CVPR 2019 | 基于密集语义对齐的行人重识别模型:有效解决语义不对齐

编者按:行人重识别(Person Re-identification),也称行人再识别,旨在利用计算机视觉技术实现基于图片或视频的行人匹配和检索。深度学习的发展极大地推动行人重识别性能的提升。然而在实际应用中,行人图片面临诸多问题,如行人图片分辨率低、人体姿态和拍摄视角差异大、障碍物遮挡等。很多因素会导致不同图像在空间上语义不对齐,进而影响行人重识别的性能。为此,微软亚洲研究院和中国科学技术大学在CVPR 2019上共同提出了行人重识别模型DSA-reID,尝试借助密集语义提升行人重识别的性能。
近年来,越来越多的摄像机被部署到公共场所中,例如商场、居民区、工厂、街道等,如何借助人工智能技术实现海量视频数据的智能分析和应用,成为构建智能安防、智慧城市的关键。其中,行人重识别正是核心课题之一。该技术可被用于从大量图像或视频数据中查询目标人员、或者用于对不同时刻或不同摄像头下相同行人的匹配。
伴随着深度学习技术的发展,行人重识别的性能实现了大幅提升。然而,该任务仍然存在挑战和提升空间——由于真实的视频图像大多从实际的公共场所获取,存在多样性和复杂性,行人图像常面临分辨率低、人体姿态和拍摄视角各异、障碍物遮挡、背景差异大、光照变化大等实际问题(如图1所示)。
上述的众多实际问题均会导致图像间语义在空间上的不对齐,即对两个要匹配的图片,相同的空间位置对应的内容的语义(Semantics)不同,从而制约了行人重识别技术的鲁棒性和有效性。例如图1(c)中,图像顶部在第一个图片中对应的是肩膀,而第二个图片相应空间位置对应的是头,使得空间上语义不对齐(misalignment)。

