本文首发极市平台公众号, 转载请获得授权并标明出处。
极市平台一直在对CVPR 2022的论文进行分方向的整理,目前已累计更新了535篇,本文为最新的CVPR 2022 Oral 论文,包含目标检测、图像处理等方向,附打包下载链接。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
CVPR 2022 已经放榜,本次一共有2067篇论文被接收,接收论文数量相比去年增长了24%。在CVPR2022正式会议召开前,为了让大家更快地获取和学习到计算机视觉前沿技术,极市对CVPR022 最新论文进行追踪,包括分研究方向的论文、代码汇总以及论文技术直播分享。
CVPR 2022 论文分方向整理目前在极市社区持续更新中,已累计更新了
535 https://www.cvmart.net/community/detail/6124
paper:https://arxiv.org/abs/2204.00442
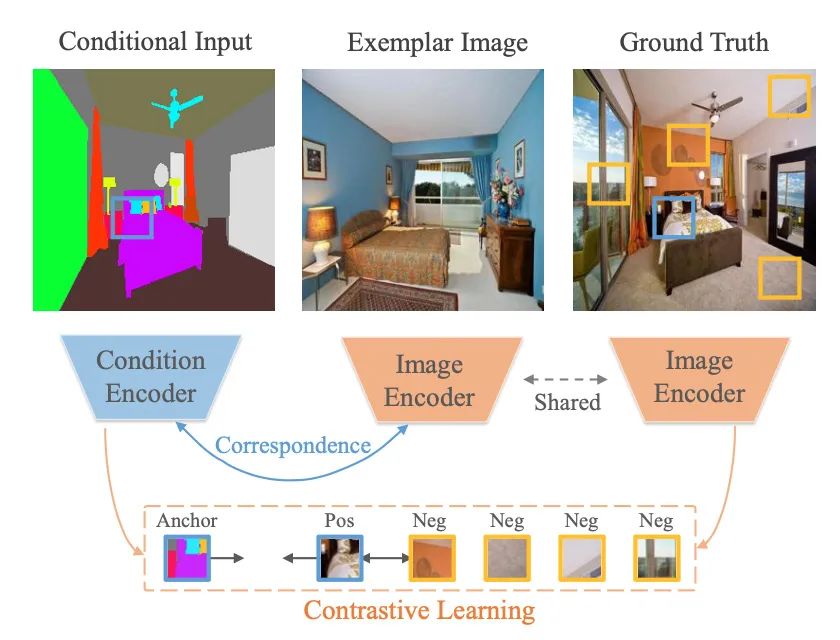
基于示例的图像翻译在条件输入和示例(来自两个不同的域)之间建立了密集的对应关系,以利用详细的示例样式来实现逼真的图像翻译。现有工作通过最小化两个域之间的特征距离来隐式地建立跨域对应关系。如果没有明确利用域不变特征,这种方法可能无法有效地减少域间隙,这通常会导致次优的对应和图像翻译。
本文设计了一个边际对比学习网络(MCL-Net),它通过对比学习来学习领域不变的特征,以此进行基于真实示例的图像翻译。具体来说,作者设计了一种创新的边际对比损失,指导明确地建立密集对应。然而,仅与域不变语义建立对应关系可能会损害纹理模式并导致纹理生成质量下降。因此,作者设计了一个自相关图(SCM),它结合了场景结构作为辅助信息,大大改善了构建的对应关系。对各种图像翻译任务的定量和定性实验表明,所提出的方法始终优于最先进的方法。
paper:https://arxiv.org/abs/2204.01018
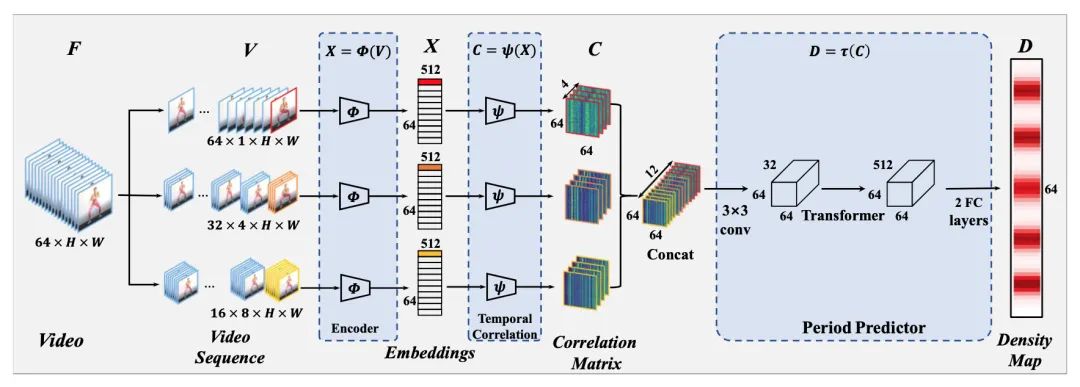
计算重复动作在体育锻炼等人类活动中很常见。现有方法侧重于在短视频中执行重复动作计数,这对于在真实的场景中处理更长的视频是很困难的。在数据驱的时代,这种泛化能力的退化主要归因于缺乏长视频数据集。
因此,本文构建了一个新的大规模重复动作计数数据集,涵盖了各种视频长度,以及视频中出现动作中断或动作不一致等更现实的情况。此外,作者还提供了动作周期的细粒度标签,而不是仅仅计算注释和数值。
