没有
绿幕怎么抠图?
此前,华盛顿大学的研究人员提出用背景图替换 trimap,不用绿幕也能实现不错的抠图结果。
但该方法需要处理和对齐原始图像和背景图两张图像,不便于现实应用。
近日,香港城市大学和商汤提出一种新型人像抠图方法 MODNet,不用绿幕、只用单张图像、单个模型即可实时完成人像抠图。
人像抠图即预测一个精确的前景蒙版(alpha matte),然后利用它从给定图像或视频中提取人物。这一技术得到了广泛的应用,如照片编辑、电影再创作等。目前,实时获得高质量前景蒙版仍需要绿幕的辅助。
但如果没有绿幕呢?目前大部分抠图方法使用预定义 trimap 作为先验。但,trimap 需要人类标注,所需成本高昂,并且如果是通过深度相机捕获,还会出现低精度问题。因此,近期的一些工作尝试消除模型对 trimap 的依赖,即 trimap-free 方法。例如,华盛顿大学提出的 background matting 方法用分离背景图像来替代 trimap。其他方法使用多个模型先生成伪 trimap 或语义掩码,然后将其作为先验进行前景蒙版预测。但使用背景图像作为输入需要输入并对齐两张图像,使用多个模型会使推断时间显著增加。这些缺陷使得前述所有抠图方法不适用于现实应用,如相机预览。此外,受到标注训练数据不足的限制,trimap-free 方法在实践中常遇到域偏移问题,即模型无法很好地泛化至现实数据。
能不能只用一个模型、一张 RGB 图像,来预测精确的前景蒙版呢?最近,香港城市大学和商汤合作提出了一种轻量级网络 MODNet,它将人像抠图任务分解成三个相关的子任务,并通过特定约束执行同步优化。
![]()
![]()
一,神经网络更擅长学习一组简单目标,而不是一个复杂目标。因此,解决多个抠图子目标可以实现更好的性能。
二,对每个子目标应用显式监督信号,可以使模型的不同部分学习解耦的知识,从而实现一个模型解决所有子目标。
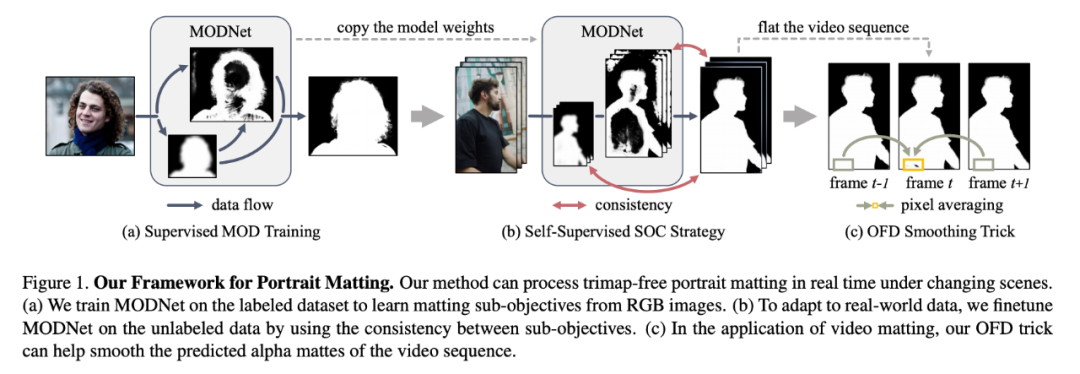
为了克服域迁移问题,该研究基于子目标一致性 (SOC) 提出了一种自监督策略,即利用子目标之间的一致性来减少预测前景蒙版中的伪影。此外,该研究还提出单帧延迟 (OFD) trick 这种后处理方法,以在视频抠图应用中获得更流畅的输出
。MODNet 框架参见下图:
![]()
相比 trimap-free 方法,MODNet 具备以下优势:
MODNet 更快:它专为实时应用而设计,输入大小为 512 × 512 时,MODNet 在 Nvidia GTX 1080Ti GPU 上的运行速度为 63 fps;
MODNet 获得了新的 SOTA 结果,原因在于:1)目标分解和同步优化;2)对每个子目标应用特定的监督信号;
MODNet 具备更好的泛化能力,这得益于 SOC 策略。
尽管 MODNet 的结果没有超过那些基于 trimap 的方法,但实验表明 MODNet 在实际应用中更加稳定,原因就在于其移除了 trimap 输入。该方法对实时人像抠图任务中绿幕的必要性提出了挑战。
现有开源人像抠图数据集的规模或精度均有一定限制,之前很多研究是在质量和难度等级不同的私人数据集上进行模型训练和验证的。这就使得不同方法的对比变得困难。而这项研究在统一的标准下评估现有的 trimap-free 方法:所有模型均在相同数据集上训练完成,并在来自 Adobe Matting 数据集和该研究提出的新基准数据集的人像数据中执行验证。研究人员表示,他们提出的新基准完成了高质量标注,多样性也优于之前的基准,因而能够更全面地反映出抠图性能。
总之,这项研究提出了新型网络架构 MODNet,可实时完成 trimap-free 人像抠图。研究者还提出了两项技术 SOC 和 OFD,使 MODNet 能够很好地泛化至新的数据领域,视频抠图质量更加平滑。此外,该研究还构建了新的人像抠图验证基准数据集。
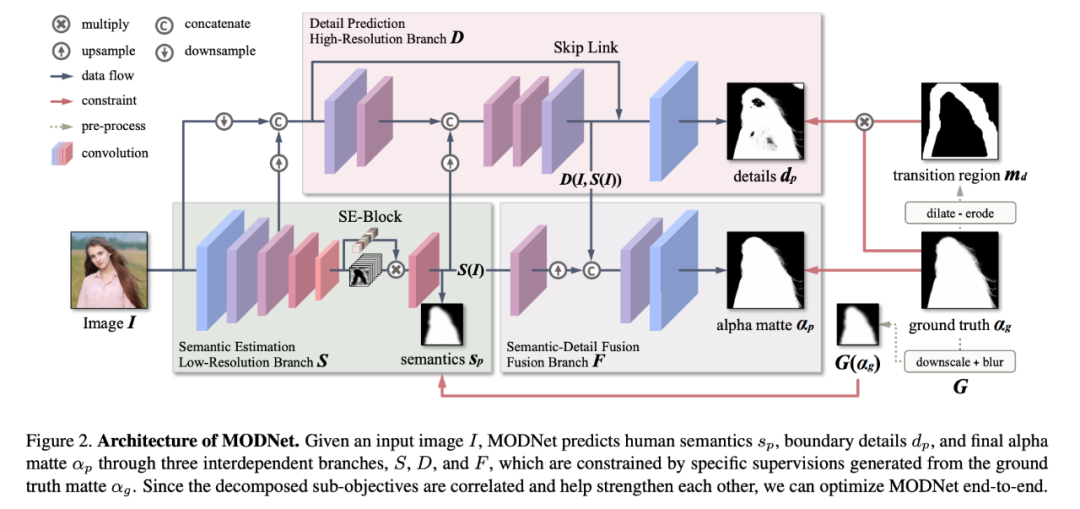
基于多个模型的方法表明,「将 trimap-free 抠图看作 trimap 预测(分割)步骤加上基于 trimap 的抠图步骤」能够实现更好性能。这表明,神经网络从分解复杂目标中受益。于是,该研究将这一思路继续扩展,将 trimap-free 抠图目标分解为语义估计、细节预测和语义 - 细节融合三个子目标。直观来看,语义估计输出粗糙的前景掩码,细节预测生成细粒度的前景边界,而语义 - 细节融合则将这二者的特征进行混合。
如图 2 所示,MODNet 包含三个分支,每一个均通过特定约束学习不同的子目标。具体而言:
低分辨率分支用于估计人类语义(监督信号是真值蒙版的缩略图);
高分辨率分支用于辨别人像边界(监督信号是过渡区域 (α ∈ (0, 1));
融合分支用来预测最终的前景蒙版(监督信号是整个真值蒙版)。
