基于深度学习的医学图像半监督分割
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文作者:luoxd
https://zhuanlan.zhihu.com/p/257109614
本文已由原作者授权,不得擅自二次转载
准确、鲁棒地从医学图像中分割出器官或病变在许多临床应用中起着至关重要的作用,如诊断和治疗计划。随着标注数据的大量增加,深度学习在图像分割方面获得了巨大地成功。然而,对于医学图像来说,标注数据的获取通常是昂贵的,因为生成准确的注释需要专业知识和时间,特别是在三维图像中。为了降低标记成本,近年来人们提出了许多方法来开发一种高性能的医学图像分割模型,以减少标记数据。例如,将用户交互与深度神经网络相结合,交互式地进行图像分割,可以减少标记的工作量。自监督学习方法是利用无标签数据,以监督的方式训练模型,学习基础知识然后进行知识迁移。半监督学习框架直接从有限地带标签数据和大量的未带标签数据中学习,得到高质量的分割结果。弱监督学习方法从边框、涂鸦或图像级标签中学习图像分割,而不是使用像素级标注,这减少了标注的负担。但是,弱监督学习和自监督学习在医学图像分割任务上性能依旧受限,尤其是在三维医学图像的分割上。除此之外,少量标注数据和大量未标注数据更加符合实际临床场景。本文总结了近些年出现的用于医学影像的半监督学习方法,这些方法大致可以分为:(1),基于数据扰动或模型扰动或数据模型同时扰动正则化;(2),基于多任务层面的一致性约束。
1. TCSM-V1: Semi-supervised Skin Lesion Segmentation via Transformation Consistent Self-ensembling Model. (BMVC2018)
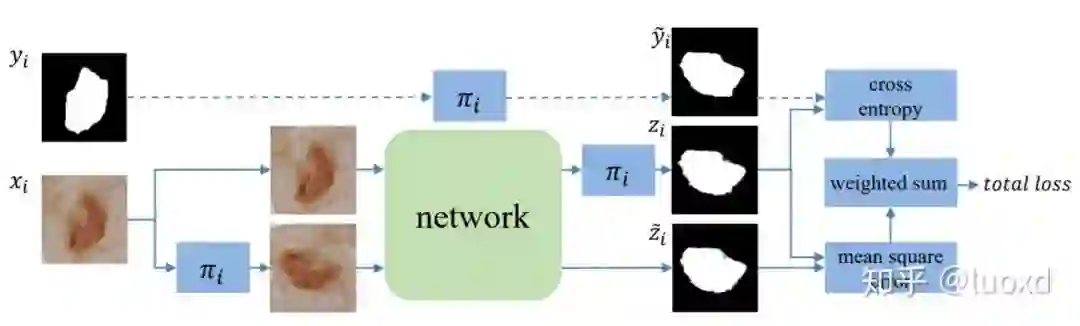
总结:这篇文章的方法类似于Temporal ensembling for semi-supervised learning(ICLR2017)通过给输入数据加扰动(transformation)来正则化模型 (一次迭代模型需要前向传播两次,输入分别是未变化的图像和变化后的图像,然后变化后图像得到的结果进行反变换然后构建这两个预测结果的一致性损失),直接将未标注数据利用起来,想法很简洁但效果很不错。
