吃下文本吐出语音,DeepMind提出新型端到端TTS模型EATS
机器之心编译
参与:小舟、魔王
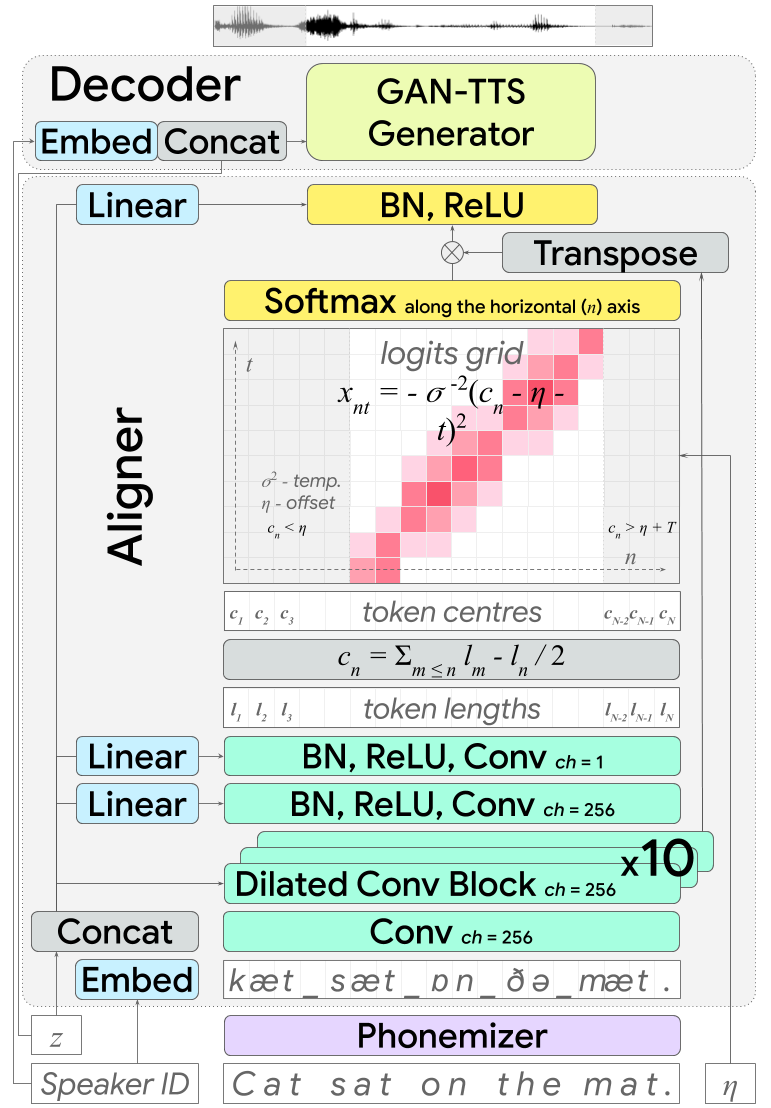
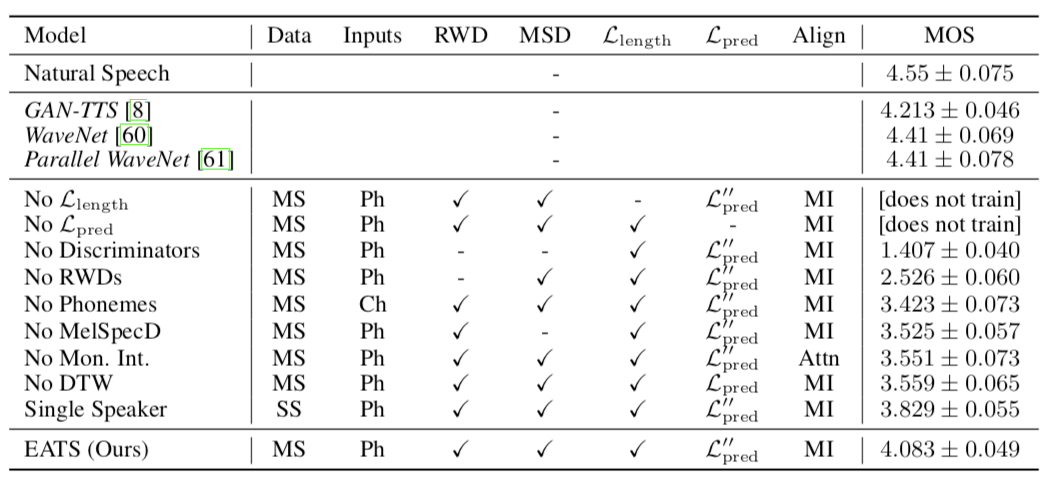
如何以端到端方式训练 TTS 系统?DeepMind 发起了挑战。其提出的 EATS 模型可在纯文本或者暂未对齐的原始音素输入序列上运行,并输出原始语音波形。

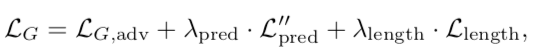

登录查看更多
相关内容
专知会员服务
131+阅读 · 2020年4月19日
专知会员服务
37+阅读 · 2020年2月27日
专知会员服务
22+阅读 · 2020年1月15日
Arxiv
3+阅读 · 2020年3月4日
Arxiv
5+阅读 · 2019年10月31日




相关VIP内容
专知会员服务
131+阅读 · 2020年4月19日
专知会员服务
37+阅读 · 2020年2月27日
专知会员服务
22+阅读 · 2020年1月15日
相关资讯
相关论文
Arxiv
3+阅读 · 2020年3月4日
Arxiv
5+阅读 · 2019年10月31日