这一数据集包含 1,451 个视频和大约 20,000 个标注 。对于更现实场景的重复动作,作者建议使用可以同时考虑性能和效率的Transformer编码多尺度时间相关性。此外,在动作周期的细粒度注释的帮助下,本文提出了一种基于密度图回归的方法来预测动作周期,从而产生更好的性能和足够的可解释性。
paper:https://arxiv.org/abs/2103.14098
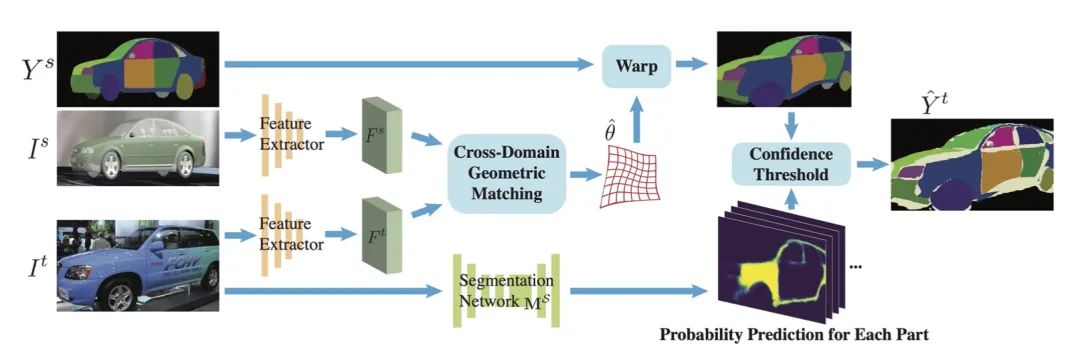
局部分割提供了对象的丰富而详细的局部级描述。然而,局部分割的注释需要大量的工作,这使得很难使用标准的深度学习方法。在本文中,作者提出了
通过合成数据中的无监督域适应 (UDA) 来学习局部分割 的想法。本文首先介绍了 UDA-Part,这是一个全面的车辆局部分割数据集,可以作为 UDA1 的基准。在 UDA-Part 中,作者在 3D CAD 模型上标注局部,来生成大量带注释的合成图像。本文还在许多真实图像上标注局部来提供真实的测试集。其次,为了推进从合成数据训练的局部模型对真实图像的适应,作者引入了一种新的 UDA 算法,该算法利用对象的空间结构来指导适应过程。本文在两个真实测试数据集上的实验结果证实了我们的方法优于现有工作,并证明了从合成数据中学习一般对象的局部分割的前景。
paper:https://arxiv.org/abs/2204.00822
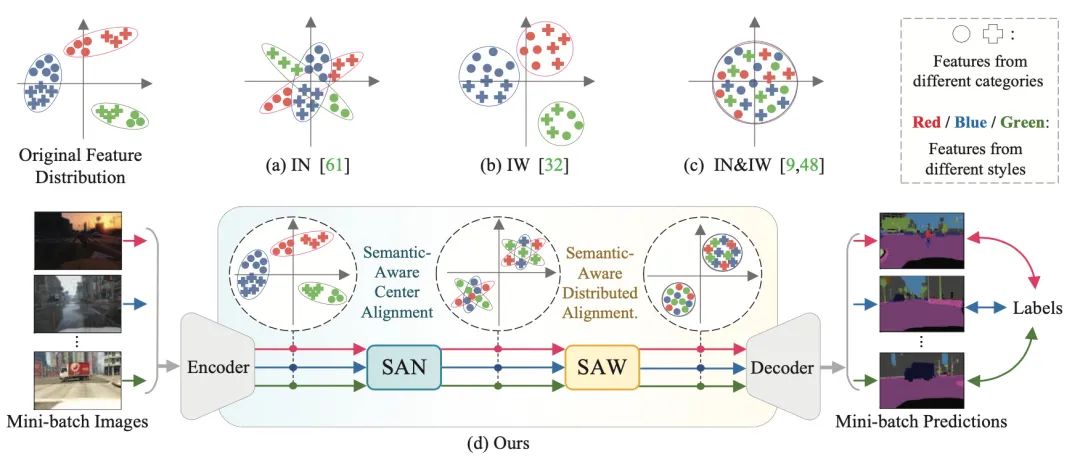
当在具有不同数据分布的看不见的目标域上进行评估时,在源域上训练的深度模型缺乏泛化性。当我们无法访问目标域样本进行适应时,问题变得更加突出。在本文中,作者解决了域泛化语义分割问题,其中分割模型被训练为域不变,而不使用任何目标域数据。解决此问题的现有方法将数据标准化为统一分布。作者认为,虽然这样的标准化促进了全局标准化,但由此产生的特征没有足够的辨别力来获得清晰的分割边界。
为了增强类别之间的分离,同时促进域不变性,本文提出了一个框架,包括两个新模块:语义感知标准化(SAN)和语义感知白化(SAW)。具体来说,SAN 专注于来自不同图像风格的特征之间的类别级中心对齐,而 SAW 对已经中心对齐的特征强制执行分布式对齐。在 SAN 和 SAW 的帮助下,促进类别内的紧凑性和类别间的可分离性。
paper:https://arxiv.org/abs/2104.13586
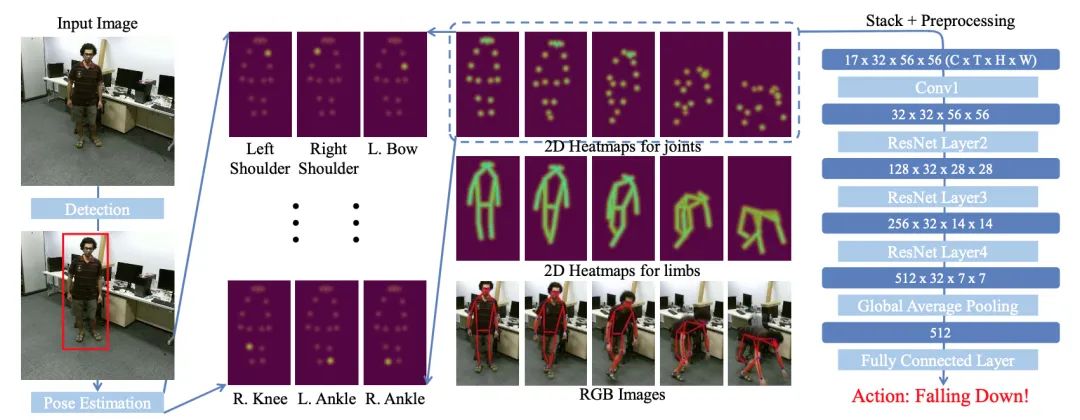