2. TCSM-V2: Transformation-Consistent Self-Ensembling Model for Semisupervised Medical Image Segmentation. (TNNLS2020)
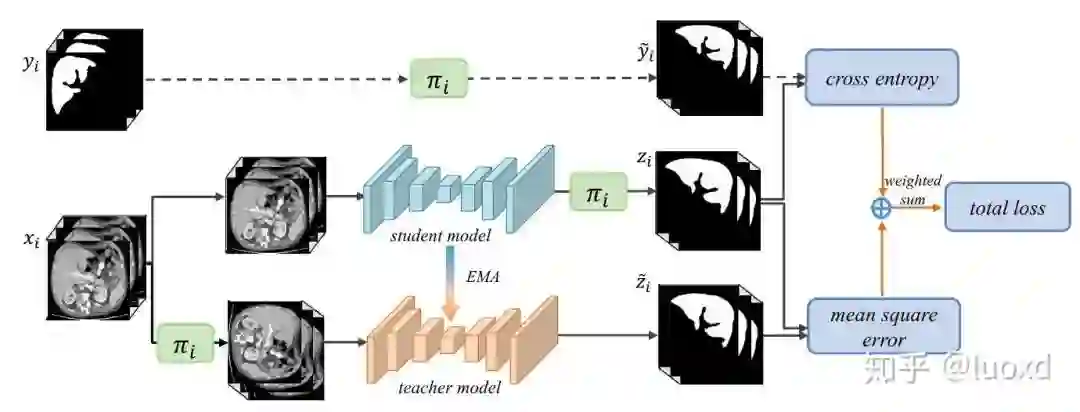
总结:这篇在Mean Teacher (NIPS2017) 的基础上引入了更多的数据扰动(flip, rotate, rescale,noise等等)和模型扰动(dropout)来构建同一输入在不同扰动下的一致性。然后取得了很不错的效果。
以上两篇的文章代码也已开源:
https://github.com/xmengli999/TCSM
3. Uncertainty-aware Self-ensembling Model for Semi-supervised 3D Left Atrium Segmentation (MICCAI2019)
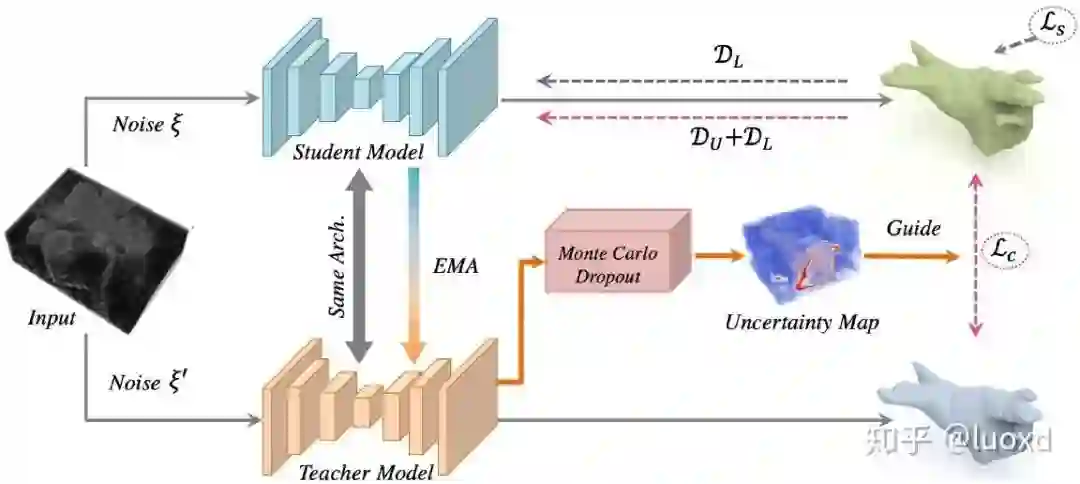
总结:这篇文章整合了Mean Teacher (NIPS2017) 和不确定性估计来进行半监督学习,通过不确定性图来指导(加权)Mean Teacher模型从未标注的数据上逐步学习。不确定性图的计算采用了经典的蒙特卡洛 Dropout多次推理来获得,这样会带来一些额外的计算开销,但带来了性能的提升,可以得到不错的效果,而且现在利用不确定性估计来提高网络性能也是一个热门的研究方向。
这篇文章代码已开源:
https://github.com/yulequan/UA-MT
值得一提的是,Dr. Lequan的代码写得非常简洁易学,后续也有很多在此基础上改进的算法。
4. 3D Semi-Supervised Learning with Uncertainty-Aware Multi-View Co-Training (WACV2020,MedIA2020)
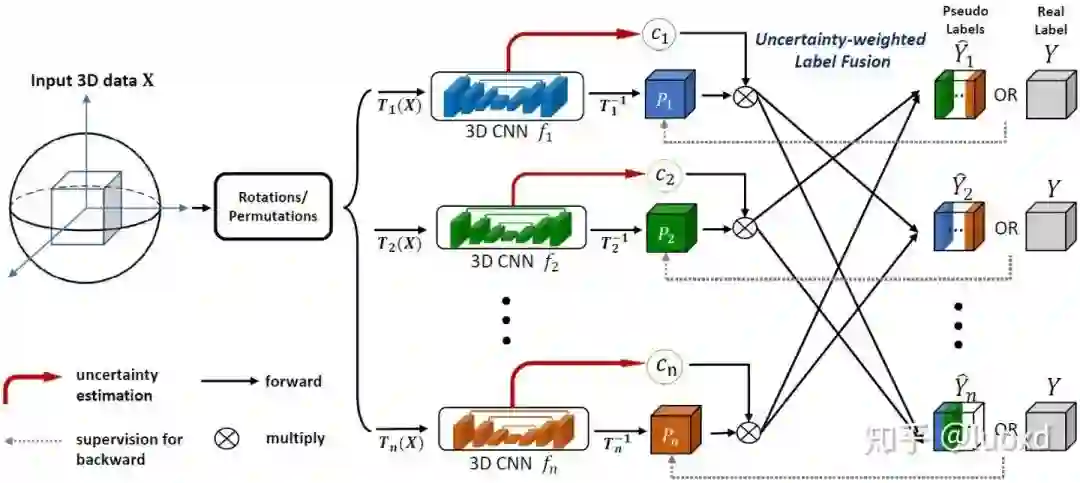
总结:这篇文章结合了前面提到的几篇的所有特点(没有采用Mean Teacher Model),并将多视角的联合训练引入到医学图像的半监督和域适应的问题中,想法很新颖,实现也不难,而且效果很不错,只是随着视角的不断增加计算开销会越来越大。
5. Shape-aware Semi-supervised 3D Semantic Segmentation for Medical Images (MICCAI2020)
