【论文】Awesome Relation Classification Paper(关系分类)(PART II)
作者:高开远
学校:上海交通大学
研究方向:自然语言处理
0. 写在前面
上一篇【论文】Awesome Relation Extraction Paper(关系抽取)(PART I)介绍了一些关系抽取和关系分类方面的经典论文,主要是以CNN模型为主,今天我们来看看其他模型的表现吧~
1. Relation Classification via Recurrent Neural Network(Zhang 2015)
考虑到CNN对于文本序列的长距离建模不够理想,作者提出使用RNN来进行关系分类的建模。整体框架如下:包括了word embedding layer---> Bi-RNN layer---> Max Pooling layer。

整体属于比较简单易懂的RNN传统框架,并没有加什么其他trick。相较于之前的Position Embedding,这里使用了Position indicators来替换,这是因为在RNN中,单词之间的位置信息已经会被自动地建模进去。PI就是使用四个标签来标记两个实体对象,比如对于句子:people have been moving back into downtown在加入PI之后变成了<e1> people </e1> have been moving back into <e2> downtown </e2> ,其中<e1>, </e1>, <e2>, </e2>就是标签,在训练的时候直接将这四个标签当成普通的单词即可。
试验分析

3.Bidirectional Recurrent Convolutional Neural Network for Relation Classification(Cai/ACL2016)
提出了一种基于最短依赖路径(shortest dependency path, SDP)的深度学习关系分类模型,文中称为双向循环卷积网络(bidirectional recurrent convolutional neural networks,BRCNN)。

在每个RCNN中,将SDP中的words和 words之间的dependency relation 分别用embeddings表示,并且将SDP中的words之间的dependency relation 和words分开到两个独立channel的LSTM,使它们在递归传播的时候不互相干扰。在convolution层把相邻词对应的LSTM输出和它们的dependency relation的LSTM输出连结起来作为convolution层的输入,在convolution层后接max pooling。在pooling层后接softmax分类,共有三个softmax分类器,两个RCNN的pooling分别接一个softmax做考虑方向的(2K + 1)个关系分类,两个RCNN的pooling连到一个softmax做不考虑方向的(K + 1)个关系分类。
4. Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification(Zhou/ACL2016)
这篇文章使用的是LSTM,避免了RNN在处理长文本时存在的梯度消失问题。另外加入了attention layer可以更有效地关注实体对之间的关系。整体框架如下图

几个层的组件都是现在做nlp非常主流的成分,也可以参考我之前的博客,而且文章中也没有涉及什么tricks。整个模型可以分为以下几层:
Embedding层:为了与之前的模型作比较,本文选取的词向量为senna-50和glove-100
Bi-LSTM层:输入为embedding层的句子向量表示,输出为每个时间步前向后向网络hidden state的逐元素相加;
Attention层:vanilla attention,其中key和value为BiLSTM层的输出向量,query为自定义的可训练的向量
Output层:使用softmax和交叉熵损失
文章中提出的BiLSTM + Attention可以做为很多NLP 任务的baseline,效果强大。
试验分析
在SemEval-2010 Task 8上取得了84%的F1值,可以说是效果非常好了。

CODE HERE
ON THE WAY…
5. Relation Classification via Multi-Level Attention CNNs(Wang/ACL2016)
使用CNN+Attention来实现关系分类,设计了较为复杂的两层attention操作,第一层是输入attetion,关注实体与句子中单词之间的联系;第二层是卷积之后的attention pooling,关注的是标签与句子之间的关联。另外在模型的损失函数部分,作者也单独自定义了一个loss,改进了之前提及的margin-based ranking loss。模型整体框架如下所示,下面我们将其分解来仔细看一下是怎么运行的。

Input Representation
模型输入是一个句子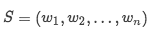
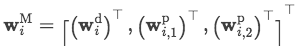
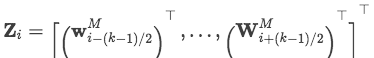
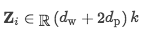
Input Attention Mechanism
经过预处理后得到我们的输入表示应该就像上图中的最下层的矩阵的形式了,然后对其进行第一层attention操作提取实体与单词的关联信息。

首先定义两个对角矩阵A^1和A^2,对应两个实体。其中矩阵中对角线元素表示为句子中单词i同该实体之间的关联性,具体是通过单词和实体word embedding的內积计算而来
网络训练的目标之一就是这两个对角矩阵
通过softmax归一化计算句子中每个单词相对不同实体的权重
这样每个词都存在两个权重系数,分别对应两个实体。用这两个权重去和输入矩阵Z进行交互,文中给出了三种交互形式:
average:
concat:
quadratic difference:
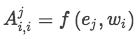
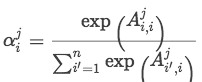
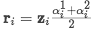
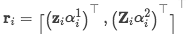
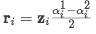
经过第一层attention后句子表示为
Convolution Layer
卷积层就跟普通的一样没什么trick的设计啦
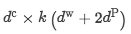
Attention-Based Pooling
在经过卷积层之后一般都需要pooling一下,这里没有选择普通的average或者max pooling,而是利用attention来融入最终标签W_L的信息
首先通过卷积后的矩阵与标签矩阵交互得到一个相似性矩阵G,形状为【n, L】
,其中U为需要学习的矩阵
softmax归一化处理矩阵G,得到attention score
最后用attention score与卷积之后的矩阵相乘,选择每一维最大的值作为输出
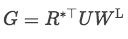
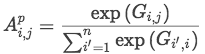
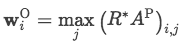
Loss function
首先对于标签信息映射了一个向量矩阵W_L, 形状为【d^L,L】,也就是对应每一种关系都有一列向量表示。同样地,在我们网络的输出也是每一类实体关系的向量。基于这两个向量,可以学习他们之间的距离: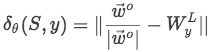
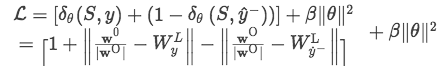
试验分析
数据集也是SemEval-2010 Task 8

小结
考虑到CNN提取信息能力有限,设计了两层Attention来补充,与文本分类的《Hierarchical Attention Networks for Document Classification》有些像;
针对该任务自定义了损失函数,效果比使用传统softmax+cross entropy有所提升;
在设计Input attention过程,两个矩阵A1和A2完全可以使用一维的向量,不懂为什么要设计成对角矩阵;
SemEval-2010 Task 8 上的 F1 值达到了 88
CODE HERE
ON THE WAY…
原文链接:
本文由作者原创授权AINLP首发于公众号平台,点击'阅读原文'直达原文链接,欢迎投稿,AI、NLP均可。




