, GOT-10k 等多个数据集上取得了 SOTA 效果,其中VOT2020 EAO达到了0.555,LaSOT和TrackingNet的Norm Precision指标达到了79.9%和88.9%。论文和代码及模型已开源:

论文链接:http://arxiv.org/abs/2203.11082
代码链接:https://github.com/MCG-NJU/MixFormer
1. 研究动机
目前视觉跟踪领域流行的 tracker 范式通常是多阶段的 pipeline,主要包括三个组件:
(1)CNN backbone 提取 target 和 search area 的特征;
(2)一个独立的融合模块来实现 target 和 search area 间的信息交流,使得能够做到 target-aware localization;
(3)一个预测头 tracking head 来精确定位目标,估计 bounding box。其中特征融合模块通常是跟踪算法设计的关键,传统的方法中主要使用基于互相关(correlation)的操作(如 SiamFC, SiamRPN, SiamFC++)以及在线更新的方法(如KCF, ATOM, DiMP, FCOT等)。近来受 tranformer 在视觉领域的启发,基于注意力机制的信息融合方法被引入,并取得了非常有效的效果(如 TransT, STARK, TrDiMP, TREG等)。
而即使这些基于 transformer 的模型依然依赖于 CNN 来提取特征,受限于全局建模的能力,使得这些模型并没有在 tracking pipeline 中完全发挥出 self-attention 的能力。于是我们希望克服这个问题,提出了全新的跟踪框架 MixFormer,一改传统的跟踪范式,提出了 MAM 模块,应用 attnetion 机制同时进行特征提取与信息交互,这使得我们的模型极其简洁,没有额外的融合模块。
2. 方法
网络整体架构
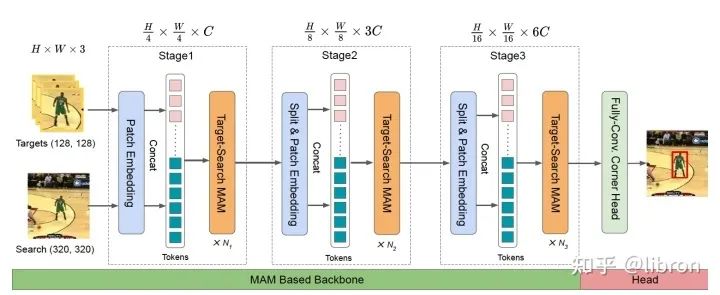
网络结构只有两个模块,一个是基于本文提出的mixed attention module (MAM)的骨干网络用来提取和融合特征,最后连接一个预测头进行定位。feature map 呈现金字塔型变化,即随着网络的加深,分辨率逐渐变小,通道数逐渐增大。MixFormer是一个端到端模型,所以没有任何框后处理操作。
混合注意力模块(Mixed Attention Module, MAM)
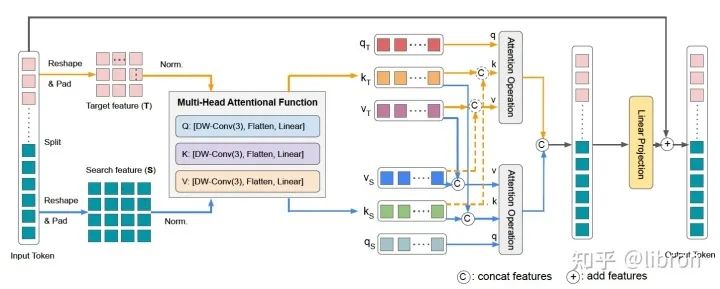
