谷歌提出:无监督数据增广新方法UDA,全面超越现有半监督学习方法

本文转载自:新智元
本文转载自:新智元
来源:GoogleAI
编辑:元子
【导读】Google AI最新研究用无监督数据增强推进半监督学习,取得令人瞩目的成果。该方法超越了所有现有的半监督学习方法,并实现了仅使用极少量标记样本即可达到使用大量标记样本训练集的精度。
深度学习之所以能够成功的关键因素,是算法的进步,以及并行处理硬件(GPU / TPU)以及大型标记数据集(如ImageNet)。
然而,当标记数据稀缺时,深度学习就像缺了一条腿。在这种情况下,需要应用数据增强方法,例如对句子进行释义或将图像进行旋转,以有效地增加标记的训练数据的量。
如今,在诸如自然语言处理(NLP),视觉和语音等各种领域的数据增强方法的设计上,已经取得了重大进展。不幸的是,数据增加通常仅限于监督学习,需要标签从原始示例转移到增强示例。
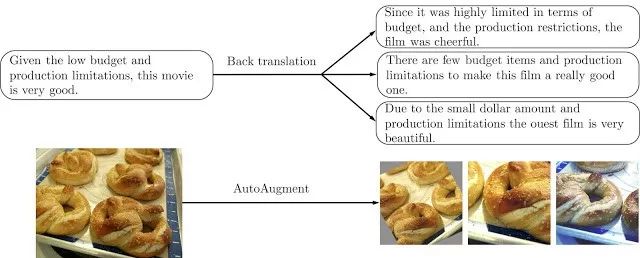
上图:基于文本(顶部)或基于图像(底部)训练数据的示例增强操作。
在谷歌最近“用于一致性训练的无监督数据增强(UDA)”的研究中,证明还可以对未标记数据执行数据增强,以显著改善半监督学习(SSL)。
谷歌的结果促进了半监督学习的复兴,而且还发现3点有趣的现象:(1)SSL可以匹配甚至优于使用数量级更多标记数据的纯监督学习。(2)SSL在文本和视觉两个领域都能很好地工作。(3)SSL能够与迁移学习很好地结合。
此外谷歌还开放了代码在GitHub。
GitHub地址:
https://github.com/google-research/uda
无监督数据增强同时使用标记数据和未标记数据。在标记数据方面,它使用监督学习的标准方法来计算损失函数以训练模型,如下图的左侧部分所示。
而对于未标记的数据,则应用一致性训练来强制预测未标记的示例和增强的未标记示例是否相似,如下图的右侧部分所示。
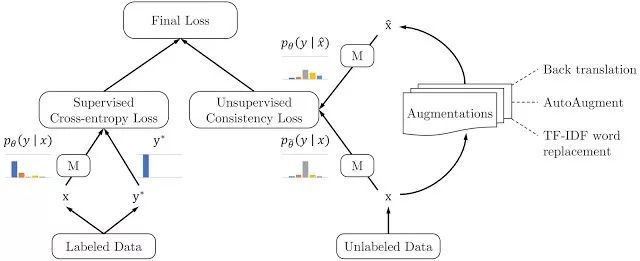
这里,相同的模型被同时应用于未标记的示例和增强的对应物,以产生两个模型预测,从中计算一致性损失(即,两个预测分布之间的距离)。
然后,UDA通过联合优化标记数据的监督损失和未标记数据的无监督一致性损失,来计算最终损失。
通过最小化一致性损失,UDA允许标签信息从标记的示例平滑地传播到未标记的示例。
直觉上,人们可以将UDA视为隐含的迭代过程:该模型依赖于少量标记的示例,来对一些未标记的示例进行正确的预测,从中通过一致性损失,并将标签信息传播到增强的对应物。随着时间的推移,越来越多未标记的示例终将被正确预测,这反映了模型的改进的泛化。