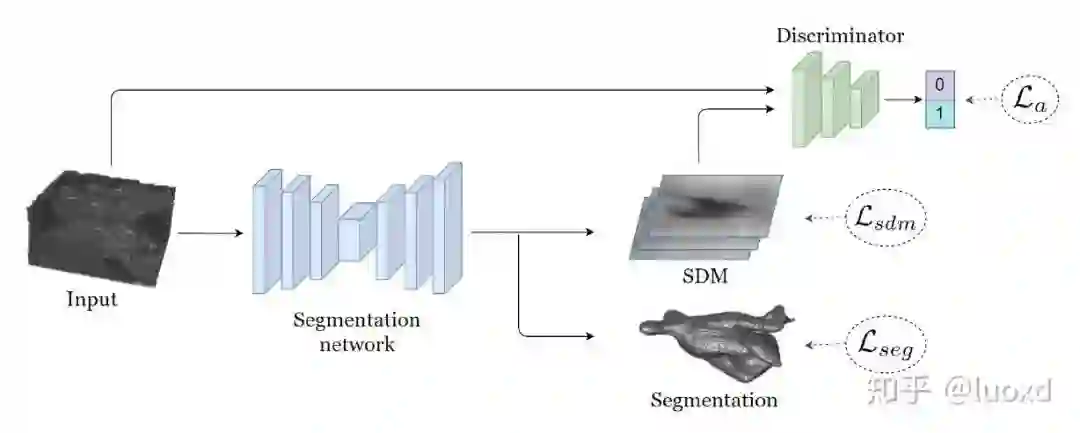
总结: 这篇文章采用了一个常用的多任务网络结构,同时进行图像分割和带符号的距离图回归(引入了形状和位置先验),并用判别器来作为正则化项,与以前常见用判别器做正则化项方法不同的是,本文的判别器输入时带符号的距离图和原图,而不是分割结果和原图。这样设计可以使整个未标记数据集的预测分布平滑,并引入了很强的形状和位置先验信息,保证分割结果的稳定性和鲁棒性。
这篇论文的代码也已经开源:
https://github.com/kleinzcy/SASSnet
6. Semi-supervised Medical Image Segmentation through Dual-task Consistency (Arxiv)
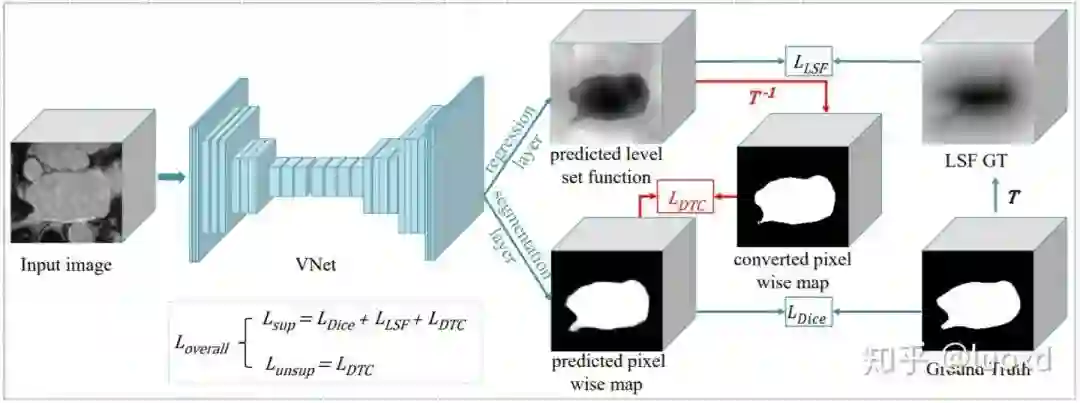
总结: 前面五篇文章主要还是基于数据层面和模型层面的扰动来构建一致性来进行半监督学习。本文(DTC)从任务层面来构建了一致性进行半监督学习,与SASSNet一样本文采用了一个多任务网络结构,同时进行分割和水平集函数回归,不同的是SASSNet用判别器来进行正则化(data-level),而本文利用两个任务之间的表示差异来构建一致性(task-level)。与Mean Teacher等模型需要多次前向传播相比,DTC模型简单,计算开销也不大,除此之外,还有可以构建许多跨任务的一致性进行全监督,半监督或者是跨域(DA)学习。
这篇论文代码也已经开源:
https://github.com/Luoxd1996/DTC
以上论文更多细节和实验结果可以参考这些论文原文,此处只是个人的近期总结,更多内容也欢迎大家补充,也希望大家能设计出更好的半监督学习算法来降低对标注数据的依赖。
医疗影像和图像分割 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-医疗影像和图像分割 微信交流群,目前已汇集1500人!涵盖语义分割、实例分割、全景分割、医学图像分割等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如医疗影像或者图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
整理不易,请给CVer点赞和在看!