混合注意力模块(MAM)是我们框架中的核心设计,它的输入是 template 和 search area拼接 的 token sequence。因为我们希望能够同时做到特征提取和特征融合,所以不同于原始的 Multi Head Attention,MAM 首先会将输入 split 成 template 和 search area,然后同时进行 self-attention和 cross-attention。此外,我们采用了一种非对称式混合attention:删去了从 target(模板) 到 search (搜索区域)的 query ,这样做既是为了避免目标模板被动态的搜索区域影响,更重要的是能提高跟踪效率。因为target不受到search变化的影响,这样的话就可以将多个模板存为memory,不需要每帧search变化的时候重新生成。具体的实现细节可以参考我们的论文。
定位头(Localization Head)
为了验证我们提出的框架,MixFormer在两个简单的localization heads上进行实验:corner head和token head。其中Corner head借鉴了STARK,但是没有像STARK那种在head中进行decoder和encoder的融合操作,仅包括几个卷积层来定位角点并出框。另外,我们也实验了类似 DETR 的基于 query based 的 localization head,在最后一个阶段加上一个可学习的 _regression token_,最后直接对其过一个 FFN 回归坐标。这个方法同样也取得了不错的结果,这证明我们的 MAM backbone 也具有很好的泛化能力。
在线样本置信度预测模块(SPM)
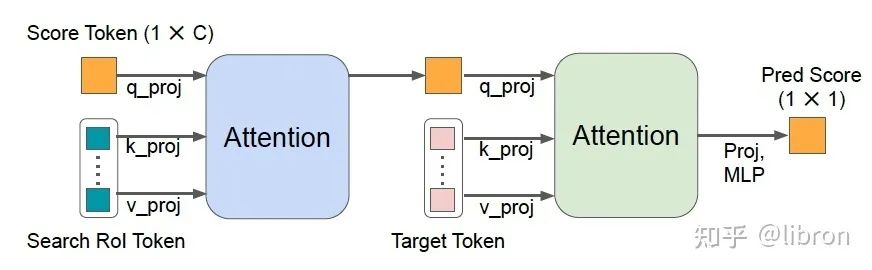
动态更新的 template 通常在获取时序信息和保持跟踪鲁棒上十分重要,尤其在目标发生变形等情况时,然而不正确的目标选取会使得跟踪结果更加糟糕。我们提出了一个 Score Prediction Module (SPM),根据预测得分来选取可靠的 online template。结构如图所示,具体细节可以参照论文。
3. 实验
多个benchmarks对比

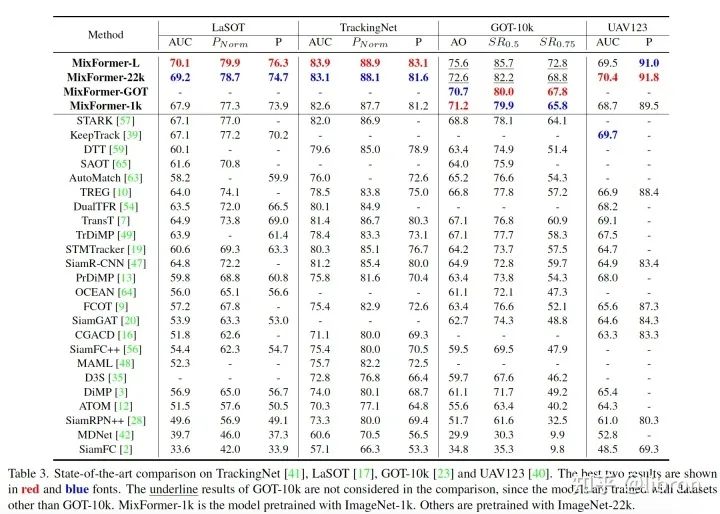
我们将 MixFormer 和其他方法在主流的单目标跟踪数据集进行了测试,包括 VOT2020/GOT-10k/UAV123 几个重要的短时数据集以及 LaSOT 和 TrackingNet 两个较大的数据集,其中 MixFormer-L 在VOT2020数据集上的 EAO 达到了0.555,相较此前的 STARK 提升了 5%,此外在 TrackingNet 和 LaSOT 数据集的 Success 和 Normalized Precision 也提升很大,在GOT-10k等数据集上也达到了SOTA的效果。
探究实验
我们从多个角度进行了消融实验分析:
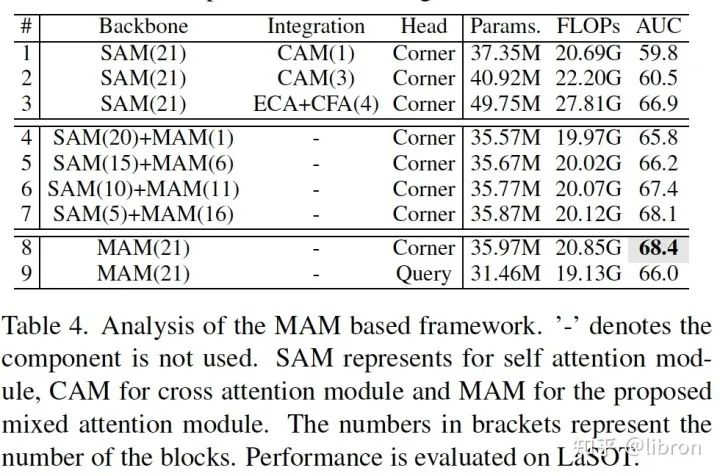
-
相较分离处理的框架先 self-attention (SAM) 提特征再 cross-attention (CAM) 融合信息,我们的特征提取和信息融合统一的结构更加有效,因为在这种耦合的模式下它们能够相互促进。
-
在不改变 attention 个数的情况下,我们将部分 MAM 替换成了 template 和 search 各自做 self-attention,也即没有了信息的交流。我们发现不同层次进行 MAM 会得到更好的性能,这更加说明了 extensive target-aware feature extraction and hierarchical information integration 是十分重要的。
-
对于定位头,我们测试了 fully convolutional corner head 和 query-based head,其中使用 corner head 的性能也比query-based head效果更好。
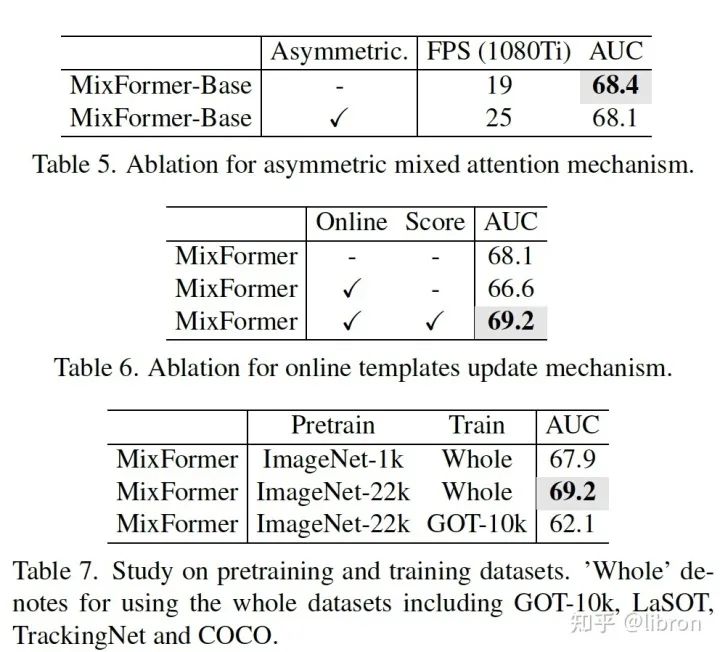
-
为了减少计算开销我们使用了 asymmetric attention,实验可以看出在损失微小性能的情况下运行速度提升了 24%。
-
当我们进行随机间隔采样更新 online template,结果变得更坏了,而加上得分预测模块之后取得了最好的 AUC。这说明合理地选择可靠的 online template 是非常重要的。
-
为了检验 mixformer 的泛化性能,我们在不同的 pretrain 模型和数据上进行分析,只在 ImageNet-1k 上 pretrain 的 mixformer 依然超越了此前的所有 sota tracker。
Attention weights可视化
更多可视化的例子与分析可以参照论文。

4. 总结
MixFormer革新了传统的跟踪范式,统一了特征提取和目标融合模块,既简化了模型也提升了跟踪的性能,希望我们的研究能够进一步推进视觉跟踪领域的研究。也非常欢迎大家能在自己的tracker上尝试一些我们的MixFormer backbone~
公众号后台回复“数据集”获取90+深度学习数据集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




