知识图谱补全是一类重要的问题。近年来基于图神经网络的知识图谱表示得到了很多关注。这边综述论文总结了图神经网络知识图谱补全的工作,值得查看!
摘要:知识图谱在诸如回答问题和信息检索等各种下游任务中越来越流行。然而,知识图谱往往不完备,从而导致性能不佳。因此,人们对知识库补全的任务很感兴趣。最近,图神经网络被用来捕获固有地存储在这些知识图谱中的结构信息,并被证明可以跨各种数据集实现SOTA性能。在这次综述中,我们了解所提出的方法的各种优势和弱点,并试图在这一领域发现新的令人兴奋的研究问题,需要进一步的调研。
知识库是以关系三元组形式的事实信息的集合。每个关系三元组可以表示为(e1,r,e2),其中e1和e2是知识库中的实体,r是e1和e2之间的关系。最受欢迎的知识库表示方式是多关系图,每个三元组(r e1, e2)是表示为有向边从e1, e2与标签r。知识图谱被用于各种下游任务。
然而,由于知识库是从文本中自动挖掘来填充的,它们通常是不完整的,因为不可能手动编写所有事实,而且在提取过程中经常会出现不准确的情况。这种不准确性会导致各种下游任务的性能下降。因此,大量工作开发一种有效的工具来完成知识库(KBs)方面,它可以在不需要额外知识的情况下自动添加新的事实。这个任务被称为知识库补全(或链接预测),其目标是解决诸如(e1,r,?)这样的查询。
第一种实现高效知识库补全的方法是像TransE (Bordes et al.(2013))和TransH (Wang et al.(2014))这样的加法模型,其中关系被解释为隐藏实体表示的简单翻译。然后观察到,诸如Distmult (Yang et al.(2015))和Complex (Trouillon et al.(2016))等乘法模型优于这些简单的相加模型。与平移不同,旋转(Sun等人(2019a))将关系定义为简单的旋转,这样头部实体就可以在复杂的嵌入空间中旋转来匹配尾部实体,这已经被证明满足了很多有用的语义属性,比如关系的组合性。最近,引入了表达性更强的基于神经网络的方法(如ConvE (Dettmers等人(2018))和ConvKB(Nguyen等人(2018)),其中评分函数与模型一起学习。然而,所有这些模型都独立地处理每个三元组。因此,这些方法不能捕获语义丰富的邻域,从而产生低质量的嵌入。
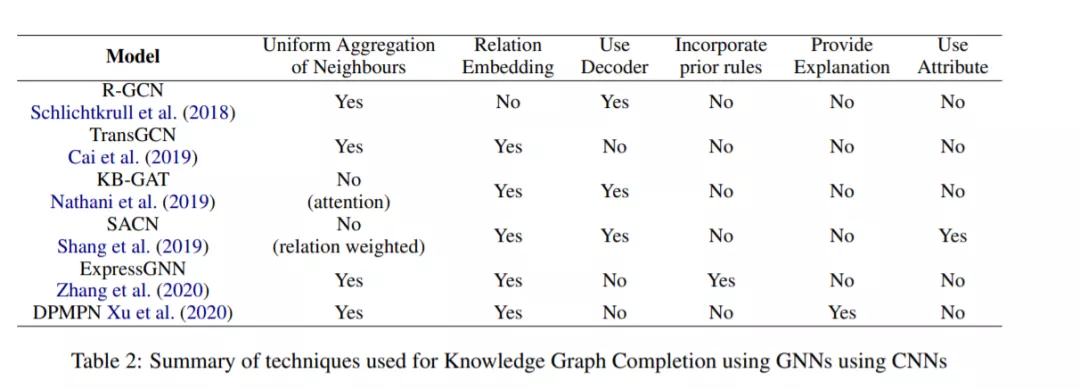
图已被广泛用于可视化真实世界的数据。在将ML技术应用于图像和文本方面已经取得了巨大进展,其中一些已成功应用于图形(如Kipf和Welling(2017)、Hamilton等人(2017)、Velickovic等人(2018)。基于该方法的启发,许多基于图神经网络的方法被提出用于KBC任务中获取知识图的邻域。在这次调查中,我们的目的是研究这些工作。