人体骨骼作为人类动作的重要特征,近年来受到越来越多的关注。许多基于骨骼的动作识别方法采用 GCN 在人体骨骼上提取特征。尽管这些尝试获得了积极的结果,但基于 GCN 的方法在鲁棒性、互操作性和可扩展性方面受到限制。
这项工作提出了 PoseConv3D,一种基于骨架的动作识别的新方法。PoseConv3D 依赖于 3D 热图体积而不是图形序列作为人体骨骼的基本表示。与基于 GCN 的方法相比,
PoseConv3D 在学习时空特征方面更有效,对姿态估计噪声更鲁棒,并且在跨数据集中泛化效果更好 。此外,PoseConv3D 可以处理多人场景而无需额外的计算成本。分层特征可以在早期融合阶段轻松地与其他模式集成,为提高性能提供了巨大的设计空间。PoseConv3D 在六个标准的基于骨架的动作识别基准中的五个上达到了最先进的水平。一旦与其他模态融合,它在所有八个多模态动作识别基准上都达到了最先进的水平。
papar:https://arxiv.org/abs/2201.02973
006C3FgEgy1h12cmurshpj31ba0gkdpc
Transformers 和多层感知器 (MLP) 模型的最新进展为计算机视觉任务提供了新的网络架构设计。尽管这些模型在图像识别等许多视觉任务中被证明是有效的,但在将它们用于底层视觉方面仍然存在挑战。支持高分辨率图像的不灵活性和局部注意力的限制可能是主要瓶颈。
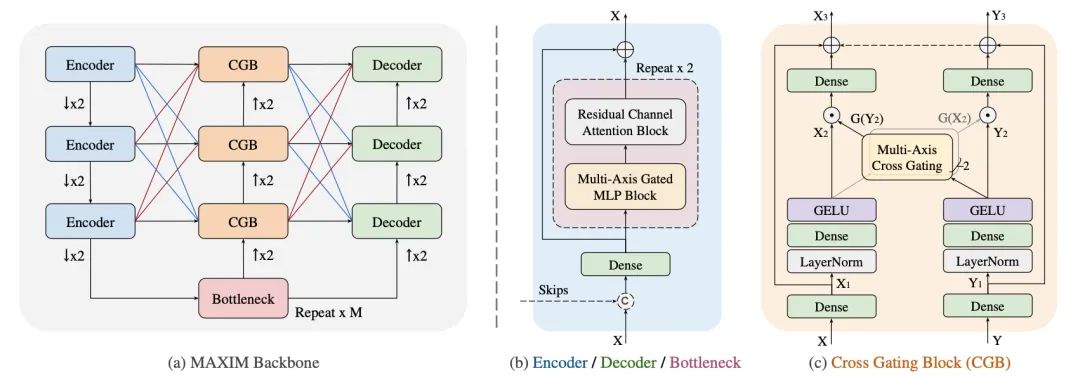
本文提出了一种基于多轴 MLP 的架构,称为 MAXIM,它可以作为
图像处理任务的高效灵活的通用视觉骨干 。MAXIM 使用 UNet 形层次结构并支持由空间门控 MLP 实现的远程交互。具体来说,MAXIM 包含两个基于 MLP 的构建块:一个多轴门控 MLP,允许对局部和全局视觉线索进行有效和可扩展的空间混合,以及一个交叉门控块,它是交叉注意力的替代方案,它解释了用于交叉特征调节。这两个模块都完全基于 MLP,但也受益于全局和“完全卷积”,这是图像处理所需的两个属性。实验结果表明,所提出的 MAXIM 模型在一系列图像处理任务(包括去噪、去模糊、去雨、去雾和增强)的十多个基准上实现了最先进的性能。
paper:https://arxiv.org/abs/2203.07004
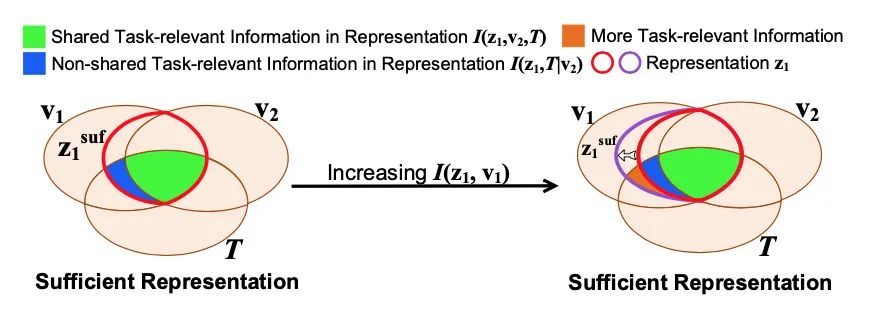
