AAAI 2019论文解读:机器人和认知学习
机器之心原创
作者: Joni
编辑:Hao
本文介绍了三篇AAAI 2019 论文,前两篇分别研究了机器人如何学习环境中的物品拥有权以及对物品的操作能力,后一篇研究了是否能用当今的深度学习方法来模拟简单的人类认知活动。
分析师简介:Joni 目前是日本国立产业综合研究所的研究员。在中国大陆本科本行是自动化,后来对机器人研究有兴趣,在香港就读了电机工程的 Mphil 学位。博士时开始着迷生物学和脑科学的机器人研究,因此在德国汉堡大学参与了认知机器人的欧盟项目。此后一直欧洲,英国,日本和中国研究和讨论神经科学,生物学和机器人之间共通之处。
机器之心主页: https://www.jiqizhixin.com/users/24e7c39e-98c4-4dd9-8d36-26d6207e1b67
That's Mine! Learning Ownership Relations and Norms for Robots
Zhi-Xuan Tan, Jake Brawer, Brian Scassellati
Link: https://arxiv.org/abs/1812.02576
「That's mine! Learning ownership relations and norms for robots」这篇文章出自耶鲁大学的 Scassellati 教授和他的合作者。Scassellati 教授是 social robotics 的其中一位重要的研究者。这篇文章主要解决了一个问题:机器人怎样通过人机交互中,学习环境中的物品拥有权问题。这种物品拥有权问题,可以进一步扩展为机器人学习社会和人类的规范的问题。
文章主要介绍了解决这个问题的两个基本步骤:1)怎样把拥有权问题用数学语言建模;2)机器人怎样在交互中学习这些模型。
1 建模
因为用户对物品的拥有权不是简单的 1 对 1 对应的问题,而且一个用户对物品的所有权以为着一系列的责任和权利,另外一件物品可能被几个人同时拥有。为了完整地表达用户,所有权,规范这三者关系,就需要把物品、主人和(物品的)规范这些都包含在不同的知识表达中。因此文章把拥有权问题建模变成三个子问题:1)用谓语逻辑把拥有权和物品联系起来; 2)用数据库维护针对物品的动作权限(在文中只是针对有主人和无主人的物品);3)用概率图模型维护物品和各用户的所有关系。
1.1 物品拥有权和规范的联系
怎样把物品所有权和规范联系起来呢?比如说有一个规范说机器人不能丢掉有主人的物品,那么通过之前的物品所有权的学习,机器人眼中的物品所有权规可以通过 Prolog 范式进行描述,例如:
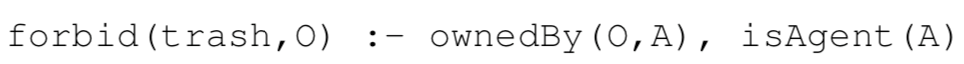
这个式子中,O 表示任意物品,A 表示一个个体。所以这个式子在系统中的规则描述就是:
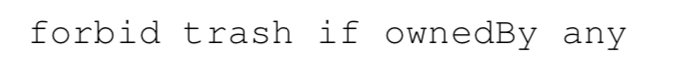
这种关系是文章侧重介绍的重点,之后介绍的机器人利用概率推论进行学习过程也是主要针对这个部分。
1.2 关于物品的权限的规范处理
社会的规范可以包含很多方面,对于以机器人-物品互动为中心的权限,最主要的就是禁止(forbid)对某件物品进行动作。因此在文章中的权限,主要指 allow 和 forbid 两种权限处理,以谓语逻辑进行表示,就是 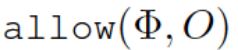
