自监督视觉特征学习

自监督学习是近年兴起的一种深度学习方法。它是无监督学习的一个分支,其最大特点是不依赖人工标注的数据标签直接从原始数据中自动学习有区分度的特征表示。

01
自监督学习的定义
自监督学习是一种将输入数据本身作为监督信号的表示学习方法,与监督式学习、无监督学习一样,属于表示学习的范畴。尽管监督式学习这种范式能够取得很好的效果,但它的优越性能依赖大量手工标注的数据,而获取这些标注数据需要消耗大量的人力物力,以至于会有人开玩笑称“有多少人工就有多少智能”。
相比之下,随着信息科技的发展,大量无标注数据往往可以被人们轻松获取。无监督学习希望能够利用这些无标注数据来学习有用的特征表示,聚类就是一种经典的无监督学习方法。然而,传统的无监督方法往往性能有限,很难在大规模数据上学习到具有很强泛化性的特征表示。在这样的背景下,自监督学习逐渐走上历史的舞台。
自监督任务是自监督学习的核心部分,其定义了由无标注数据中产生自监督信号的方法,以及自监督学习的优化目标。常见的自监督任务可以大致分为两类:
(1)生成式任务,例如:将输入图片转换为黑白图像,训练模型恢复出原图(上色);输入部分区域被裁出的图像,训练模型恢复出被裁出区域的内容。(2)判别式任务,例如:输入经过随机旋转的图片,训练模型预测其旋转的角度;输入两张经过不同数据增强的图片,训练模型判断它们的对应的原图是否为同一张图片。
自监督学习训练模型从数据本身发现规律,并学习特征表示,使其能够被有效运用到下游任务上。最近几年,以对比学习为代表的判别式方法在自监督学习领域大放异彩,本文将着重介绍基于对比学习以及聚类方法的主流自监督学习框架。
02
自监督学习中的对比学习方法
对比学习是自监督学习中的一个重要方法,其核心思想是通过样本的相似性来构建表征。对于相似的输入样本,它们由网络产生的表征也应当相似;而对于差异较大的输入样本,它们的表征也应该存在较大区别。根据这一思想,很多基于对比学习的自监督学习方法被提出(如MoCo、SimCLR、BYOL),并对这一领域产生了深远影响。
对比学习中的一个关键步骤是构建正负样本集合,对于一个输入样本

图 1 负样本对和正样本对示意图[1]
完成正负样本的构建后,对比学习一般采用InfoNCE Loss来进行损失计算和模型更新,其形式如下:
其中
1. MoCo [2]
MoCo是对比学习中一个非常有代表性的方法,其主要思想是将对比学习过程看作一个“查字典”的过程:在一个由众多样本构成的键值(key)字典中检索到与查询样本的编码结果(query)相匹配的正样本。为了提升对比学习的效果,作者提出了两点假设:第一,键值字典的容量应该尽可能增大以提高自监督任务的难度,从而提升训练效果;第二,键值字典应该在训练过程中保持一定程度的一致性以保障自监督学习过程能够稳定进行。
基于以上两点假设,作者分析了几种对比学习机制(如图 2 所示)。第一种是端到端训练,即对于所有的查询样本的编码结果(query)和字典键值(key)同时进行梯度传播,但这一方法中显存大小会极大地限制键值字典的大小,导致自监督任务难度降低,影响训练效果;第二种是基于memory bank的训练方法,迭代过程中将键值编码存储到一个memory bank中,每轮对比学习过程中所需要的字典键值直接从memory bank 里选取,而梯度计算只对查询样本的编码网络分支进行。因为MoCo不需要对键值字典的分支进行梯度计算,memory bank方法可以显著提升键值字典的容量,但是由于每个样本在memory bank中的键值在被模型重新编码时才会被更新,键值字典中键值间的一致性较差,从而降低了训练的稳定性。
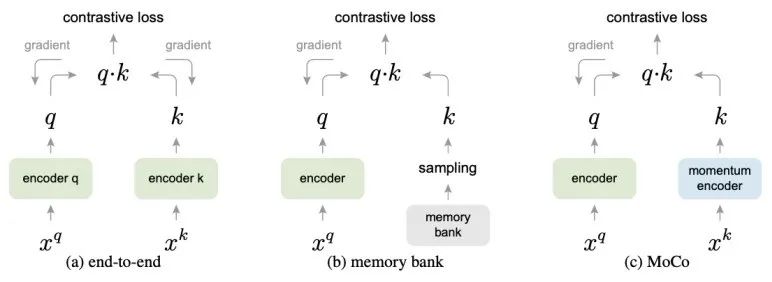
图2 三种对比学习机制的比较[2]