不同数据视图之间的对比学习在自监督表示学习领域取得了显著成功,并且学习的表示在广泛的下游任务中很有用。由于一个视图的所有监督信息都来自另一个视图,因此对比学习近似地获得了包含共享信息的最小充分表示,并消除了视图之间的非共享信息。考虑到下游任务的多样性,不能保证所有与任务相关的信息在视图之间共享。因此,作者假设不能忽略非共享任务相关信息,并从理论上证明对比学习中的最小充分表示不足以满足下游任务,从而导致性能下降。这揭示了一个新问题,即
对比学习模型存在过度拟合视图之间共享信息的风险 。为了缓解这个问题,作者建议增加表示和输入之间的互信息作为正则化,以近似引入更多与任务相关的信息,因为在训练期间不能利用任何下游任务信息。大量的实验验证了本文分析的合理性以及方法的有效性。它显著提高了几种经典对比学习模型在下游任务中的性能。
paper:https://arxiv.org/abs/2112.07471
传统的 3D 可变形人脸模型 (3DMM) 提供了对表情的细粒度控制,但无法轻松捕获几何和外观细节。神经体积表示接近真实感,但难以动画化并且不能很好地推广到看不见的表达。
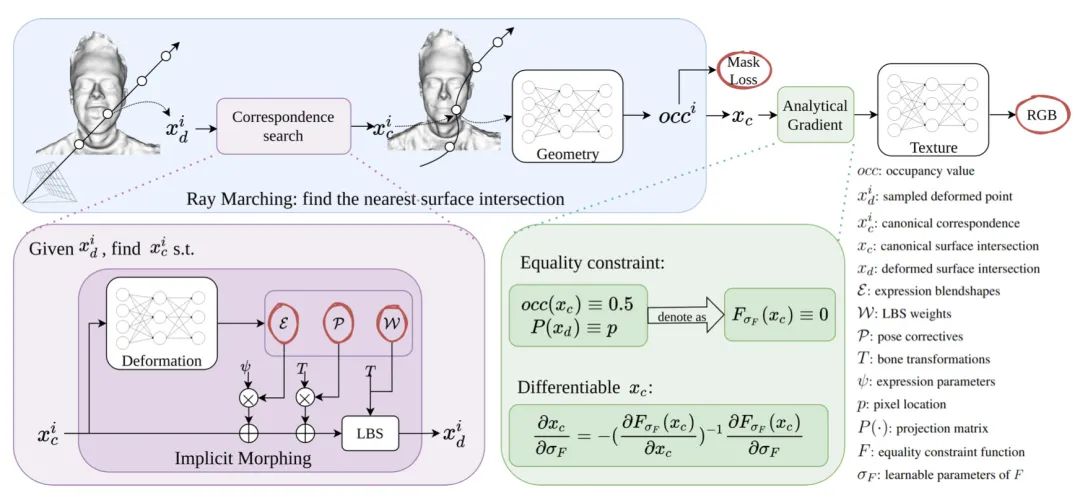
为了解决这个问题,本文提出了 IMavatar(隐式可变形化身),这是一种从单目视频中学习隐式头部化身的新方法。受传统 3DMM 提供的细粒度控制机制的启发,作者通过学习的混合形状和蒙皮字段来表示与表情和姿势相关的变形。这些属性与姿势无关,可用于在给定新的表达式和姿势参数的情况下变形规范几何和纹理场。本文采用光线行进和迭代寻根来定位每个像素的规范表面交点。本文关键贡献是新颖的
梯度分析公式 ,它可以从视频中对 IMavatar 进行端到端训练。定量和定性结果表明,与最先进的方法相比,本文方法改进了几何结构并覆盖了更完整的表达空间。
paper:https://arxiv.org/abs/2201.05718
对于研究人员和从业者来说,训练最先进的视觉模型已经变得非常昂贵。为了可访问性和资源重用,需要重点关注这些模型在各种下游场景的适应性。一个有趣且实用的范例是在线测试时间适应,根据该范式,无法访问训练数据,没有来自测试分布的标记数据可用,并且适应只能在测试时间和少数样本上发生。
本文研究了测试时适应方法如何在各种现实世界场景中对许多预训练模型产生影响,显著扩展了它们最初的评估方式。作者表明,它们仅在狭义的实验设置中表现良好,并且当它们的超参数没有被选择用于测试它们的相同场景时,它们有时会发生灾难性的失败。受测试时最终会遇到的条件的固有不确定性的启发,本文提出了一种特别“保守”的方法,该方法通过拉普拉斯调整最大似然估计 (LAME) 目标来解决问题。通过调整模型的输出(而不是其参数),并通过有效的凹凸程序解决目标。本文方法在各种场景中表现出比现有方法高得多的平均准确度,同时显著更快并且具有更低的内存占用。
