学界 | 牛津大学ICCV 2017 Workshop论文:利用GAN的单视角图片3D建模技术
选自arXiv
机器之心编译
参与:李泽南
对于现实世界物体的 3D 建模是很多工作中都会出现的任务。目前流行的方法通常需要对于目标物体进行多角度测量,这种方法耗费资源且准确度低下。近日,来自牛津大学等院校的研究者们提出了一种基于自编码器与 GAN 的机器学习 3D 建模方式 3D-RecGAN,可以在只需要一张图片的情况下准确构建物体的 3D 结构。该研究的论文即将出现在 10 月底于威尼斯举行的 ICCV 2017 大会上。
重建物体完整与准确的 3D 模型是很多工作中必不可少的任务,从 AR/VR 应用到语义理解,再到机器人抓取和障碍物回避。常见的方法是使用 Kinect 和 RealSense 这样的低成本探测设备从抓取到的景深图片中进行 3D 建模,此类方法通常需要抓取大量不同视角的景深图片。然而,在实际环境中,扫描物体整个表面并不总是可行的,这意味着构建的模型可能会忽略物体的某些空隙。另外,获取和处理多个深度视图需要耗费大量计算资源,这对很多需要即时反应的应用不利。
来自英国牛津大学、华威大学、赫瑞瓦特大学以及帝国理工大学的研究者们提出的方法破解了这个问题。他们试图用单一景深影像来重构完整的 3D 模型。这是一项非常具有挑战性的工作,对目标物体的不完整观察理论上可以延伸出无限多种 3D 模型的可能性。传统重构方法通常使用插值技术,如平面消差、泊松面估计来估算背面的 3D 结构。然而,这些方法只能重建简单的缺失/隐藏区域,应对孔隙、噪声和信息不充分等因素造成造成的图像不完整。
