8篇论文梳理BERT相关模型进展与反思 | MSRA出品
原作:MSRA陈永强
量子位 授权转载 | 公众号 QbitAI
BERT 自从在 arXiv 上发表以来获得了很大的成功和关注,打开了 NLP 中 2-Stage 的潘多拉魔盒。
随后涌现了一大批类似于“BERT”的预训练(pre-trained)模型,有引入 BERT 中双向上下文信息的广义自回归模型 XLNet,也有改进 BERT 训练方式和目标的 RoBERTa 和 SpanBERT,还有结合多任务以及知识蒸馏(Knowledge Distillation)强化 BERT 的 MT-DNN 等。
除此之外,还有人试图探究 BERT 的原理以及其在某些任务中表现出众的真正原因。
以上种种,被戏称为 BERTology。
本文中,微软亚洲研究院知识计算组实习生陈永强尝试汇总上述内容,作抛砖引玉。

目录
近期 BERT 相关模型一览
XLNet 及其与 BERT 的对比
RoBERTa
SpanBERT
MT-DNN 与知识蒸馏
对 BERT 在部分 NLP 任务中表现的深入分析
BERT 在 Argument Reasoning Comprehension 任务中的表现
BERT 在 Natural Language Inference 任务中的表现
近期 BERT 相关模型一览
1. XLNet 及其与 BERT 的对比
我们的讨论从 XLNet 团队的一篇博文开始,他们想通过一个公平的比较证明最新预训练模型 XLNet 的优越性。但什么是 XLNet 呢?
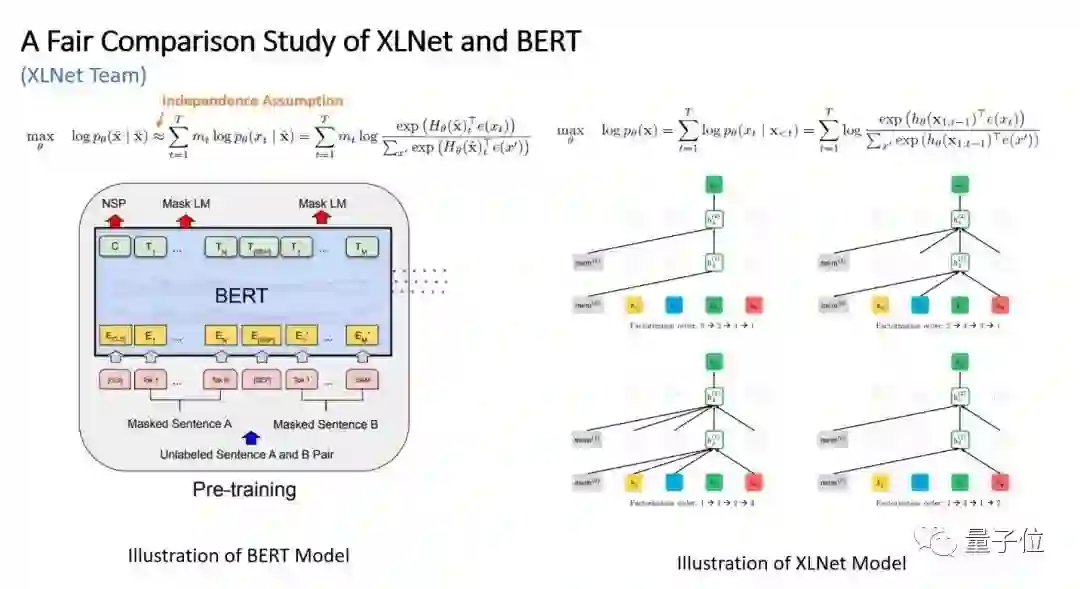
△图1:XLNet 和 BERT 对比图
我们知道,BERT 是典型的自编码模型(Autoencoder),旨在从引入噪声的数据重建原数据。而 BERT 的预训练过程采用了降噪自编码(Variational Autoencoder)思想,即 MLM(Mask Language Model)机制,区别于自回归模型(Autoregressive Model),最大的贡献在于使得模型获得了双向的上下文信息,但是会存在一些问题:
Pretrain-finetune Discrepancy:预训练时的[MASK]在微调(fine-tuning)时并不会出现,使得两个过程不一致,这不利于 Learning。
Independence Assumption:每个 token 的预测是相互独立的。而类似于 New York 这样的 Entity,New 和 York 是存在关联的,这个假设则忽略了这样的情况。
自回归模型不存在第二个问题,但传统的自回归模型是单向的。XLNet 团队想做的,就是让自回归模型也获得双向上下文信息,并避免第一个问题的出现。
他们主要使用了以下三个机制:
Permutation Language Model
Two-Stream Self-Attention
Recurrence Mechanism
接下来我们将分别介绍这三种机制。
Permutation Language Model

△图2:XLNet 模型框架图