图1:行人重识别中的问题与难点
为了解决行人重识别面临的语义不对齐问题,许多工作借助于人体骨架(Pose)来定位不同的身体部位,例如头、胳膊等,以辅助学习基于身体部位对齐的特征。然而,由于身体部位的划分相对粗糙,尚不能实现细粒度上的语义对齐。如图1(d)所示,对于下胳膊(low arm)这一相同的身体部位,在两个图像区域间仍存在严重的语义不对齐现象。
为了实现更好的对齐以提升行人重识别性能,微软亚洲研究院和中国科学技术大学共同提出了基于密集语义对齐的行人重识别模型DSA-reID (Densely Semantically Aligned Person Re-identfication),有效地解决了行人重识别中广泛存在的空间语义不对齐问题,显著地提高了行人重识别技术的算法精度。
语义空间映射
针对行人图像,我们先利用密集语义估计技术(DesnePose)进行像素级别的细粒度语义估计,从而得到各个像素的语义信息。不同于仅有有限节点数的骨架估计,密集语义可以对人体3D表面上的每一个位置赋予一个不同的语义,并通过(u,v)两维坐标值来表达其语义。相应地,根据(u,v)坐标值,人体3D表面上的每个语义(u,v)位置对应的纹理可被映射到UV空间上。该参数化表达方式也常见于图形学中,例如用于对人体纹理信息的存储。
如图2(第一行)所示,人体的3D表面被切分成了24区域/部位。在每个区域内,基于密集语义(u,v),可以获得人体3D表面在UV空间上的表示,即纹理图。给定任何一张行人RGB图像,如图2第二行所示,借助于DensePose估计出的密集语义(U-map和V-map),可以将原始图像映射到UV空间,获得密集语义对齐的24个身体部件图像(DSAP-images)。对于任何两张行人图像,其在UV空间上的同一位置对应的语义总是相同的,即所有图像在UV空间上的表达是密集语义对齐的。此外,该空间表达拥有不包含图像背景的优势。然而,由于单视角图像不能完整对应3D人体的整个表面,另外语义估计难免存在误差,我们通过语义映射得到的映射图像(DSAP-images)不能被完全填充且含有由于语义估计误差带来的噪声,这使得单独借助24个映射图像难以实现鲁棒的行人重识别。因此,我们设计了联合学习框架实现语义对齐的行人特征学习。
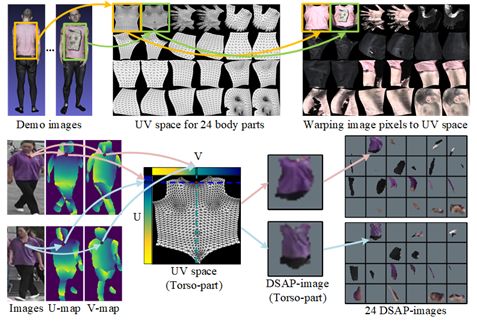
图2:密集语义空间映射
联合学习框架
我们通过两路联合学习框架,学习密集语义对齐的全局和局部行人特征表达。
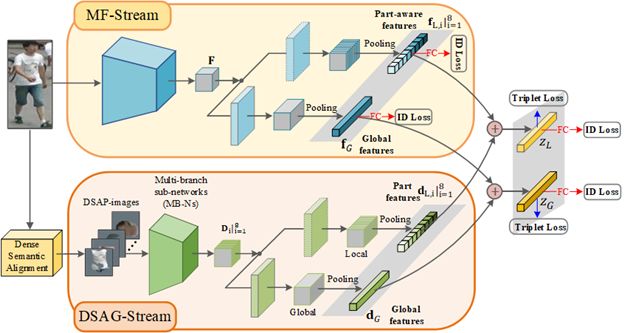
图3:密集语义对齐的行人重识别联合学习框架
如图3所示,该联合学习框架包含MF-Stream(Main Full image stream)和DSAG-Stream(Densely Semantically Aligned Guiding stream)两路。MF-Stream从原始行人图像中提取具有判别力的特征表达,DSAG-Stream用于处理映射得到的密集语义对齐的局部语义部件图像(DSAG-images),并进行分层语义融合。我们通过对(1)两路特征element-wise add融合和(2)在融合后的特征上加入监督(分类loss和Triplet loss)的设计,实现两路的交互学习。DSAG-Stream起到引导主路MF-Stream学习语义对齐的特征的作用。在测试阶段,DSAG-Stream可以被去掉,仅使用MF-Stream,从而具有低的复杂度和高的计算效率。
我们对整个网络进行端到端的训练。具体来说,MF-Stream采用基于ResNet-50改进的网络结构作为backbone网络进行特征提取,并在末端使用两分支网络分别提取行人的全局特征表达和局部特征表达;DSAG-Stream采用组卷积分别处理特定语义部件图像。DSAG-Stream在特征提取的过程中进行了两个阶段特征融合(如图4示意图的方式),从而得到对应8个具有特定语义的局部特征表达,分别对应“躯干”、“手”、“脚”、“腿(上)”、“腿(下)”、“胳膊(上)”、“胳膊(下)”和“头”。
我们知道,用于表征全局信息的全局特征(Global feature),以及可以保留更多局部信息的局部特征(Local features)对于行人重识别都有重要的意义。因此,在两路中,均设计了局部分支和全局分支并在各类分支中进行两路特征的融合以实现交互。DSAG-Stream在特征提取的过程中分两个阶段进行特征融合,以提高特征表达的鲁棒性和减少网络的大小。在第一阶段,我们将对应人体左右对称的语义部件图像的特征表达进行融合;在第二阶段,我们将具有相似语义的部件的特征进行融合。最终得到一个全局特征表达和8个具有特定语义的局部特征表达。

