纯贝叶斯神经网络没有意义?OpenAI科学家何出此言?
选自Buckman's Homepage
参与:魔王
近日,OpenAI 研究科学家 Carles Gelada 发布推文,表示「贝叶斯神经网络没有意义」。一石激起千层浪,社区对此言论展开了激烈的讨论。那么贝叶斯神经网络真的没有意义吗?Carles Gelada 何出此言?我们来看这篇文章。
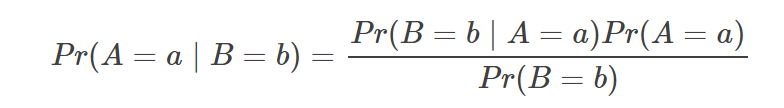
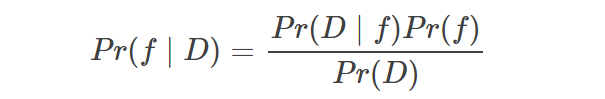
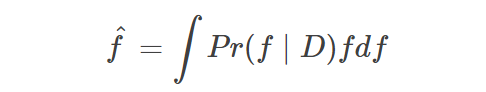
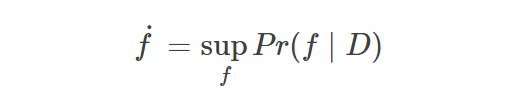
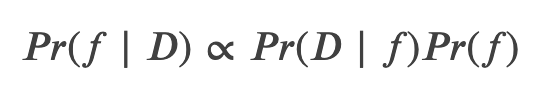
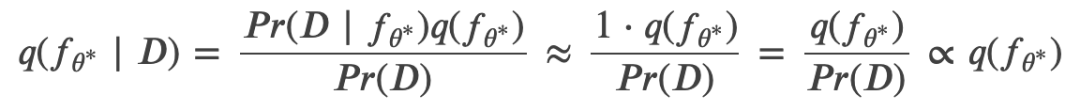
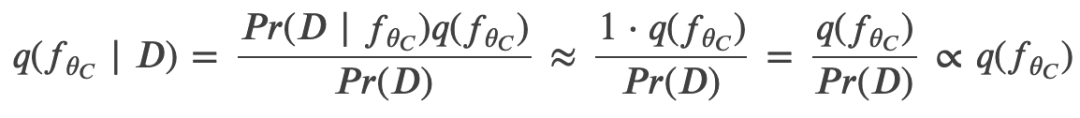
登录查看更多
相关内容
专知会员服务
54+阅读 · 2020年3月5日



相关VIP内容
专知会员服务
54+阅读 · 2020年3月5日
相关资讯
相关论文