在预测某个 token 时,XLNet 使用输入的 permutation 获取双向的上下文信息,同时维持自回归模型原有的单向形式。这样的好处是可以不用改变输入顺序,只需在内部处理。
它的实现采用了一种比较巧妙的方式:使用 token 在 permutation 的位置计算上下文信息。如对于,当前有一个 2 -> 4 ->3 ->1 的排列,那么我们就取出 token_2 和 token_4 作为AR 的输入预测 token_3。不难理解,当所有 permutation 取完时,我们就能获得所有的上下文信息。
这样就得到了我们的目标公式:
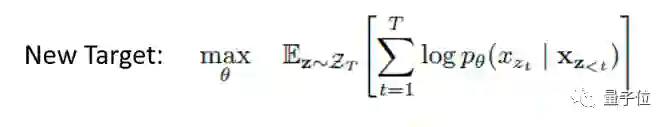
但是在原来的公式中,我们只使用了 hθ (x(Z<t)) 来表示当前token“上文”的 hidden representation,使得不管模型要预测哪个位置的 token,如果“上文”一致,那么输出就是一致的。因此,新的公式做出了改变,引入了要预测的 token 的位置信息。
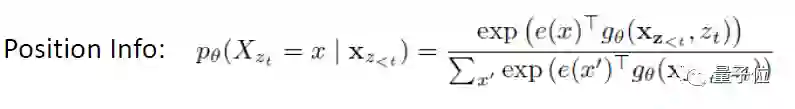
此外,为了降低模型的优化难度,XLNet 使用了 Partial Prediction,即只预测当前 permutation 位置 c 之后的 token,最终优化目标如下所示。
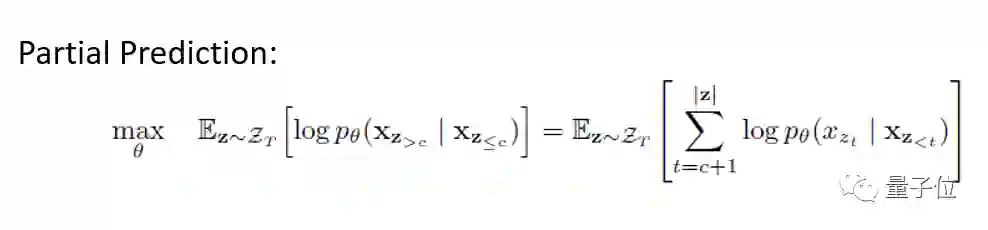
Two-Stream Self-Attention
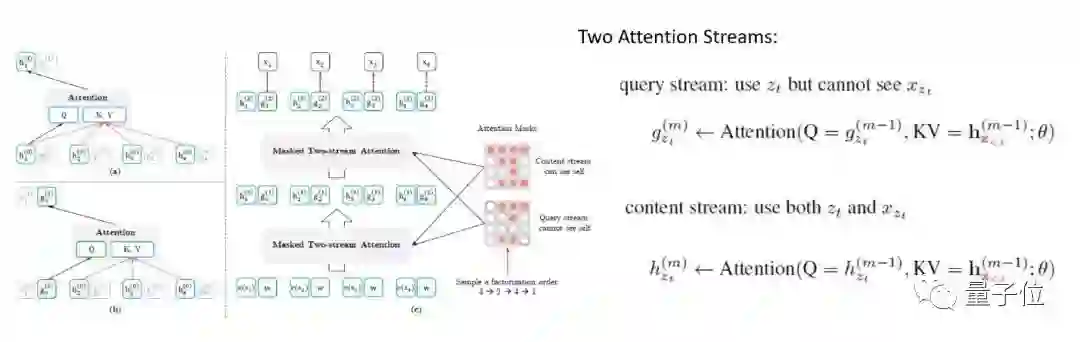
△图3:Two-Stream Self-Attention 机制
该机制所要解决的问题是,当我们获得了 gθ (x{Z<t},zt) 后,我们只有该位置信息以及“上文”的信息,不足以去预测该位置后的 token;而原来的 hθ (x_{Z<t}) 则因为获取不到位置信息,依然不足以去预测。因此,XLNet 引入了 Two-Stream Self-Attention 机制,将两者结合起来。
Recurrence Mechanism

△图4:Recurrence Mechanism 机制
该机制来自 Transformer-XL,即在处理下一个 segment 时结合上个 segment 的 hidden representation,使得模型能够获得更长距离的上下文信息。而在 XLNet 中,虽然在前端采用相对位置编码,但在表示 hθ (x{Z<t}) 的时候,涉及到的处理与permutation 独立,因此还可以沿用这个机制。该机制使得 XLNet 在处理长文档时具有较好的优势。
XLNet 与 BERT 的区别示例

△图5:XLNet 与 BERT 的区别示例
为了说明 XLNet 与 BERT 的区别,作者举了一个处理“New York is a city”的例子。这个可以直接通过两个模型的公式得到。假设我们要处理 New York 这个单词,BERT 将直接 mask 这两个 tokens,使用“is a city”作为上下文进行预测,这样的处理忽略了 New 和 York 之间的关联;而 XLNet 则通过 permutation 的形式,可以使得模型获得更多如 York | New, is a city 这样的信息。