图4:24个身体部件融合为8组的示意图
为了验证DSA-reID模型的有效性,我们对其进行了相关的消融实验和对比实验。
消融实验
框架有效性验证:如表1所以,通过随机擦除(RE)等数据增广技术、标签平滑技术(LS)、两分支设计等,我们得到了高性能Baseline模型“Baseline(Two branches)”。基于高性能Baseline模型,我们分别验证了密集语义对齐技术对于学习全局、局部、全局与局部联合特征对齐表达的有效性。其中,Single表示仅使用了全局或局部分支;Joint表示整个网络联合训练,测试阶段仅使用全局或局部特征。
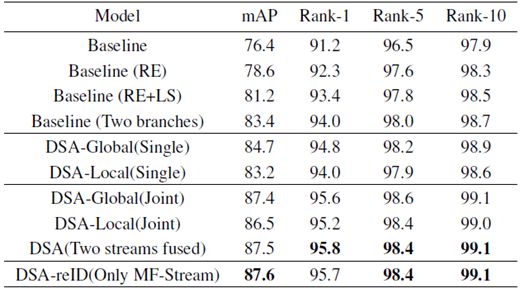
表1:在Market1501数据集上的有效性验证实验
可以看到,DSAG-Stream的引入极大地提升了行人重识别性能,与“Baseline(RE+LS)”相比,全局分支和局部分支分别实现了6.2%和5.3%的mAP提升。另外,在测试阶段,我们可以去除在训练过程中起到引导学习作用的DSAG-Stream,从而保证测试的高效性(低的网络复杂度)。我们发现,和用两路相比,只用主路(MF-Stream)在测试时并无性能损失。最终,对比高性能版本的Baseline模型“Baseline(Two branches)”,在Market-1501数据集上,DSA-reID方法在mAP和Rank-1上仍然获得+4.2%和+1.7%的显著性能提升。
粗粒度对齐vs.细粒度对齐:另外,我们对比了在我们框架下细粒度语义对齐和粗粒度语义对齐对于行人重识别特征学习帮助的差异性。如表2所示,我们发现不同粒度的语义对齐正则对于行人重识别的特征学习均有帮助,而细粒度的语义对齐正则对于特征学习的帮助更为显著,较之粗粒度对齐在mAP上实现了3.5%的提升。
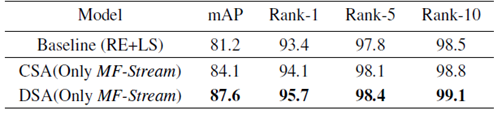
表2:粗粒度语义(CSA)vs. 细粒度(DSA)密集语义对齐对行人重识别性能的影响
两路信息交互:我们对比不同信息交互方式对于联合学习框架性能的影响。表3展示了实验结果,和concatenation相比,我们提出的element-wise add实现了高效的交互。

表3:不同信息交互方式对比:"concatenation+fc" vs. "element-wise add"
性能比较
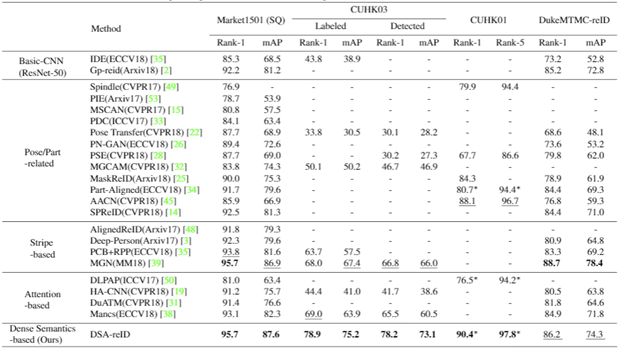
表4:和其它方法的性能比较
和其它state-of-the-art的方法对比,我们提出的基于密集语义对齐的行人重识别技术在多个benchmark数据集上实现了state-of-the-art性能。在CUHK03数据库上,Rank-1精度实现了10.9%和11.4%的提升。
密集语义对齐旨在从根本上解决行人重识别中存在的图像之间空间不对齐问题。为了解决实际应用中存在的人体姿态和拍摄视角各异、障碍物遮挡、背景差异大等重要挑战,本文探索了一种有效的方式来引导主网络学习语义对齐的行人特征,从而极大地提升了行人重识别的性能,更多细节请参考论文。除此之外,我们还提出了一个语义对齐网络Semantics Aligning Network (SAN),尝试从新的角度,即重建密集语义对齐的内容,来实现密集语义对齐。
如何高效地借助密集语义提升行人重识别的性能仍然是一个开放性的问题,希望有更多的工作探索利用该重要信息来促进行人重识别的发展。
相关论文:
Zhizheng Zhang, Cuiling Lan, Wenjun Zeng, Zhibo Chen, "Densely Semantically Aligned Person Re-identification"
http://openaccess.thecvf.com/content_CVPR_2019/papers/Zhang_Densely_Semantically_Aligned_Person_Re-Identification_CVPR_2019_paper.pdf
Xin Jin, Cuiling Lan, Wenjun Zeng, Guoqiang Wei, Zhibo Chen, "Semantics-Aligned Representation Learning for Person Re-identification"
https://arxiv.org/abs/1905.13143
你也许还想看:



感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。