谷歌对各种其他类型的噪声进行一致性训练测试(例如高斯噪声、对抗性噪声等)后,在各种各样的噪声上实现了最先进的性能。
UDA根据任务应用不同的现有增强方法,包括反向翻译、自动增强和TF-IDF单词替换。
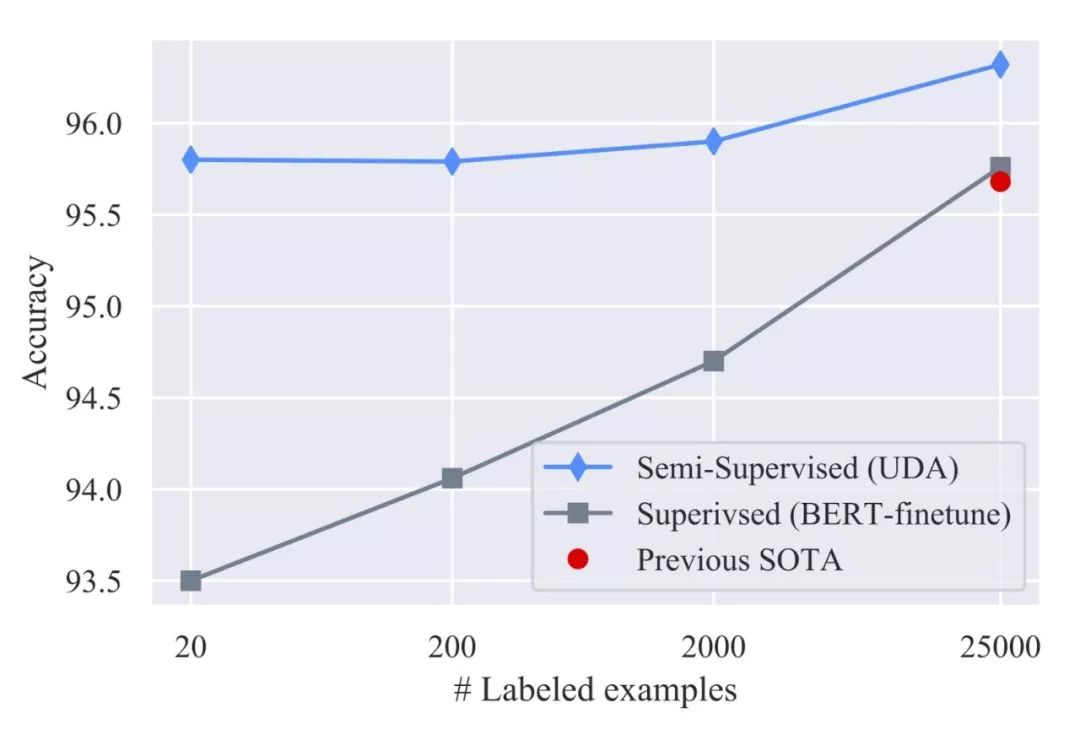
UDA在低数据体系中出乎意料地有效。只用20个标记示例,UDA通过50000个未标记的示例,在IMDb情绪分析任务中实现了4.20的错误率。
该结果优于先前使用25000个标记示例训练的最先进模型(错误率为4.32)。在大数据制度中,通过完整的训练集,UDA也提供了强大的收益。
IMDb的基准,是一种情绪分析任务。UDA在不同培训规模的监督学习中超越了最先进的成果,如下图。
在CIFAR-10半监督学习基准测试中,UDA的表现同样优于所有现有的SSL方法,如VAT、ICT和MixMatch。
在4k示例情况下,UDA实现了5.27的错误率,与使用50k示例的完全监督模型的性能相匹配。
此外,通过更先进的PyramidNet+ShakeDro架构p,UDA实现了2.7的新的最新错误率,与之前的最佳半监督结果相比,错误率降低了45%以上。
在SVHN上,UDA仅使用250个标记示例,就实现了2.85的错误率,与使用70k标记示例训练的完全监督模型的性能相匹配。
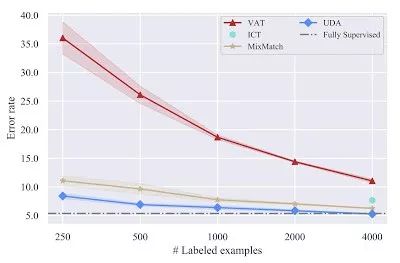
CIFAR-10的SSL基准测试,图像分类任务。UDA超越了所有现有的半监督学习方法,所有这些方法都使用Wide-ResNet-28-2架构。在4000个示例中,UDA将完全监督设置的性能与50000个示例相匹配。
在具有10%标记示例的ImageNet上,UDA将TOP 1精度从55.1%提高到68.7%。
在具有完全标记集和1.3M额外未标记示例的高数据体系中,UDA继续为前1精度提供78.3%至79.0%的增益。
参考链接:
https://ai.googleblog.com/2019/07/advancing-semi-supervised-learning-with.html
CVer学术交流群
扫码添加CVer助手,可申请加入CVer-目标检测交流群、图像分割、目标跟踪、人脸检测&识别、OCR、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶和剪枝&压缩等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!



