XLNET:换一个思路做预训练,效果杠杠滴
来自:NLP从入门到放弃
XLNET[1]里面的细节点有很多,重点掌握以下两点:
-
AR和AE两种无监督预训练的优化目标 -
双流自注意力机制:为什么需要把位置信息和内容信息拆分
1. 无监督目标函数
在NLP中,无监督表示学习已经获得长足发展。一般的流程是先将模型在大量无标签数据上进行预训练,然后在具体的下游任务上进行微调。
一般来说,无监督预训练有两种目标函数很受重视:AR和AE。
-
AR,也就是autoregressive,我们称之为自回归模型;用 去预测 ,可以分为正向和反向,只能考虑单侧的信息,典型的就是GPT -
AE,也就是autoencoding,我们称之为自编码模型;从损坏的输入数据中预测重建原始数据。可以使用上下文的信息,Bert就是使用的AE;
AE模型能够看到句子中的更多的信息,这也是BERT在下游任务中表现很好的原因。
先来看一下优化目标,对于AR语言模型来说,它是基于概率的一个链式法则,优化如下:
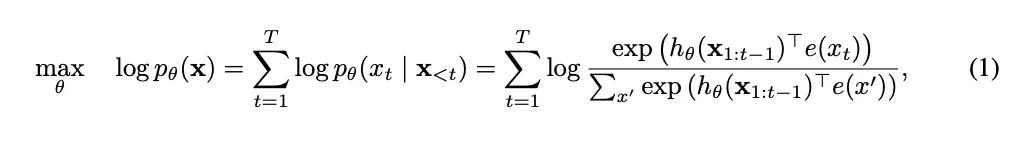
而AE模型,拿BERT举例,它的优化目标是是从损坏的输入数据中重建原始未被破坏的输入,优化目标如下:
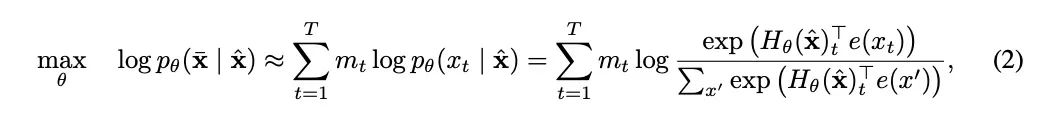
举个简单的例子,原始输入为【我爱吃饭】,那么AR模型在做的时候,它的优化是P(我爱吃饭) = P(我)P(爱|我)P(吃|我爱)P(饭|我爱吃);
与之对应的,假设我们mask之后为【我爱mask mask】,那么BERT的优化目标是:P(我爱吃饭|我爱maskmask)=P(吃|我爱)P(饭|我爱);
根绝这两个例子,我们首先知道对于AR模型,它在优化的时候,只能看到单向信息。
对于AE模型,它可以看到双向信息,但是有一个问题就是,它认为mask之间相互独立,也就是上面例子中【吃】和【饭】是相互独立的。
很显然,这一点是错误的,【吃】和【饭】之间肯定是有联系的,但是BERT在预训练的时候并没有考虑这一点。
BERT还有一个缺点就是,在预训练的时候,是存在mask字符的,但是在微调的时候,也就是在我们的在具体任务上训练的时候,我们的输入是不存在mask字符的,造成了预训练和微调之间的gap;
AR(单向缺点)和BERT(mask缺点)都存在缺点,XLNET想办法解决了这两个问题。
2. Permutation Language Modeling
为了解决AR模型不能关联上下文信息,提出这个策略。
如果我们的序列x的长度为T,那么对于这个序列,我们有T!种排列方式。
比如说,原始排列为1,2,3,4;那么对它进行重排列,就有24中排列方式。