公平地比较 XLNet 与 BERT
为了更好地说明 XLNet 的优越性,XLNet 团队发表了开头提到的博文“A Fair Comparison Study of XLNet and BERT”。
在这篇博文中,XLNet 团队控制 XLNet 的训练数据、超参数(Hyperparameter)以及网格搜索空间(Grid Search Space)等与 BERT 一致,同时还给出了三个版本的 BERT 进行比较。BERT 一方则使用以下三个模型中表现最好的模型。

实验结果如下。
表1:XLNet 与 BERT 实验结果对比
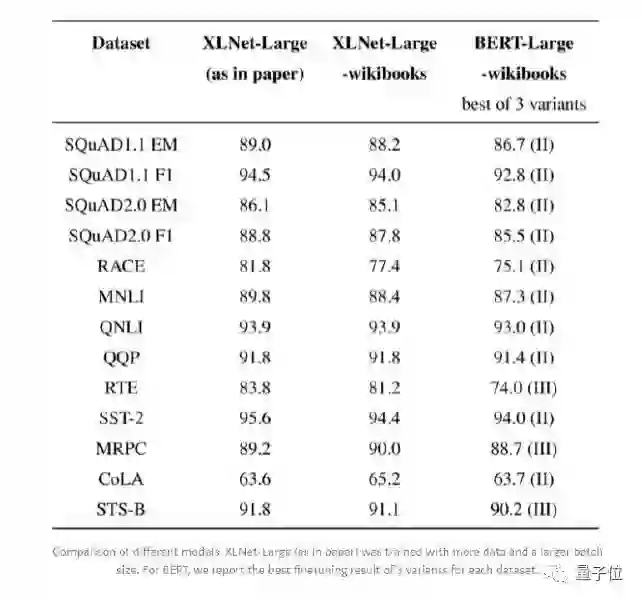
从中可以看出,在相同设定情况下,XLNet 完胜 BERT。但有趣的是:
XLNet 在使用 Wikibooks 数据集时,在MRPC(Microsoft Research Paraphrase Corpus: 句子对来源于对同一条新闻的评论,判断这一对句子在语义上是否相同)和 QQP(Quora Question Pairs: 这是一个二分类数据集。目的是判断两个来自于 Quora 的问题句子在语义上是否是等价的)任务上获得了不弱于原版 XLNet 的表现;
BERT-WWM 模型普遍表现都优于原 BERT;
去掉 NSP(Next Sentence Prediction)的 BERT 在某些任务中表现会更好;
除了 XLNet,还有其他模型提出基于 BERT 的改进,让 BERT 发挥更大的潜能。
2. RoBERTa: A Robustly Optimized BERT Pretraining Approach
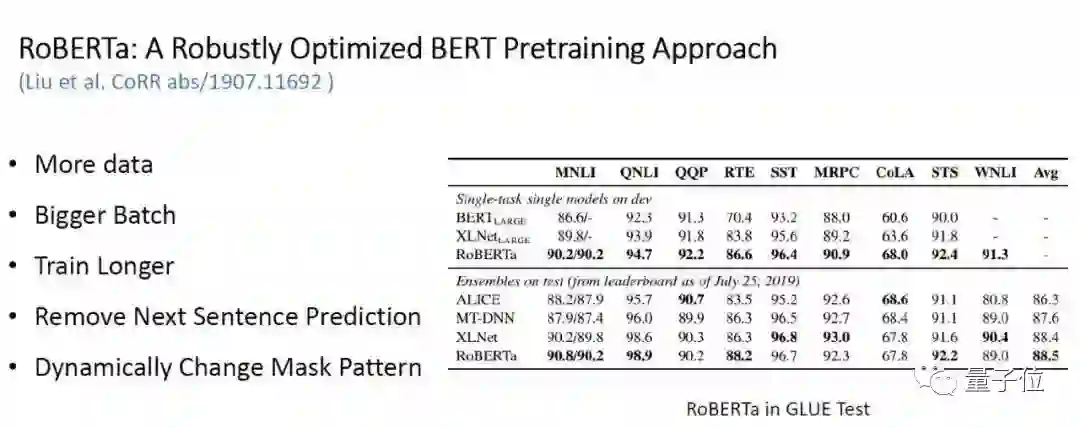
△表2:RoBERTa 在 GLUE 中的实验结果
RoBERTa 是最近 Facebook AI 联合 UW 发布的 BERT 预训练模型,其改进主要是如图所示几点,除了调参外,还引入了 Dynamically Change Mask Pattern 并移除 Next Sentence Prediction,使得模型在 GLUE Benchmark 排名第一。作者的观点是:BERT is significantly undertrained。

△表3:RoBERTa 各个机制的效果比较实验
不同于原有的 BERT 的 MLM 机制,作者在总共40个 epoch 中使用10种不同的 Mask Pattern,即每种 Mask Pattern 训练4代,作为 static 策略;作者还引入了 dynamic masking 策略,即每输入一个 sequence 就为其生成一个 mask pattern。
最终发现,新策略都比原 BERT 好,而 dynamic 总体上比 static 策略要好一些,并且可以用于训练更大的数据集以及更长的训练步数,因此最终选用 dynamic masking pattern。