paper:https://arxiv.org/abs/2204.01458
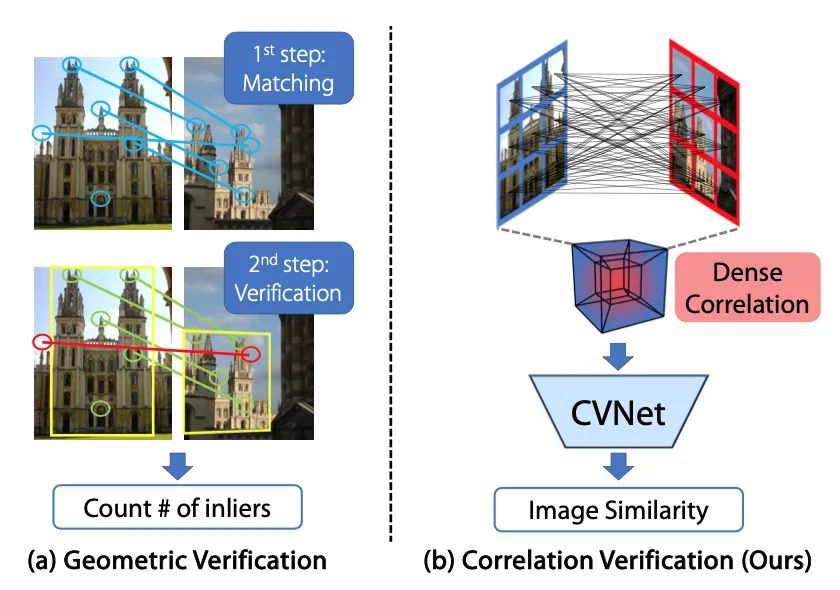
几何验证被认为是图像检索中重新排序任务的解决方案。在这项研究中,作者提出了一种名为 Correlation Verification Networks (CVNet) 的新型图像检索重新排序网络。本文提出的网络由深度堆叠的 4D 卷积层组成,逐渐将密集的特征相关性压缩为图像相似性,同时从各种图像对中学习不同的几何匹配模式。为了实现跨尺度匹配,它构建了特征金字塔,并在单个推理中构建了跨尺度特征相关性,取代了昂贵的多尺度推理。此外,我们使用课程学习与难负挖掘和隐藏策略来处理难样本而不失一般性。
paper:https://arxiv.org/abs/2203.15102
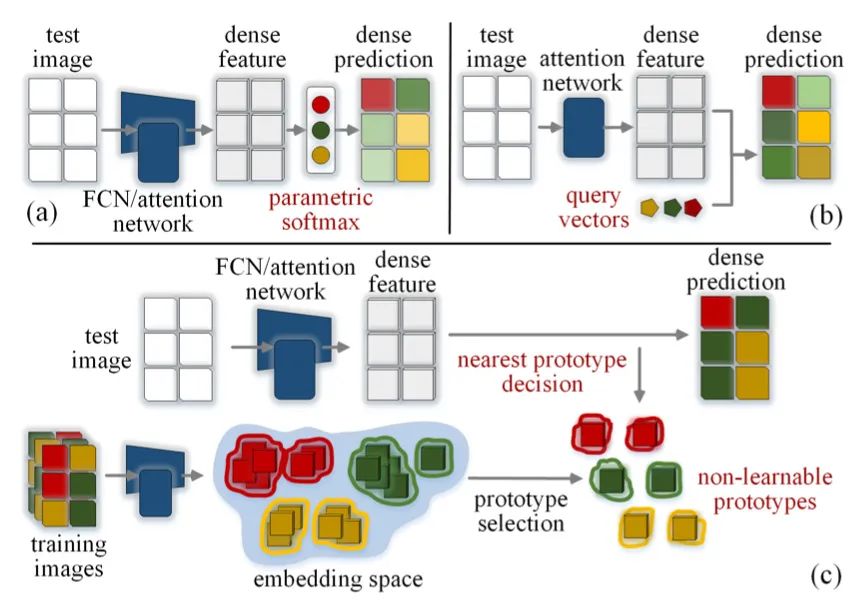
近期流行的语义分割解决方案尽管有不同的网络设计(基于 FCN 或基于注意力)和掩码解码策略(基于参数 softmax 或基于像素查询),但可以通过将 softmax 权重或查询向量视为一类可学习的类原型。鉴于这种原型观点,本研究揭示了这种参数分割方案的几个局限性,并提出了一种基于不可学习原型的非参数替代方案。
本文的模型不是过去以完全参数化的方式为每个类学习单个权重/查询向量的方法,而是将每个类表示为一组不可学习的原型,仅依赖于其中几个训练像素的平均特征类型。因此,密集预测是通过非参数最近原型检索来实现的。这允许本文模型通过优化嵌入像素和锚定原型之间的排列来直接塑造像素嵌入空间。它能够处理具有恒定数量可学习参数的任意数量的类。凭经验证明,使用基于 FCN 和基于注意力的分割模型(即 HR-Net、Swin、SegFormer)和主干网络(即 ResNet、HRNet、 Swin, MiT),本文的非参数框架在多个数据集上产生了令人信服的结果。
paper:https://arxiv.org/abs/2204.02219
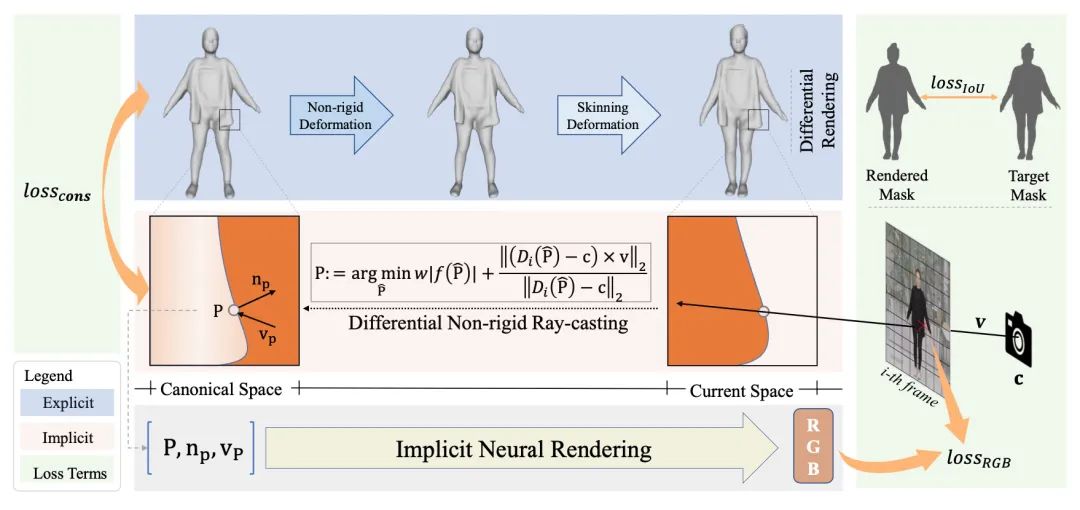
本文提出了一种我监督的方法,来学习参数人体所穿服装的动态 3D 变形。最先进的 3D 服装变形模型数据驱动方法,是使用需要大型数据集的监督策略进行训练的,这些数据集往往通过昂贵的基于物理的模拟方法或专业的多摄像头捕获设置获得。相比之下,本文提出了一种新的训练方案,去除了对真实样本的需求,实现了
