读书报告 | CN-DBpedia: A Chinese Knowledge Extraction System

论文信息
CN-DBpedia: A Never-Ending Chinese Knowledge Extraction System
作者:Bo Xu1, Yong Xu1, Jiaqing Liang1,2, Chenhao Xie1,2, Bin Liang1, Wanyun Cui1, and Yanghua Xiao
学校:复旦大学
简介
这篇论文利用现存的英文知识图谱DBpedia,提出了一种不需要过多人力参与的框架,来从百度百科等中文百科中构建中文知识图谱。
其中比较关键的两个步骤:1.对于实体进行类型推断 2.从文本中抽取关系
框架
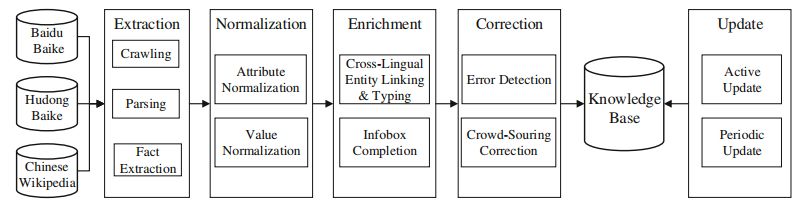
抽取:包括爬取网页,解析网页,抽取结构化的信息
归一化:对于表达相同概念的属性和属性值进行归一化
补充:进行跨语言的实体链接和实体类型推断
改正:1.基于规则的改正(如要求主谓语的类型匹配)。2.基于用户反馈
更新:基于当前网络中的热点对知识图谱进行动态更新
类型推断
类型推断是实体在知识图谱中的重要语义信息,需要应用都需要用到这个信息。传统的方法依赖大量的标注数据,而本论文利用DBpedia来自动构造一个可用的标注数据。
步骤:
依据DBpedia中的实体和中文实体的名字的完全匹配,找到一些匹配的实体对。那么DBpedia中的实体类型就可以赋予给对应的中文实体。
依据以下特征训练一个多类分类器。
中文实体的种类(歌手,演员)
实体属性(职业)
实体属性和属性的值(职业——演员)
关系抽取
使用中文实体的infobox信息作为distant supervision的已知知识,对每种关系单独训练一个宾语抽取器。使用的模型是BI-LSTM。 distant supervision: 若三元组⟨Leonardo DiCaprio, BirthPlace, Hollywood⟩出现在Leonardo DiCaprio的infobox中,那么就可以标注句子... DiCaprio was born in Hollywood, California, the only child of ...中的Hollywood和California是BirthPlace的宾语。
总结
这篇论文提出的利用现有的英文源知识图谱构建中文知识图谱的方法是可以借鉴的。但是论文对其中比较重要的归一化是如何做的并没有说明。我在他们开放的API网站进行搜索,但是搜索到的实体关系都是在百度的infobox中可以找到的。
作者:李浩然,北京大学在读硕士。