作者还通过替换 NSP 任务进行预训练。虽然 BERT 中已经做了尝试去掉 NSP 后的对比,结果在很多任务中表现会下降,但是包括前文 XLNet 团队所做的实验都在质疑这一结论。
选用的新策略包括:
Sentence-Pair+NSP Loss:与原 BERT 相同;
Segment-Pair+NSP Loss:输入完整的一对包含多个句子的片段,这些片段可以来自同一个文档,也可以来自不同的文档;
Full-Sentences:输入是一系列完整的句子,可以是来自同一个文档也可以是不同的文档;
Doc-Sentences:输入是一系列完整的句子,来自同一个文档;
结果发现完整句子会更好,来自同一个文档的会比来自不同文档的好一些,最终选用 Doc-Sentences 策略。

△表4:RoBERTa 在更多训练数据和更久训练时间下的实验结果
作者还尝试了更多的训练数据以及更久的训练时间,发现都能提升模型的表现。
这种思路一定程度上与 OpenAI 前段时间放出的 GPT2.0 暴力扩充数据方法有点类似,但是需要消耗大量的计算资源。
3. SpanBERT: Improving Pre-training by Representing and Predicting Spans

△图6:SpanBER模型框架以及在 GLUE 中的实验结果
不同于 RoBERTa,SpanBERT 通过修改模型的预训练任务和目标使模型达到更好的效果。其修改主要是三个方面:
Span Masking:这个方法与之前 BERT 团队放出WWM(Whole Word Masking)类似,即在 mask 时 mask 一整个单词的 token 而非原来单个token。每次 mask 前,从一个几何分布中采样得到需要 mask 的 span 的长度,并等概率地对输入中为该长度的 span 进行 mask,直到 mask 完15%的输入。
Span Boundary Object:使用 span 前一个 token 和末尾后一个 token 以及 token 位置的 fixed-representation 表示 span 内部的一个 token。并以此来预测该 token,使用交叉熵作为新的 loss 加入到最终的 loss 函数中。该机制使得模型在 Span-Level 的任务种能获得更好的表现。
Single-Sequence Training:直接输入一整段连续的 sequence,这样可以使得模型获得更长的上下文信息。
在这三个机制下,SpanBERT 使用与 BERT 相同的语料进行训练,最终在 GLUE 中获得82.8的表现,高于原版 Google BERT 2.4%,高于他们调参后的 BERT 1%,同时在 Coreference Resolution 上将最好结果提高了6.6%。
4. MT-DNN 与知识蒸馏
Multi-Task Deep Neural Networks for Natural Language Understanding
这篇论文旨在将 Multi-Task 与 BERT 结合起来,使得模型能在更多的数据上进行训练的同时还能获得更好的迁移能力(Transfer Ability)。