![]()
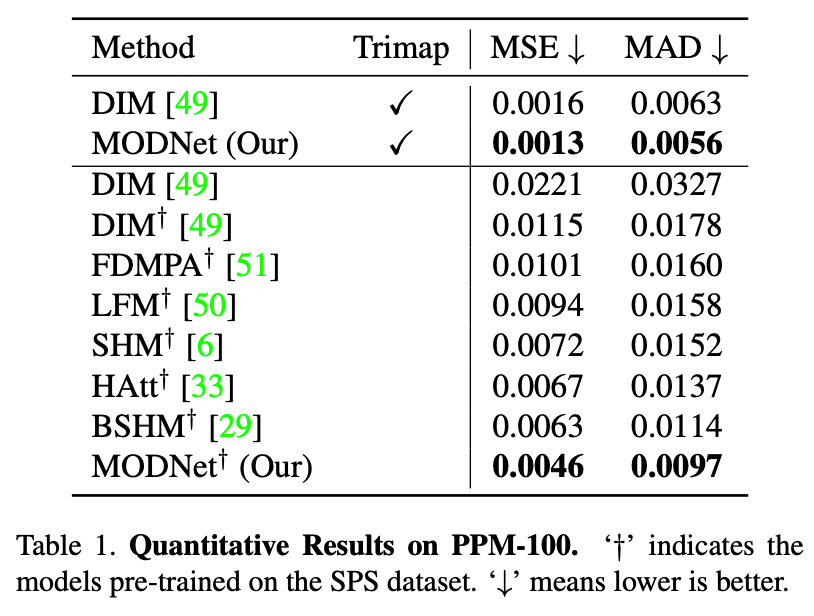
该研究创建了新型人像抠图基准 PPM-100,并在其上对比了 MODNet 和现有的人像抠图方法,还证明了 SOC 和 OFD 策略对于 MODNet 适应现实数据的有效性。
该研究提出了新型人像抠图基准 Photographic Portrait Matting benchmark (PPM-100),包含 100 张精心标注、背景不同的人像。如下图 4 所示, PPM-100 中的样本背景更加自然、人物姿势更丰富,因此数据也更全面。
![]()
研究者在 PPM-100 上对比了 MODNet 和 FDMPA、LFM、SHM、BSHM、HAtt,结果参见下表 1。从中可以看出,MODNet 在 MSE 和 MAD 这两项指标上超过其他 trimap-free 方法,但仍逊色于基于 trimap 的 DIM 方法。将 MODNet 修改为基于 trimap 的方法后,其性能超过 DIM。
![]()
![]()
从中可以看出,MODNet 可以更好地处理空心结构(第一行)和头发细节(第二行),但在处理难度较大的姿势或服饰时仍然会出现问题(第三行)。
下图展示了 MODNet 在现实数据上的抠图效果,从图中可以看出 SOC 对于模型在现实数据上的泛化能力非常重要,OFD 可以进一步使输出结果更加平滑。
![]()
MODNet 不基于 trimap,因而能够避免错误 trimap 的问题。图 8 展示了 MODNet 与基于 trimap 的 DIM 方法的对比结果:
![]()
此外,研究者还对比了 MODNet 和华盛顿大学提出的 background matting (BM) 方法,参见图 9。从图中可以看出,当移动对象突然出现在背景中时,BM 方法的结果会受到影响,而 MODNet 对此类扰动具备鲁棒性。
一场属于蓉城的“鲜香”盛宴,DevRun开发者沙龙邀您开启“麻辣”开发之旅
12月12日,DevRun开发者沙龙华为云成都专场将带你逐一解锁:AI开发与云原生DevOps的进阶之旅、华为云技术专家面对面的教学指导、技术瓶颈突破与核心效能提升的关键要义以及拥抱变革与自我进阶的最佳姿势。精彩不容错过!
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com