有趣的是,人类具有惊人的隐藏内容补完能力。例如,给出一张椅子的图片,后两个椅子腿被遮挡,人类可以轻而易举地猜出背后最为可能的形状。受此启发,研究人员认为,近期快速发展的深度神经网络与数据驱动方法正适合处理这类任务。
同时,虽然目前业内最佳的深度学习 3D 形状重建技术取得了令人满意的进展,但它们仍然只适用于小于 403 立体像素网络的分辨率,这导致学习到的 3D 形状粗糙而不准确。而在不牺牲准确度的情况下增加模型分辨率非常困难,因为即使稍稍提高分辨率都会显著提高潜在 2.5D 到 3D 绘图函数的搜索空间,导致神经网络收敛困难。
在该研究中,研究者们提出了 3D-RecGAN,一种结合自动编码器与 GAN 的全新模型,用于在单个 2.5D 视图的基础上生成完整 3D 结构。其中,研究人员首次将 2.5D 视角编码为低维隐空间向量,隐藏式地表示 3D 几何结构,随后将其解码以重建最为可能的完整 3D 结构。粗建的 3D 结构随后被输入条件鉴别器中,这一单元被对抗训练以用于分辨粗制 3D 形态是否合理。自动编码器能够近似相应的形状,而对抗训练倾向于将细节加入到估算的形状中。为了确保最终生成的 3D 形体与输入的 2.5D 视图相对应,该模型的对抗训练是基于条件 GAN,而不是随机猜测的。
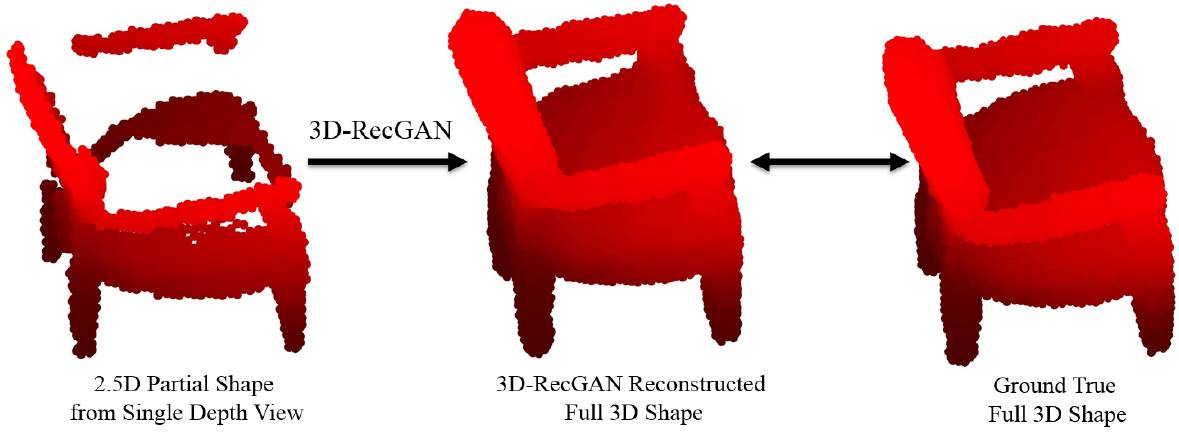