△图7:MT-DNN 模型框架以及训练算法
模型架构如上图所示,在输入以及 Transformer 层,采用与 BERT 相同的机制,但是在后续处理不同任务数据时使用不同的任务参数与输出的表示做点积(Dot Production),用不同的激活函数(Activation Function)和损失函数(Loss Function)进行训练。

△图8:MT-DNN 在不同任务之间的迁移能力
MT-DNN 具有不错的迁移能力。如上图所示,MT-DNN 只需要23个任务样本就可以在 SNLI 中获得82%的准确率!尤其是 BERT 在一些小数据集上微调可能存在无法收敛表现很差的情况,MT-DNN 就可以比较好地解决这一问题,同时节省了新任务上标注数据以及长时间微调的成本。
Improving Multi-Task Deep Neural Networks via Knowledge Distillation for Natural Language Understanding
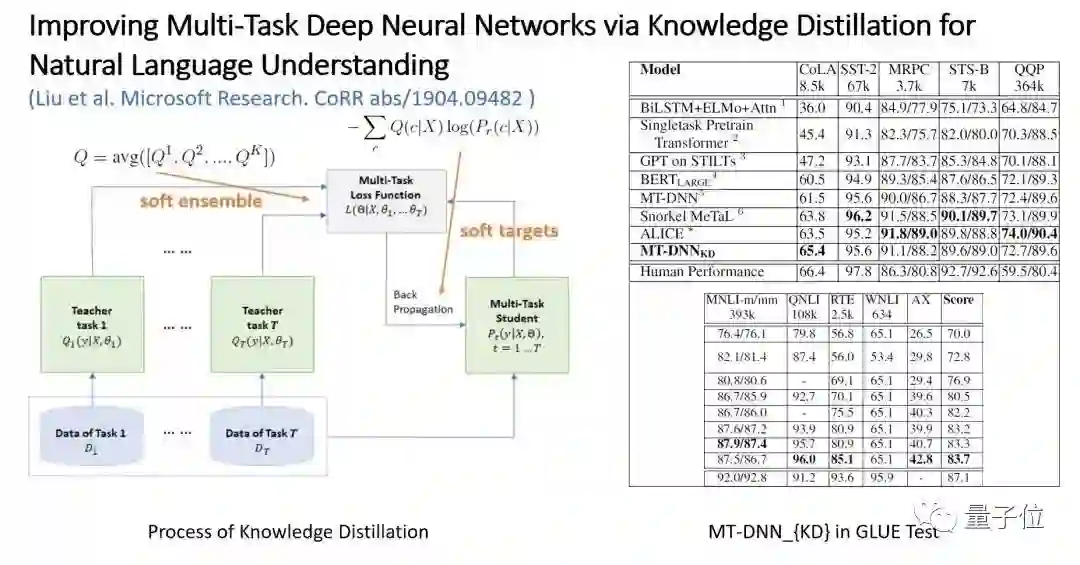
△图9:使用知识蒸馏对 MT-DNN 模型进行优化
由于 MT-DNN 可以看作一个 ensemble 过程,所以就可以用知识蒸馏(Knowledge Distillation)进行优化,该方法能提升很多 ensemble 模型的表现,感兴趣的读者可以自行了解相关内容。
本文的知识蒸馏过程即对于不同的任务,使用相同的结构在对应的数据集上进行微调,这就可以看作每个任务的 Teacher,他们分别擅长解决对应的问题。
Student 则去拟合 target Q,并且使用 soft 交叉熵损失(Cross Entropy Loss)。为什么使用 soft 交叉熵损失呢?因为有些句子的意思可能并不是绝对的,比如“I really enjoyed the conversation with Tom”有一定概率说的是反语,而不是100%的积极意思。这样能让 Student 学到更多的信息。
采用知识蒸馏后,模型在 GLUE 中的表现增长了1%,目前排名前三。我们还可以期待 MT-DNN 机制在 XLNet 上等其他预训练模型中的表现。
对 BERT 在部分 NLP 任务中表现的深入分析
上文的 BERT 在 NLP 许多任务中都取得了耀眼的成绩,甚至有人认为 BERT 几乎解决了 NLP 领域的问题,但接下来的两篇文章则给人们浇了一盆冷水。
1. BERT 在 Argument Reasoning Comprehension 任务中的表现
Probing Neural Network Comprehension of Natural Language Arguments
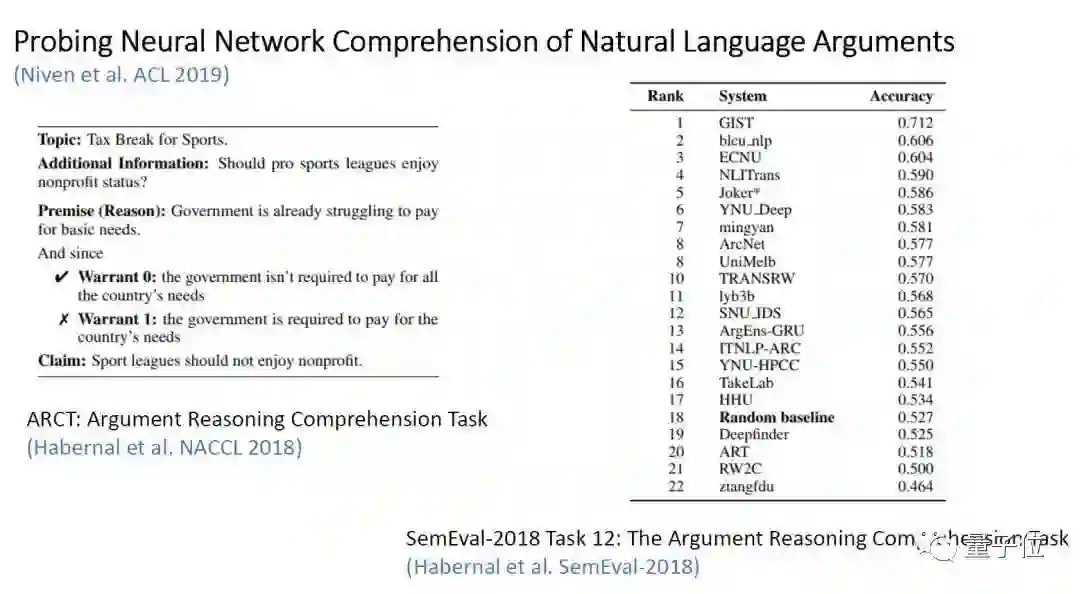
△表5:BERT 在 Argument Reasoning Comprehension 任务中的表现
该文主要探究 BERT 在 ARCT(Argument Reasoning Comprehension)任务中取得惊人表现的真正原因。