动态 3D 服装变形的自监督训练 。
本文主要贡献是认识到传统上由隐式积分器逐帧求解的基于物理的变形模型可以重铸为优化问题。作者利用这种基于优化的方案来制定一组基于物理的损失项,可用于训练神经网络,而无需预先计算真实数据,这使我们能够学习交互式服装的模型,包括动态变形和细皱纹。
paper:https://arxiv.org/abs/2201.12792
本文提出了一种穿着衣服的人体重建方法 SelfRecon,它结合了隐式和显式表示,从单目自旋转人体视频中恢复时空相干几何图形。显式方法需要为给定序列预定义模板网格,而对于特定主题很难获取模板。同时,固定拓扑限制了重建精度和服装类型。隐式表示支持任意拓扑,并且由于其连续性可以表示高保真几何形状。然而,很难整合多帧信息来为下游应用程序生成一致的注册序列。作者建议结合两种表示的优点。利用显式网格的微分掩模损失来获得连贯的整体形状,而隐式表面上的细节则通过可微分的神经渲染进行细化。同时,显式网格会定期更新以调整其拓扑变化,并设计一致性损失来匹配两种表示。与现有方法相比,SelfRecon 可以通过自监督优化为任意穿衣服的人生成高保真表面。广泛的实验结果证明了它对真实捕获的单目视频的有效性。
paper:https://arxiv.org/abs/2204.02148
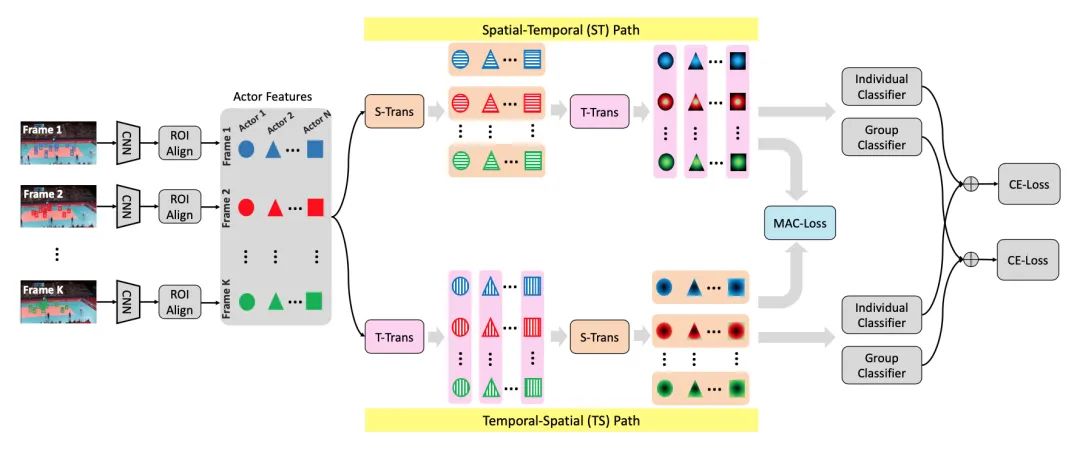
学习多个参与者之间的时空关系对于群体活动识别至关重要。不同的团体活动往往表现出视频中演员之间的多样化互动。因此,通常很难从时空参与者演化的单一视图中对复杂的群体活动进行建模。为了解决这个问题,本文提出了一个独特的双路径演员交互(Dual-AI)框架,它以两个互补的顺序灵活地安排空间和时间转换器,通过整合来自不同时空路径的优点来增强演员关系。此外,在 Dual-AI 的两条交互路径之间引入了一种新颖的多尺度 Actor 对比损失(MAC-Loss)。通过帧和视频级别的自监督演员一致性,MAC-Loss 可以有效地区分个体演员表示,以减少不同演员之间的动作混淆。因此,Dual-AI 可以通过融合不同参与者的这种区分特征来提高群体活动识别。
paper:https://arxiv.org/abs/2203.01441
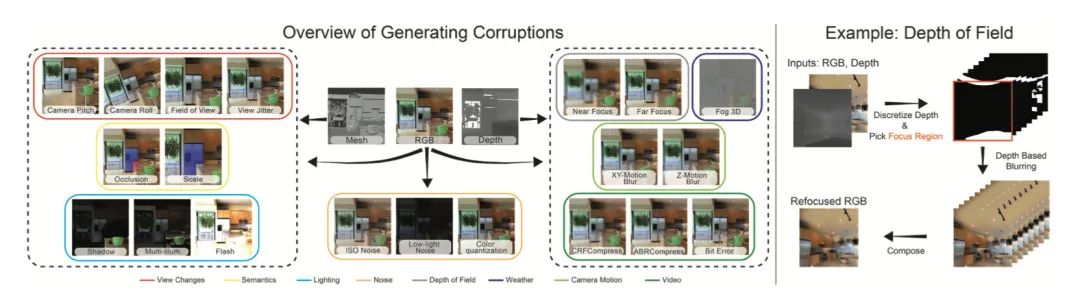