图 1. 3D-RecGAN 从单张 2.5D 景深图中重建完整 3D 模型的结果示例
该方法旨在预测一个 3D 形体的完整形状,它只需要任意一个 2.5D 深度视图作为输入。其输出的 3D 形态可以自动与对应的 2.5D 部分图像相适应。为了达到要求,每个目标模型以 3D 立体像素网络表示,只是用简单的占位信息进行地图编码,其中 1 表示占用的单元格,0 表示空单元格。具体地,表示为 I 的输入和表示为 Y 的输出 3D 形状在网络中使用了 643 个占用网格。输入形状直接由单一深度图像算出。
输入形状直接来自单一深度图片的计算。为了产生真正的训练和评估对,研究人员虚拟扫描了 ModelNet40 中的 3D 物体。图 2 是部分 2.5D 视图的 t-SNE 可视化和多个通用椅子和床相应的全 3D 形状。每个绿点表示 2.5D 视图的 t-SNE 嵌入,红点则是嵌入的相应 3D 形状。可以看出,很多类别固有地具有类似的 2.5D 到 3D 映射关系。看起来,神经网络学习出了一个平滑的函数,表示为 f,它将绿色点映射到高维空间中的红点,函数 f 通常由卷积层参数化。
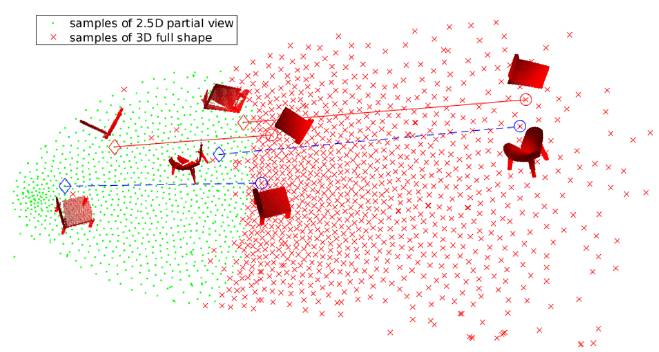
图 2. t-SNE 嵌入 2.5D 部分视图和 3D 完整形状的多个对象类别。
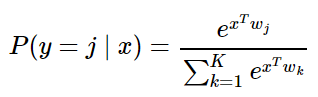
图 3. 用于训练的网络架构概览
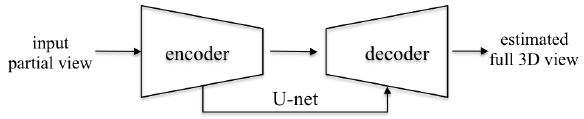