首先,ARCT 任务是 Habernal 等人在 NACCL 2018 中提出的,即在给定的前提(premise)下,对于某个陈述(claim),相反的两个依据(warrant0,warrant1)哪个能支持前提到陈述的推理。
他们还在 SemEval-2018 中指出,这个任务不仅需要模型理解推理的结构,还需要一定的外部知识。在本例中,这个外部知识可以是“Sport Leagues 是一个和 Sport 相关的某组织”。
该任务中表现最好的模型是 GIST,这里不详细展开,有兴趣的读者可以关注该论文。
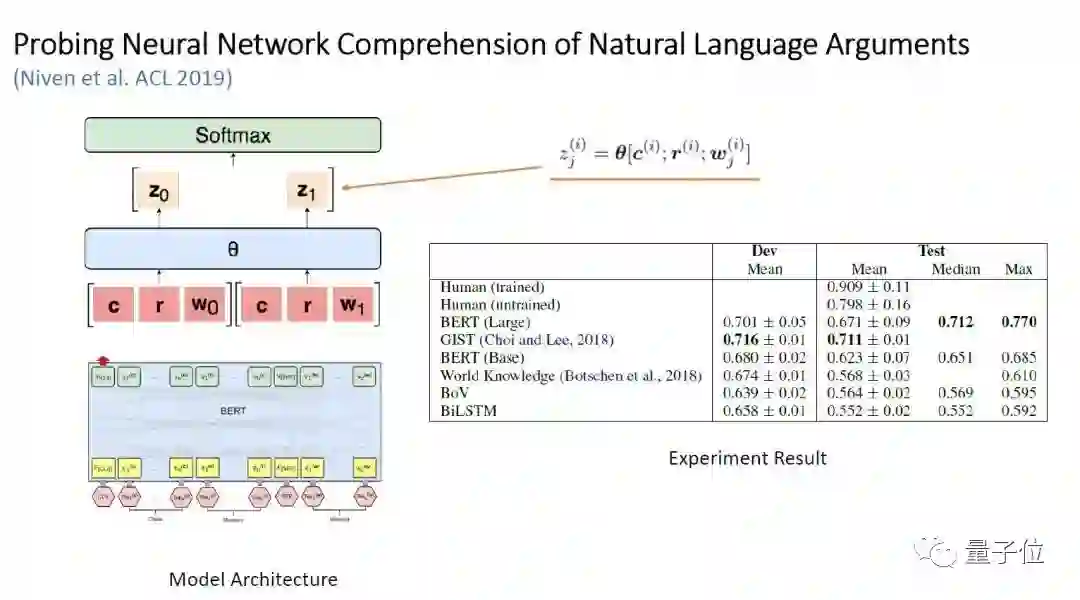
△图10:模型框架与实验结果
作者尝试使用 BERT 处理该任务,调整输入为[CLS,Claim,Reason,SEP,Warrant ],通过共用的 linear layer 获得一个 logit(类似于逻辑回归),分别用 warrant0 和 warrant1 做一次,通过 softmax 归一化成两个概率,优化目标是使得答案对应的概率最大。
最终该模型在测试集中获得最高77%的准确率。需要说明的是,因为 ARCT 数据集过小,仅有1210条训练样本,使得 BERT 在微调时容易产生不稳定的表现。因此作者进行了20次实验,去掉了退化(Degeneration,即在训练集上的结果非常差)的实验结果,统计得到上述表格。

△表6:作者的探索性实验(Probing Experiments)
虽然实验结果非常好,但作者怀疑:这究竟是 BERT 学到了需要的语义信息,还是只是过度利用了数据中的统计信息,因此作者提出了关于 cue 的一些概念:
A Cue’s Applicability:在某个数据点 i,label 为 j 的 warrant 中出现但在另一个 warrant 中不出现的 cue 的个数。
A Cue’s Productivity:在某个数据点 i,label 为 j 的 warrant 中出现但在另一个 warrant 中不出现,且这个数据点的正确 label 是 j,占所有上一种 cue 的比例。直观来说就是这个 cue 能被模型利用的价值,只要这个数据大于50%,那么我们就可以认为模型使用这个 cue 是有价值的。
A Cue’s Coverage:这个 cue 在所有数据点中出现的次数。
这样的 cue 有很多,如 not、are 等。如上图表一所示是 not 的出现情况,可以看出 not 在64%的数据点中都有出现,并且模型只要选择有 not 出现的 warrant,正确的概率是61%。
作者怀疑模型学到的是这样的信息。如果推论成立,只需输入 warrant,模型就能获得很好的表现。因此作者也做了上图表二所示的实验。
可以看出,只输入 w 模型就获得了71%的峰值表现,而输入(R,W)则能增加4%,输入(C,W)则能增加2%,正好71%+4%+2%=77%,这是一个很强的证据。
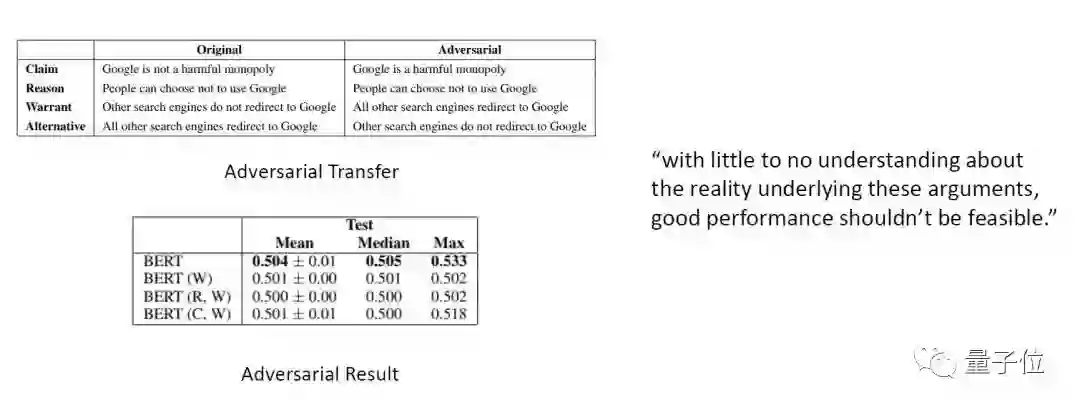
△图11:对抗数据集以及在对抗数据集上的实验结果