本文引入了一组图像转换,可用作评估模型鲁棒性的损坏以及用于训练神经网络的数据增强机制。所提出的转换与现有方法在于场景的几何形状被纳入转换中,从而导致更可能发生在现实世界中的损坏。此外还引入了一组语义损坏。本文证明了这些转换是“高效的”(可以即时计算)、“可扩展”(可以应用于大多数图像数据集),并暴露了现有模型的脆弱性。
paper:https://arxiv.org/abs/2112.05143
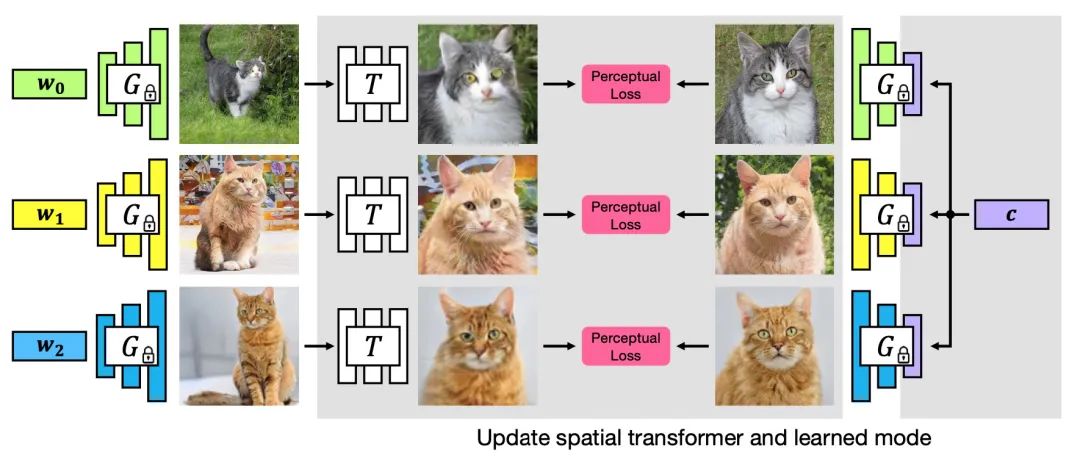
本文提出了一个用于学习判别模型及其 GAN 生成的训练数据端到端联合的框架。并将此框架应用于密集的视觉对齐问题。受经典 Congealing 方法的启发,GANgealing 算法训练了一个空间Transformer,把来自在未对齐数据上训练的 GAN 中的随机样本映射到一个常见的联合学习目标模式。文章展示了八个数据集的结果,均证明了本文方法成功地对齐了复杂的数据并发现了密集的对应关系。GANgealing 显著优于过去的自监督对应算法,并且在多个数据集上的性能与(有时甚至超过)最先进的监督对应算法相当——不使用任何对应监督或数据增强,尽管专门针对 GAN 生成的数据进行训练。
paper:https://arxiv.org/abs/2203.17008
模型量化被认为是一种很有前途的方法,可以大大降低深度神经网络的资源需求。为了应对量化误差导致的性能下降,一种流行的方法是使用训练数据对量化网络进行微调。然而,在现实世界环境中,这种方法通常是不可行的,因为由于安全、隐私或机密性问题,训练数据不可用。零样本量化解决了此类问题,通常通过从全精度教师网络的权重中获取信息来补偿量化网络的性能下降。
在本文中,作者首先分析了最先进的零样本量化技术的损失面,并提供了一些发现。与通常的知识蒸馏问题相比,零样本量化通常存在以下问题:1难以同时优化多个损失项,以及由于使用合成样本,泛化能力较差。此外,作者观察到许多权重在训练量化网络期间未能跨越舍入阈值,即使有必要这样做以获得更好的性能。
基于观察,本文提出了 AIT,这是一种简单而强大的零样本量化技术,它通过以下方式解决上述两个问题:AIT 仅使用 KL 距离损失而没有交叉熵损失,以及操纵梯度以保证在超过舍入阈值后正确更新权重的某一部分。实验表明,AIT 大大优于许多现有方法的性能。
paper:https://arxiv.org/abs/2203.16507
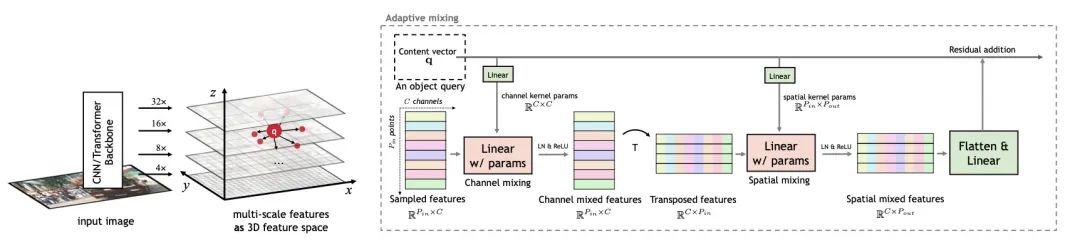
传统的物体检测器采用密集模式扫描图像中的位置和尺度。最近基于查询的对象检测器通过使用一组可学习的查询解码图像特征来打破这一惯例。然而,这种范式仍然存在收敛速度慢、性能有限以及骨干网和解码器之间额外网络的设计复杂性的问题。在本文中,我们发现解决这些问题的关键是解码器对将查询转换为不同对象的适应性。