因此,作者提出了一种momentum encoder来实现对键值字典的编码。对于查询样本,使用普通encoder进行编码并直接进行梯度计算;而对于键值字典,首先由一个动态更新的队列维护字典的输入样本,再使用momentum encoder将样本编码为键值。Momentum encoder在训练过程中不会进行梯度计算,而是采用动量更新的方法从encoder更新参数,更新方法如下:
其中,
值得一提的是,在实验过程中作者发现传统的batch normalization方法可能造成样本信息的泄露,让数据样本意外地“看到了”其他样本。这样会使模型在自监督任务中更倾向于选择一个合适的batch normalization参数,而不是学习一个比较好的特征表示。所以,作者提出了一个shuffling batch normalization的方法,即打乱训练样本在encoder和momentum encoder中的装载顺序,使得同一样本在计算query和key时中接收不同的batch normalization均值和方差,来抵消信息泄露所带来的影响。
2. SimCLR [3]
SimCLR 是一个非常简洁的自监督学习框架。它没有建立类似MoCo的键值字典的方式,而是直接在每个batch中的样本之间进行比较学习。对于
网络结构上,与MoCo相比,SimCLR在backbone网络末端新增了一个由两层全连接层构成的projection head,如图 3 所示。模型在训练阶段,根据projection head的输出
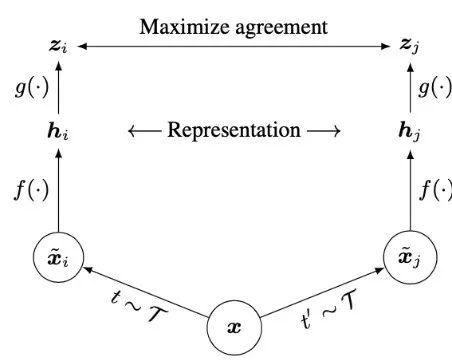
图3 SimCLR自监督学习框架[3]
SimCLR在文章中还研究了不同数据增强策略对自监督学习结果的影响。作者比较了随机裁切,旋转,色彩偏移,高斯噪声等方法,最终发现采用随机裁切和色彩偏移两种方法的组合时训练效果最好。
3. BYOL [4]
BYOL是一个非常有特点的模型,与MoCo、SimCLR相比,BYOL可以直接在正样本对上进行自监督训练而不需要构建负样本集合。BYOL的构想来自于一个非常有意思的发现:在一个完全随机初始化的网络所输出的特征上进行分类任务的top-1准确率只有1.4%;但如果将这个随机初始化网络的输出特征作为目标,用另一个网络对其进行学习,使用学习之后的网络进行特征提取再进行分类可以达到18.8%的准确度。换言之,以一个特征表示作为目标进行学习,可以获得一个更好的表示。如此继续迭代下去,精确度可以继续往上提升。
基于这一发现,作者构建了只需要正样本对的BYOL学习框架。如图 4所示,一张输入图片经过不同数据增强后的两个视图分别经过online和target两个分支的backbone和projection head后得到输出
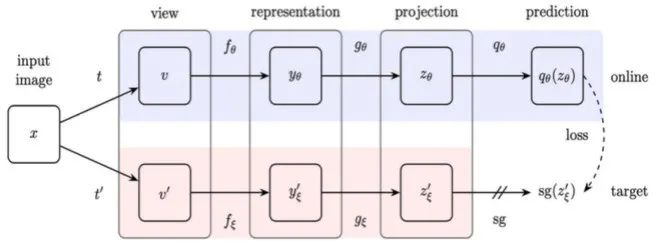
图4 BYOL自监督学习框架[4]
三、自监督学习中的聚类方法
与对比学习或者人工设置的前置任务(pretext task)的学习方式不同,基于聚类的自监督方法将训练样本按照某种相似度量进行划分,划归到不同聚类中心的样本被赋予不同的类别标签,之后使用标准的全监督学习交叉熵损失进行训练。文献[5]中用数学语言形式化的展示了全监督学习与自监督聚类之间的联系与区别:考虑深度模型
具体来讲,假设有N个样本
其中,模型
来进行优化。由于交叉熵损失需要给出目标的类别标签(标注数据集),对于无标注数据,我们需要首先通过某种分配方式赋予每个样本具有一定意义的标签然后才能进行训练。用
一般而言,我们令
稍微细心的读者会发现,这种方式下存在令模型退化的解:给所有的样本赋予相同标签之后优化模型参数就可以最小化平均损失函数。此时,模型将所有样本均映射到特征空间中的同一位置附近,不同样本之间的特征区分度变得微弱,模型性能严重退化,不能达到学习出有意义特征表示的目的。因此,基于聚类的自监督学习方法关键在于引入适当的约束条件,避免模型收敛到退化解。