为了充分证明推论的正确性,作者构造了对抗数据集(Adversarial Dataset),如上图例子所示,对于原来的结构:R and W -> C,变换成:Rand !W -> !C(这里为了方便,用!表示取反)
作者首先让模型在原 ARCT 数据集微调并在对抗数据集评测(Evaluation),结果比随机还要糟糕。后来又在对抗数据集微调并在对抗数据集评测,获得表现如上图第二个表所示。
从实验结果来看,对抗数据集基本上消除了 cue 带来的影响,让 BERT 真实地展现了其在该任务上的能力,与作者的猜想一致。
虽然实验稍显不足(如未充分说明模型是否收敛,其他模型在对抗数据集中的表现如何等),但本文给 BERT 的火热浇了一盆冷水,充分说明了 BERT 并不是万能的,我们必须冷静思考 BERT 如今取得惊人表现的真正原因。
2. BERT 在 Natural Language Inference 任务中的表现
Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language
这是另一篇对 BERT 等模型在自然语言推理(Natural Language Inference,NLI)任务中表现的探讨。

△图12:NLI 任务中 Heuristic 示意图
作者首先假设在 NLI 中表现好的模型可能利用了三种 Heuristic,而所谓的 Heuristic 即在 Premise 中就给了模型一些提示,有如下三种:
Lexical Overlap:对应的 Hypothesis 是 Premise 的子序列
Subsequence:对应的 Hypothesis 是 Premise 的子串
Constituent:Premise 的语法树会覆盖所有的 Hypothesis
基于这个假设,作者也做了实验并观察到,MNLI 训练集中许多数据点都存在这样的 Heuristic,且对应的选项是正确的数量远多于不正确。针对这种情况,作者构造了 HANS 数据集,均衡两种类型样本的分布,并且标记了 premise 是否 entail 上述几种 Heuristic。
实验时模型在 MNLI 数据集微调,在 HANS 数据集评测,结果 entailment 类型的数据点中模型都表现不错,而在 non-entailment 类型中模型表现欠佳。这一实验结果支持了作者的假设:模型过度利用了 Heuristic 信息。
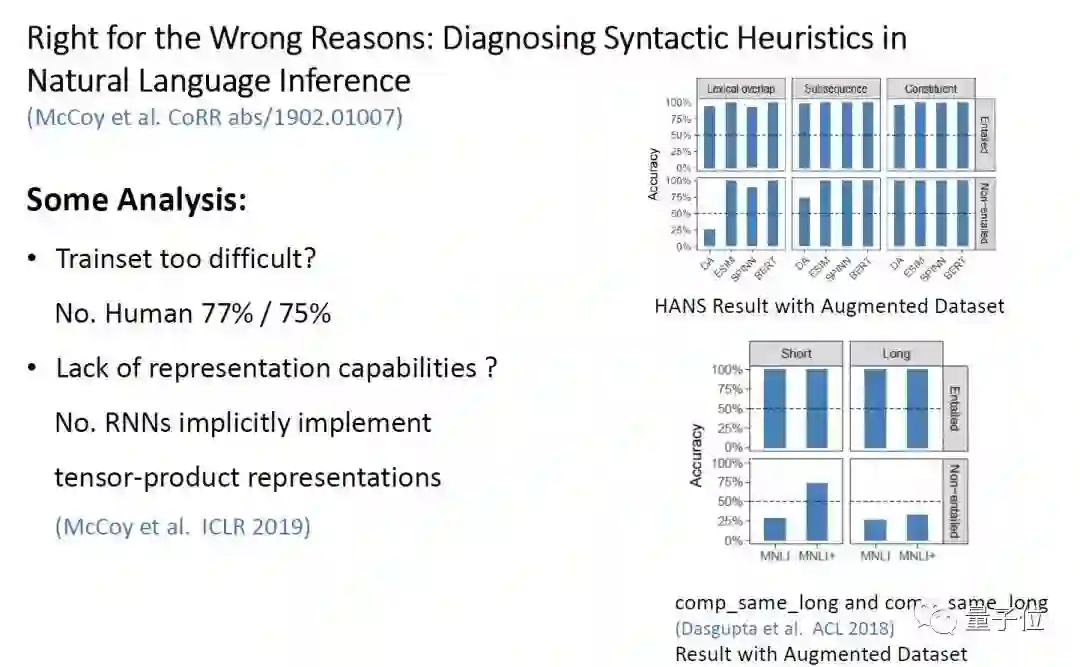
△图13:模型在 HANS 数据集上的结果分析
但是作者并不十分确定这种实验结果是什么原因导致的,并提出如下猜想:
HANS 数据集太难了?不。作者让人类进行测试,发现人类在两种类型的数据中准确率分别为77%和75%,远高于模型。
是模型缺乏足够的表示能力吗?不。ICLR 2019《RNNs implicitly implement tensor-product representations》给出了一定的证据,表示 RNN 足够在 SNLI 任务中已经学到一定的关于结构的信息。
那就是 MNLI 数据集并不好,缺乏足够的信号让模型学会 NLI。