图 4. 用于测试的网络架构概览
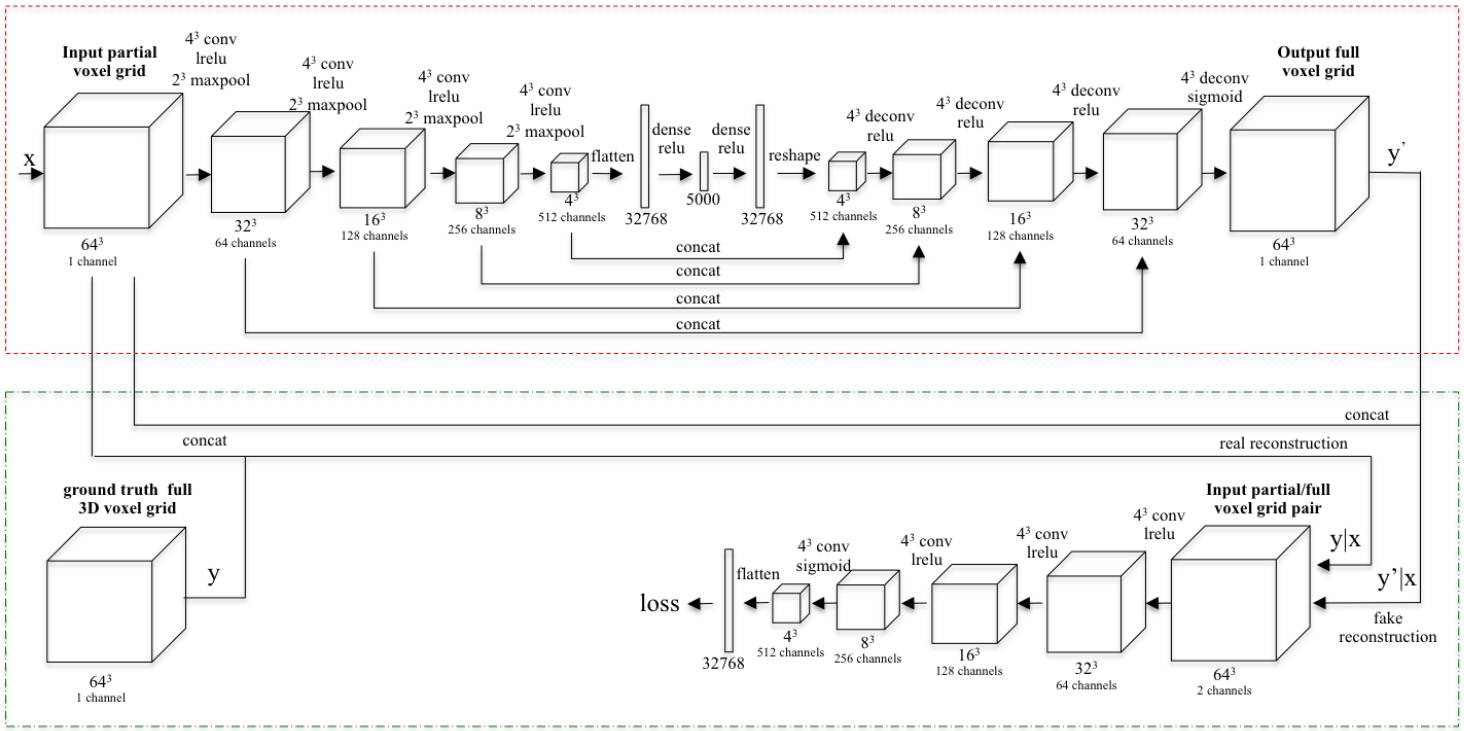
图 5. 3D-RecGAN 架构
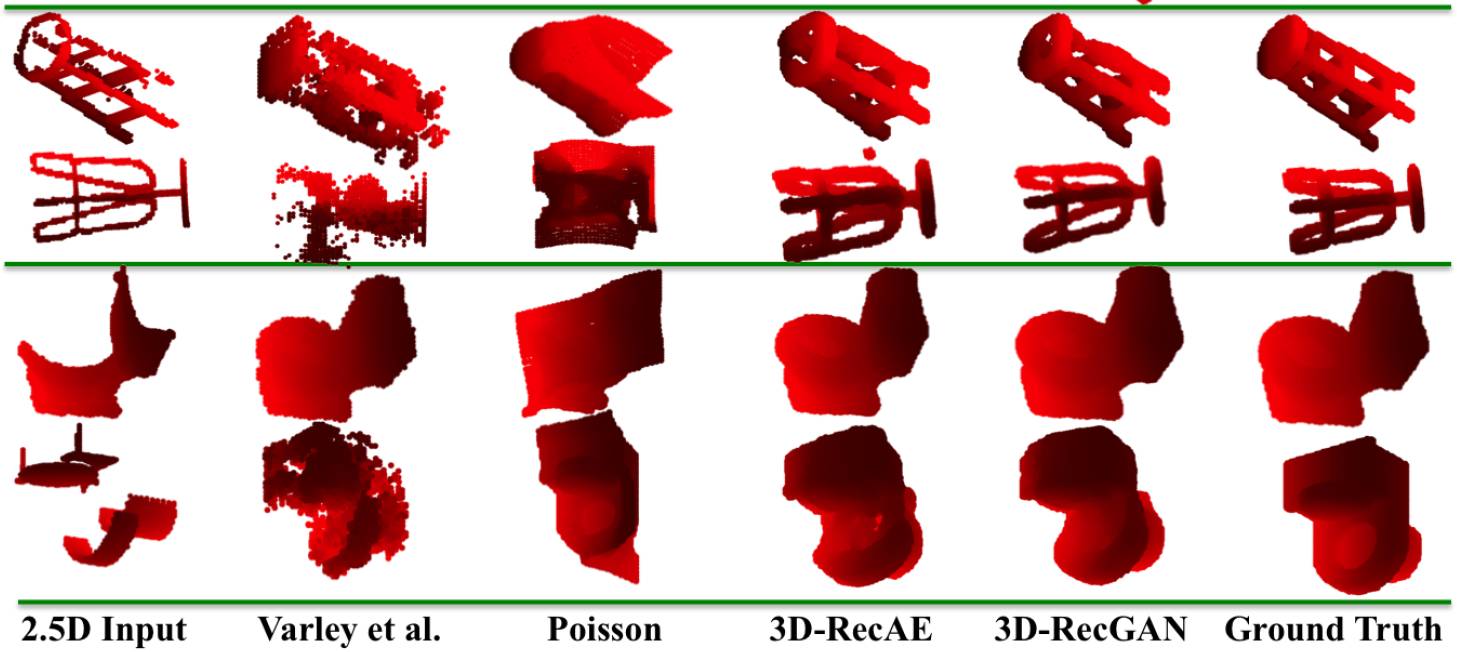
图 6. 不同方法的 3D 建模效果对比
论文:3D Object Reconstruction from a Single Depth View with Adversarial Learning

论文链接:https://arxiv.org/abs/1708.07969
项目代码:https://github.com/Yang7879/3D-RecGAN
摘要:在本论文中,我们提出了一种名为 3D-RecGAN 的新方法,它使用生成对抗网络从单个任意深度视图重建给定对象的完整 3D 结构。与通常需要同一张图片从多个角度或多类标签来还原完整 3D 结构的方式不同,我们提出的 3D-RecGAN 只需要获得对象深度视图的立体像素表示输入,即可生成目标物体包含 3D 填充/缺失区域的网格模型。其中的关键思想是结合生成能力与自编码器,以及条件生成对抗网络(GAN)架构,来生成高维孔隙形状物体准确而精细的 3D 结构。对于大型合成数据集的广泛实验显示,3D-RecGAN 的表现显著好于目前业内最佳的单视角 3D 目标重建方法,同时可以重建目标物体不可见的部分。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