我们挑两种来看:1,2,3,4和1,4,3,2;
在这两种排列中,假设我们都处于预测第三个位置3的时刻,那么对于第一种,它能够看到的内容信息来自1和2,对于第二种排列方式,它能够看到的内容信息来自1和4。
这样一来,对于3 来说,它在训练之后,既看到了前面的信息1和2,又看到了后面的信息4。
通过这种方式,AR模型可以联系到上下文的信息。
但是如何做到输入序列进行重排序呢,使用TSSA;这样输入序列顺序不会发生变化,顺序的变化只是发生在内部;
3. Two-Stream Self-Attention
假设我们先把某个点的信息分为内容信息和位置信息,为啥这么分,看完例子就知道了。
先来一个简单的例子,句子序列:1,2,3,4;
如果要是预测3,那么需要做什么:
首先,我需要1和2的全部信息(包括它们内容信息和位置信息);其次需要看到3当前这个点的位置信息,确保知道预测的是哪一个位置,但是我不能看到3这点的内容信息,因为我要预测这个单词,不能做到标签信息的泄露。
如果要是预测4,那么需要做什么:
首先,我需要1,2,3的全部信息(包括它们的内容信息和位置信息),其次,我需要看到4当前这个点的位置信息;
好了,两个例子联合起来看,对于3这个点,有的时候我需要向4提供全部信息(包括内容信息和位置信息),有的时候我需要向自己提供位置信息(不能包含内容信息,防止造成标签的泄露);
这就是为什么需要将信息分为内容信息和位置信息,如果不分开,那么对外提供信息的时候就不能有效的隔离。
仔细琢磨这个例子,对照着这个例子,可以看一下下面这个图:
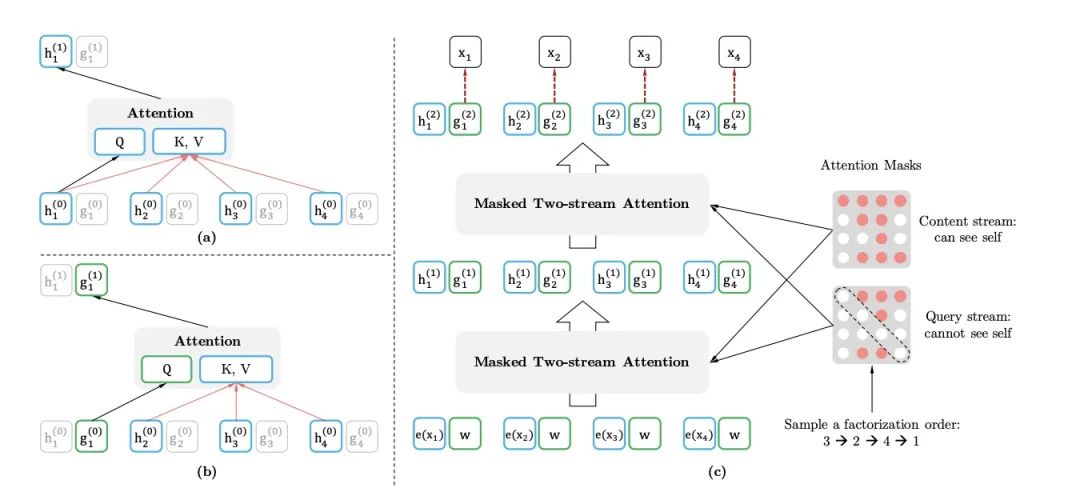
这个图,细节一点要注意,在计算位置信息的时候,QKV分别代表着什么?
这点需要大家仔细去看。
然后看c,在最后预测的时候我们使用的query stream,并没有使用content stream;这点需要注意;
4.其他细节
-
使用部分预测:句子预测起始阶段,上文信息较少,担心误差较大,所以只对句子后1/K的tokens被预测 -
使用Transformer-XL,用于处理长文本
5. 总结
说一下值得注意的点,主要就是双流自注意力机制这里很有意思,在初看图的时候很容易看混。
这么理解会更加的方便,对于同一个token,在预测自身的时候,它需要向外提供自己的位置信息,在预测别的单词的时候,它需要对外提供全部信息。
所以一个好办法就是把内容信息和位置信息分隔开对外提供。
参考资料
XLNet: Generalized Autoregressive Pretraining for Language Understanding: https://arxiv.org/abs/1906.08237,