因此,本文提出了一种快速收敛的基于查询的检测器AdaMixer,在两个方面提高基于查询的解码过程的适应性:首先,每个查询都根据估计的偏移量自适应地对空间和尺度上的特征进行采样,这使得 AdaMixer 能够有效地处理对象的连贯区域。然后,在每个查询的指导下使用自适应 MLP-Mixer 动态解码这些采样特征。由于这两个关键设计,AdaMixer 享有架构简单性,而不需要密集的注意力编码器或显式金字塔网络。
paper:https://arxiv.org/abs/2112.08177
多视图深度估计方法通常需要计算多视图成本量,这会导致巨大的内存消耗和缓慢的推理。此外,对于无纹理表面、反射表面和移动物体,多视图匹配可能会失败。对于这种故障模式,单视图深度估计方法通常更可靠。为此,本文提出了 MaGNet,这是一种将单视图深度概率与多视图几何融合的新框架,以提高多视图深度估计的准确性、鲁棒性和效率。对于每一帧,MaGNet 估计一个单视图深度概率分布,参数化为像素级高斯分布。然后使用为参考帧估计的分布来对每个像素的深度候选进行采样。这种概率采样使网络能够在评估更少的深度候选时获得更高的准确度。本文还提出了多视图匹配分数的深度一致性加权,以确保多视图深度与单视图预测一致。
paper:https://arxiv.org/abs/2204.00746
我们提出了一种新颖的基于 Transformer 的语义和空间精炼Transformer (SSRT) 来解决人与对象交互检测任务,该任务需要定位人和对象,并预测它们的交互。与以前的基于 Transformer 的 HOI 方法不同,这些方法主要侧重于改进解码器输出的设计以进行最终检测,SSRT 引入了两个新模块来帮助选择图像中最相关的对象-动作对并优化查询。使用丰富的语义和空间特征表示。
公众号后台回复“ 画图模板 ”获取90+深度学习画图模板~
备注: 姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市 目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解 等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+ 来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~