搞定NLP领域的“变形金刚”!手把手教你用BERT进行多标签文本分类

大数据文摘出品
来源:medium
编译:李雷、睡不着的iris、Aileen
过去的一年,深度神经网络的应用开启了自然语言处理的新时代。预训练模型在研究领域的应用已经令许多NLP项目的最新成果产生了巨大的飞跃,例如文本分类,自然语言推理和问答。
ELMo,ULMFiT 和OpenAI Transformer是其中几个关键的里程碑。所有这些算法都允许我们在大型数据库(例如所有维基百科文章)上预先训练无监督语言模型,然后在下游任务上对这些预先训练的模型进行微调。
这一年里,在这一领域中最激动人心的事件恐怕要数BERT的发布,这是一种基于多语言转换器的模型,它已经在各种NLP项目中取得了令人瞩目的成果。BERT是一种基于transformer架构的双向模型,它以一种速度更快的基于Attention的方法取代了RNN(LSTM和GRU)的sequential属性。
该模型还在两个无监督任务(“遮蔽语言模型”和“下一句预测”)上进行了预训练。这让我们可以通过对下游特定任务(例如情绪分类,意图检测,问答等)进行微调来使用预先训练的BERT模型。
本文将手把手教你,用BERT完成一个Kaggle竞赛。
在本文中,我们将重点介绍BERT在多标签文本分类问题中的应用。传统的分类问题假定每个文档都分配给一个且只分配给一个类别,即标签。这有时也被称为多元分类,比如类别数量是2的话,就叫做二元分类。
而多标签分类假设文档可以同时独立地分配给多个标签或类别。多标签分类具有许多实际应用,例如业务分类或为电影分配多个类型。在客户服务领域,此技术可用于识别客户电子邮件的多种意图。
我们将使用Kaggle的“恶意评论分类挑战”来衡量BERT在多标签文本分类中的表现。
在本次竞赛中,我们将尝试构建一个能够将给文本片段分配给同恶评类别的模型。我们设定了恶意评论类别作为模型的目标标签,它们包括普通恶评、严重恶评、污言秽语、威胁、侮辱和身份仇视。
比赛链接:
https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge
从哪开始?
Google Research最近公开了BERT 的tensorflow部署代码,并发布了以下预训练模型:
BERT-Base, Uncased: 12层,768个隐藏单元,自注意力的 head数为12,110M参数
BERT-Large, Uncased:24层,1024个隐藏单元,自注意力的 head数为16,340M参数
BERT-Base, Cased:12层,768个隐藏单元,自注意力的 head数为12,110M参数
BERT-Large, Cased:24层,1024个隐藏单元,自注意力的 head数为16,340M参数
BERT-Base, Multilingual Cased (最新推荐):104种语言,12层,768个隐藏单元,自注意力的 head数为12,110M参数
BERT-Base, Chinese:中文(简体和繁体),12层,768个隐藏单元,自注意力的 head数为12,110M参数
编者注:这里cased和uncased的意思是在进行WordPiece分词之前是否区分大小写。uncased表示全部会调整成小写,且剔除所有的重音标记;cased则表示文本的真实情况和重音标记都会保留下来。
我们将使用较小的Bert-Base,uncased模型来完成此任务。Bert-Base模型有12个attention层,所有文本都将由标记器转换为小写。我们在亚马逊云 p3.8xlarge EC2实例上运行此模型,该实例包含4个Tesla V100 GPU,GPU内存总共64 GB。
因为我个人更喜欢在TensorFlow上使用PyTorch,所以我们将使用来自HuggingFace的BERT模型PyTorch端口,这可从https://github.com/huggingface/pytorch-pretrained-BERT下载。我们已经用HuggingFace的repo脚本将预先训练的TensorFlow检查点(checkpoints)转换为PyTorch权重。
我们的实现很大程度上是以BERT原始实现中提供的run_classifier示例为基础的。
数据展示
数据用类InputExample来表示。
text_a:文本评论
text_b:未使用
标签:来自训练数据集的评论标签列表(很明显,测试数据集的标签将为空)
class InputExample(object):
"""A single training/test example for sequence classification."""
def __init__(self, guid, text_a, text_b=None, labels=None):
"""Constructs a InputExample.
Args:
guid: Unique id for the example.
text_a: string. The untokenized text of the first sequence. For single
sequence tasks, only this sequence must be specified.
text_b: (Optional) string. The untokenized text of the second sequence.
Only must be specified for sequence pair tasks.
labels: (Optional) [string]. The label of the example. This should be
specified for train and dev examples, but not for test examples.
"""
self.guid = guid
self.text_a = text_a
self.text_b = text_b
self.labels = labels
class InputFeatures(object):
"""A single set of features of data."""
def __init__(self, input_ids, input_mask, segment_ids, label_ids):
self.input_ids = input_ids
self.input_mask = input_mask
self.segment_ids = segment_ids
self.label_ids = label_ids
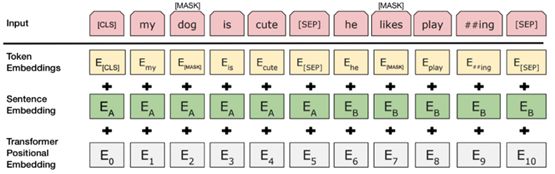
我们将InputExample转换为BERT能理解的特征,该特征用类InputFeatures来表示。
input_ids:标记化文本的数字id列表
input_mask:对于真实标记将设置为1,对于填充标记将设置为0
segment_ids:对于我们的情况,这将被设置为全1的列表
label_ids:文本的one-hot编码标签
标记化(Tokenisation)
BERT-Base,uncased模型使用包含30,522个单词的词汇表。标记化过程涉及将输入文本拆分为词汇表中可用的标记列表。为了处理不在词汇表中的单词,BERT使用一种称为基于双字节编码(BPE,Byte-Pair Encoding)的WordPiece标记化技术。
这种方法将不在词汇表之中的词一步步分解成子词。因为子词是词汇表的一部分,模型已经学习了这些子词在上下文中的表示,并且该词的上下文仅仅是子词的上下文的组合,因此这个词就可以由一组子词表示。要了解关于此方法的更多详细信息,请参阅文章《使用子词单位的稀有单词的神经网络机器翻译》。
文章链接:
https://arxiv.org/pdf/1508.07909
在我看来,这与BERT本身一样都是一种突破。
模型架构
我们将改写BertForSequenceClassification类以使其满足多标签分类的要求。
class BertForMultiLabelSequenceClassification(PreTrainedBertModel):
"""BERT model for classification.
This module is composed of the BERT model with a linear layer on top of
the pooled output.
"""
def __init__(self, config, num_labels=2):
super(BertForMultiLabelSequenceClassification, self).__init__(config)
self.num_labels = num_labels
self.bert = BertModel(config)
self.dropout = torch.nn.Dropout(config.hidden_dropout_prob)
self.classifier = torch.nn.Linear(config.hidden_size, num_labels)
self.apply(self.init_bert_weights)
def forward(self, input_ids, token_type_ids=None, attention_mask=None, labels=None):
_, pooled_output = self.bert(input_ids, token_type_ids, attention_mask, output_all_encoded_layers=False)
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
if labels is not None:
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1, self.num_labels))
return loss
else:
return logits
def freeze_bert_encoder(self):
for param in self.bert.parameters():
param.requires_grad = False
def unfreeze_bert_encoder(self):
for param in self.bert.parameters():
param.requires_grad = True
这里主要的改动是用logits作为二进制交叉熵的损失函数(BCEWithLogitsLoss),取代用于多元分类的vanilla交叉熵损失函数(CrossEntropyLoss)。二进制交叉熵损失可以让我们的模型为标签分配独立的概率。
下面的模型摘要说明了模型的各个层及其维度。
BertForMultiLabelSequenceClassification(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(28996, 768)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): FusedLayerNorm(torch.Size([768]), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1)
)
(encoder): BertEncoder(
(layer): ModuleList(
# 12 BertLayers
(11): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): FusedLayerNorm(torch.Size([768]), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): FusedLayerNorm(torch.Size([768]), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
(dropout): Dropout(p=0.1)
(classifier): Linear(in_features=768, out_features=6, bias=True)
)
BertEmbeddings:输入嵌入层
BertEncoder: 12个BERT模型attention层
分类器:我们的多标签分类器,out_features = 6,每个分类符对应6个标签
模型训练
训练循环与原始BERT实现中提供的run_classifier.py里的循环相同。我们的模型训练了4个epoch(一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一个 epoch),每批数据大小为32,序列长度为512,即预训练模型的最大可能性。根据原始论文的建议,学习率保持在3e-5。
因为有机会使用多个GPU,所以我们将Pytorch模型封装在DataParallel模块中,这使我们能够在所有可用的GPU上进行训练。
我们没有使用半精度FP16技术,因为使用logits 损失函数的二进制交叉熵不支持FP16处理。但这并不会影响最终结果,只是需要更长的时间训练。
评估指标
def accuracy_thresh(y_pred:Tensor, y_true:Tensor, thresh:float=0.5, sigmoid:bool=True):
"Compute accuracy when `y_pred` and `y_true` are the same size."
if sigmoid: y_pred = y_pred.sigmoid()
return np.mean(((y_pred>thresh)==y_true.byte()).float().cpu().numpy(), axis=1).sum()
from sklearn.metrics import roc_curve, auc
# Compute ROC curve and ROC area for each class
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(num_labels):
fpr[i], tpr[i], _ = roc_curve(all_labels[:, i], all_logits[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# Compute micro-average ROC curve and ROC area
fpr["micro"], tpr["micro"], _ = roc_curve(all_labels.ravel(), all_logits.ravel())
roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
我们为精度度量函数增加了一个阈值,默认设置为0.5。
对于多标签分类,更重要的指标是ROC-AUC曲线。这也是Kaggle比赛的评分指标。我们分别计算每个标签的ROC-AUC,并对单个标签的roc-auc分数进行微平均。
如果想深入了解roc-auc曲线,这里有一篇很不错的博客。
博客链接:
https://towardsdatascience.com/understanding-auc-roc-curve-68b2303cc9c5。
评估分数
我们重复进行了几次实验,每次都有一些输入上的变化,但都得到了类似的结果,如下所示:
训练损失:0.022,验证损失:0.018,验证准确度:99.31%。
各个标签的ROC-AUC分数:
普通恶评:0.9988
严重恶评:0.9935
污言秽语:0.9988
威胁:0.9989
侮辱:0.9975
身份仇视:0.9988
微观平均ROC-AUC得分:0.9987
这样的结果似乎非常令人鼓舞,因为我们看上去已经创建了一个近乎完美的模型来检测文本评论的恶毒程度。现在看看我们在Kaggle排行榜上的得分。
Kaggle竞赛结果
我们在Kaggle提供的测试数据集上运行推理逻辑,并将结果提交给竞赛。以下是结果:

我们的roc-auc评分达到了0.9863,在所有竞争者中排名前10%。为了使比赛结果更具说服力,这次Kaggle比赛的奖金为35000美元,而一等奖得分为0.9885。
最高分的团队由专业的高技能数据科学家和从业者组成。除了我们所做的工作之外,他们还使用各种技术来进行数据集成,数据增强(data augmentation)和测试时增强(test-time augmentation)。
结论和后续
我们使用强大的BERT预训练模型实现了多标签分类模型。正如我们所展示的那样,模型在已熟知的公开数据集上得到了相当不错的结果。我们能够建立一个世界级的模型生产应用于各行业,尤其是客户服务领域。
对于我们来说,下一步将是使用“遮蔽语言模型”和“下一句预测”对下游任务的文本语料库来微调预训练的语言模型。这将是一项无监督的任务,希望该模型能够学习一些我们自定义的上下文和术语,这和ULMFiT使用的技术类似。
资料链接:
https://nbviewer.jupyter.org/github/kaushaltrivedi/bert-toxic-comments-multilabel/blob/master/toxic-bert-multilabel-classification.ipynb
https://github.com/kaushaltrivedi/bert-toxic-comments-multilabel/blob/master/toxic-bert-multilabel-classification.ipynb
原始BERT论文:
https://arxiv.org/pdf/1810.04805
相关报道:
https://medium.com/huggingface/multi-label-text-classification-using-bert-the-mighty-transformer-69714fa3fb3d
志愿者介绍
后台回复“志愿者”加入我们