Deep clustering[6]是第一个成功的深度自监督聚类方法(见图 5),该方法包含两个步骤:第一步,将所有训练数据通过深度模型推理得到特征表示,在特征空间中使用K-means方法将每个样本划分到一个聚类中,其所属聚类即为该样本对应的标签;第二步,基于上一步产生的伪标签重新训练深度模型。这两个步骤交替迭代。为了防止收敛至退化解,文中提出两个关键的启发式方案:第一,固定聚类中心个数,如果在聚类过程中某一聚类变为空,就随机选取其余聚类的中心(加上小的随机扰动)来代替空聚类;第二,如果某个聚类中包含的样本过多,那么它所对应的梯度会主导整个网络的参数学习。为了避免这个问题,作者在模型训练梯度回传时会根据聚类大小调整梯度回传量,平衡不同类别样本之间的数量差异。
作者提出使用归一化互信息(Normalized Mutual Information, NMI)来衡量模型的学习效果。NMI定义为
其中AB分别代表一种标签分配方式,I表示互信息,H代表熵。如果A分配方式下得到的标签与B分配方式得到的标签完全独立,则NMI值为0;相反的,如果对任意样本,在A分配方式下得到的标签可以完全确认其在B分配方式下所对应的标签,则NMI值为1。当A、B 分别代表样本真实标签和聚类标签时,NMI可以反映出模型学习到的特征对于真实类别的刻画能力。当A、B 分别代表上一轮训练之后模型输出特征得到的聚类标签与本轮得到的标签,NMI可以反映模型特征的稳定性。具体实验结果请查阅原论文。
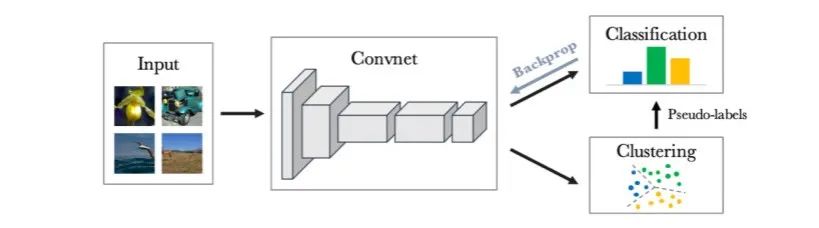
图5 Deep clustering 方法执行示意图
Deep clustering方法第一次成功实现了聚类标签与特征表示的同步学习,取得了很好的实验效果,但仍然存在一些缺陷:一方面该方法需要人工定义的启发式方法来避免模型收敛至退化解;另一方面,K-means与模型训练交替进行,模型没有一个统一的优化目标。针对这些问题,文献[5]提出了一种名为SeLa的方法:通过对聚类中的标签分配添加等分约束——每个聚类中元素个数必须相同,来强制模型学得有区分性的特征,从而避免了收敛至退化解的可能。具体来讲,该方法在原目标函数上添加了约束项,新的优化目标为:
直观上来看, 满足条件的q的分配方式与样本个数和标签种类构成一个排列组合问题,该问题的求解会随着样本个数的增加而变的困难。幸运的是,该优化问题属于最优传输问题的一个实例,使用Sinkhorn-Knopp[7]方法可以快速求得该问题的解,其对应的分配方式即为满足上述目标函数的最优解。接下来将展示上述问题如何转化为一个最优传输问题。令
这里
与Deep Clustering方法相比,SeLa的最大优势在于其统一的目标函数,模型的收敛程度可以直接由目标函数反映。具体实验内容请参见原论文。
聚类思想也可以在对比学习中使用:SimCLR、 MoCo等对比学习方法要取得良好的效果需要足够大的batch size 或 memory bank来存储负样本,因此对硬件提出了较高的要求。如果对负样本先进行聚类,用数量较少的聚类中心来近似替代全体负样本,则可以很大程度减少对硬件存储空间的要求。基于这一思路,学者们提出了SwAV[8]方法(图 6 )。
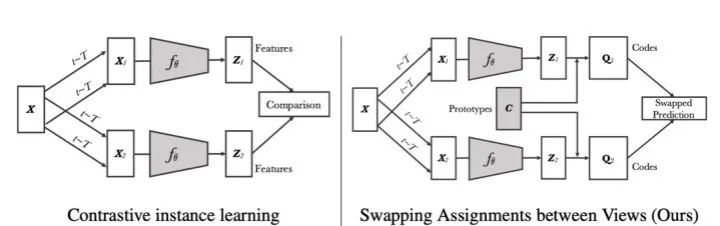
图6 一般对比学习框架与SwAV方法对比示意图
该方法与一般对比学习方法区别在于其对于负样本的处理方式:在SwAV中,作者采用了与SeLa方法相似的基于最优传输的聚类方法,对于同一个正样本在不同分支输入的扰动图片,SwAV希望一个分支得到的样本的特征表示与另一个分支中该样本所属的聚类中心尽量接近。即一般对比学习方法希望经过不同扰动的正样本之间相似度尽可能高,而在SwAV方法中希望经过一种扰动的正样本与经过另一种扰动的正样本所属的聚类中心之间的相似度尽可能高。正是因为用了聚类中心来代替直接使用负样本,SwAV方法对比学习计算中仅需对比固定个数的聚类中心,而与输入batch size大小无关,因而减少了对硬件显存大小的需求。
03
总结
本文简要介绍了当今主流的基于对比学习与聚类方法的自监督学习方法:对比学习主要考虑实例级别的差异,即每个实例应该与经过某种变换之后的自己最相似;基于聚类的方法更加侧重数据自动标注方面,通过将数据划分为若干子集来使得模型学到具有区分能力的特征表示。
参考文献
[1] Liu X, Zhang F, Hou Z, et al. Self-supervised learning: Generative or contrastive[J]. IEEE Transactions on Knowledge and Data Engineering, 2021.
[2] He K, Fan H, Wu Y, et al. Momentum contrast for unsupervised visual representation learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 9729-9738.
[3] Chen T, Kornblith S, Norouzi M, et al. A simple framework for contrastive learning of visual representations[C]//International conference on machine learning. PMLR, 2020: 1597-1607.
[4] Grill J B, Strub F, Altché F, et al. Bootstrap Your Own Latent: A new approach to self-supervised learning[C]//Neural Information Processing Systems. 2020.
[5] Asano Y M, Rupprecht C, Vedaldi A. Self-labelling via simultaneous clustering and representation learning[C]//International Conference on Learning Representations. 2019.
[6] Caron M, Bojanowski P, Joulin A, et al. Deep clustering for unsupervised learning of visual features[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 132-149.
[7] Cuturi M. Sinkhorn distances: Lightspeed computation of optimal transport[J]. Advances in neural information processing systems, 2013, 26: 2292-2300.
[8] Caron M, Misra I, Mairal J, et al. Unsupervised Learning of Visual Features by Contrasting Cluster Assignments[C]//Thirty-fourth Conference on Neural Information Processing Systems (NeurIPS). 2020.
THE END
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MAPG” 就可以获取《【TPAMI2021】深度神经网络自监督视觉特征学习综述,22页pdf》专知下载链接