因此作者在训练集中加入了一定的 HANS 数据,构造了 MNL+数据集,让模型在该数据集微调,最终获得了如上图所示的结果。为了证明 HANS 对模型学到 NLI 的贡献,作者还让在 MNL+上微调的模型在另一个数据集中做了评测,模型表现都有提升。
总结
本文总结了 BERT 提出以来一些最新的发展。
BERT 是一个优秀的预训练模型,它的预训练思想可以用来改进其他模型。BERT 可以更好,我们可以设置新的训练方式和目标,让其发挥更大的潜能。
但 BERT 并没有想象中的那么好,我们必须冷静对待 BERT 在一些任务中取得不错表现的原因——究竟是因为 BERT 真正学到了对应的语义信息,还是因为数据集中数据的不平衡导致 BERT 过度使用了这样的信号。
点击阅读原文,即可下载本文内容相关PPT。
参考文献:
[1] XLNet: Generalized Autoregressive Pretraining for Language Understanding. Yang et al.CoRR abs/1906.08237.
[2] A Fair Comparison Study of XLNet and BERT. XLNet Team.
https://medium.com/@xlnet.team/a-fair-comparison-study-of-xlnet-and-bert-with-large-models-5a4257f59dc0
[3] Probing Neural Network Comprehension of Natural Language Arguments. Niven et al. ACL2019.
[4] Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference. McCoy el al. Corr abs/1902.01007.
[5] RoBERTa: A Robustly Optimized BERT Pretraining Approach. Liu et al. CoRR abs/190.11692.
[6] SpanBERT: Improving Pre-training by Representing and Predicting Spans. Joshi et al. CoRRabs/1907.10529.
[7] Multi-Task Deep Neural Networks for Natural Language Understanding. Liu et al. CoRR abs/1901.11504.
[8] Improving Multi-Task Deep Neural Networks via Knowledge Distillation for Natural Language Understanding. Liu et al. CoRR abs/1904.09482.
— 完 —
加入社群 | 与优秀的人交流

小程序 | 全类别AI学习教程


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !