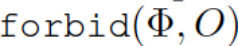
1.3 概率图模型表示所有权
文章用双向图表示物品的所有权,其中物品顶点(object node)和用户(agent node)之间的边(edge)表述该用户拥有该物品的概率。另外这个概率只是表示机器人猜测该物品被用户 n 拥有的猜测,是没有互斥性的。所以如果一个物品有 n 个潜在的拥有者,n 个概率相加可能会大于 1。这种一个物品被多个用户拥有的情况也是符合现实情况的。
2 拥有权学习
学习过程是通过人机交互更新上述三种知识表示的过程。比如说当一个用户指示机器人不要拿起一个看似没人用的茶杯时说:「不要拿,这是 Cassey 的茶杯」。这句简单的话需要同时更新三个知识表示:1. 拥有权:茶杯是属于 Cassey 的;2. 权限:机器人禁止(forbid)拿起茶杯;3.(一般的)社会规范:机器人不应该拿起茶杯,因为它是属于 Cassey(或者其他人的)。另外用户在人机交互中的命令有多种形式,可能只是一般性的拥有权指示,或者权限指示,或者两者俱有,因此当具有其他两种知识时,机器人系统也应该具有推断预测第三种知识表示的能力。所以如下图所示,本文是根据 forbid 的命令,可以推测学习物品拥有权,或者学习相反的规则:
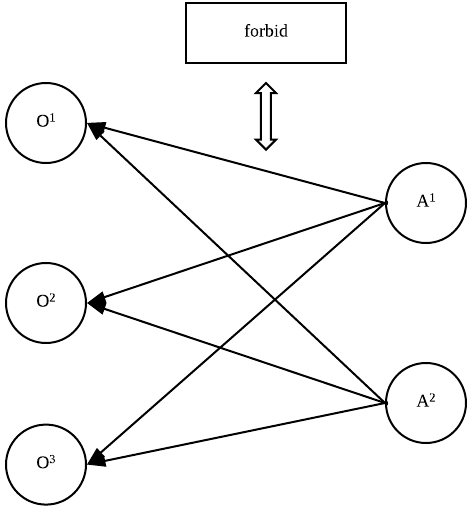
2.1 规则学习
在学习知识的算法上,文中也提出了 3 个步骤,其中第 1 步是针对知识表示中的第 2 中,学习以物品为中心的权限处理,文中定义了禁止(forbid)是正样本(positive example),允许(allow)为负样本(Negative example),提出了 4 种规则学习算法。


其中算法 1 和 2 是基于 separate-and-conquer 算法,separate-and-conquer 算法也叫 covering 算法 [1.1],它反复专门化制定一般规则进行迭代。在每一个迭代选择专门的规则,让该规则涵盖正样本的子集并排除负面的例子。在我们的例子中,例子主要是通过人机命令样本(「不许拿桌上的茶杯」)来建立物品的拥有权的猜测。
而且因为这种规则学习是建立于与人环境交互中的,与一般的 separate-and-conquer 算法不一样,这是一种在线学习过程,当一个新的样本被接收时,规则的改变是通过 beam search 逐渐改变,规则的更新是基于一个返回值 score 来确定是否接纳/移除新的规则。另外 separate-and-conquer 规则跟流行的 divide-and-conquest 的主要区别是该算法考虑新规则时,会同时考虑正负两方,会尽量最大化正样本和最小化负样本。关于 separate-and-conquer 和 divide-and-conquest 的结合和比较,可以参考 [1.2]:
当用户直接提出一个规则(例如「不要拿脏的东西」),机器人可以利用算法 3 和 4 直接进行 one-shot learning。但要注意在算法 3 加入的正规则(forbid)要尽量不满足负样本(negative example),算法 4 中的负规则(allow)尽量不满足正样本(positive example)。
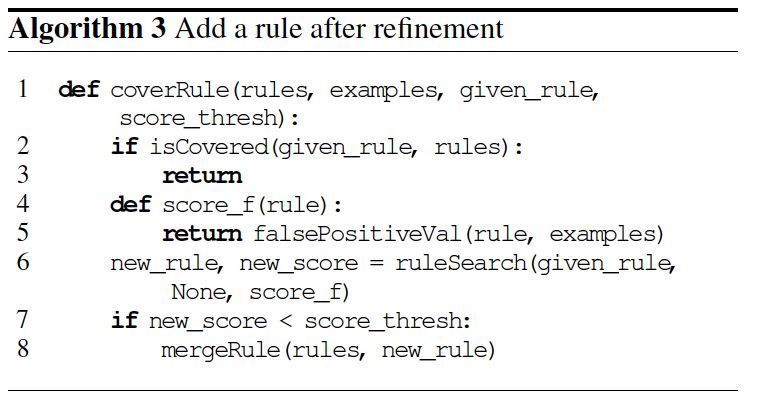

2.2 通过环境的所有权预测
机器人可以通过对环境的感知,预测物品的所有权。比如一个人在一个物品附近时,机器人会认为附近桌子上的物品是属于这个人的。因为机器人操作的动态和稀疏场景,所以文中采用了 KLR(Kernal Logistic Regression)分类物品的所有权(的概率)。KLR 采用了物品的颜色,位置和用户互动的时间来估计该概率。(但这个文中没有详细说,估计有另外的论文描述)。
2.3. 所有权推测
所有权推测跟预测不同,「推测」是机器人根据用户的命令(比如「禁止拿茶杯」)通过贝叶斯公式推测该物品被拥有的概率。
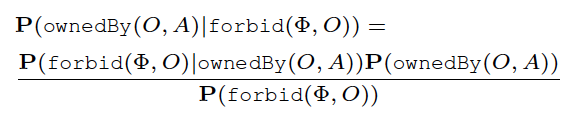
2.4. 三者组合
将上述 3 种学习结合起来需要处理两种矛盾问题:2.1 和 2.3,当引进的规则跟贝叶斯学习的规则相排斥,文中采用了更适合实际工程的启发性算法,参考了推测的规则的概率:如果 10% 或者以上的用户直接规则跟推测的规则相反,系统将尝试引入新的规则。相反,规则不会被更新,而只会被用到所有权推测。
另外,为了解决机器人的感知 2.2 和所有权推测 2.3 的矛盾可能性,文章直接采用了将 2.2 的结果作为 2.3 的输入(比如 P(ownby(O,A))。
3 实验
文章主要采用了模拟器实验结合实际机器人的视频演示。其中模拟器实验定量分析了三个实验:
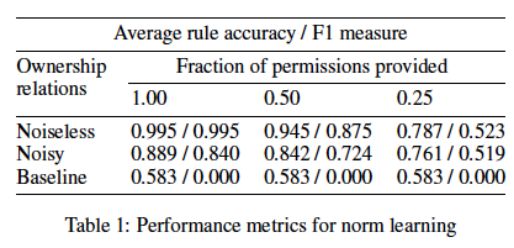
3.1 规则学习
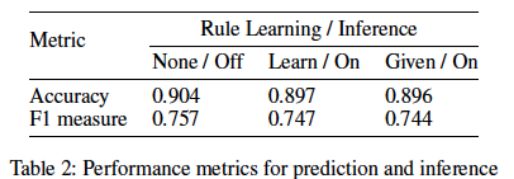
提供以物品为中心的指示,学习一般性规则。可以看出在有噪音的情况下,如果允许率为 0.25,F1 只在 0.5 上下。
3.2 所有权预测和推测
这个实验主要测试 2.2 和 2.3 的内容。结果现实无论在规则提供与否,结果相差不大,显示在学习过程中 2.2 和 2.3 结合的比较紧密(也可能是因为 2.2 的输出其实也是 2.3 的输入)
另外文章也进行了任务测试和视频演示 https://bit.ly/2z8obET,总体来说文中的解决的问题(让机器人在互动中学习规则)很有创新性,但提出的方法缺乏比较性,而且实验数据似乎还有提高空间(可能是算法问题,也可能是思路问题)。
分析师评论:这篇文章利用规则算法和其他(主要的)符号算法,试图让机器人在人机交互中理解物品的所有权和社会规则问题。因为整个系统是几个问题的结合,作为采用了几种不同的方法(包括规则学习,贝叶斯学习,视频分类等)。作者尝试用一篇短短 8 页的文章来介绍整个所有权分析推测的机器人系统似乎有点短,所以有些技术细节一笔带过了,读者似乎要读取其他的引用文章来获取更多的信息。另外实验中的样本也比较偏少,虽然作为一篇会议文章(虽然是 tier one 会议)是足够,但期待作者可以进行更多的实验和写更多的技术细节到下一篇文章(比如期刊文章)中。
Mirroring without Overimitation: Learning Functionally Equivalent Manipulation Actions
Hangxin Liu, Chi Zhang, Yixin Zhu, Chenfanfu Jiang, Song-Chun Zhu
Link:
http://www.stat.ucla.edu/~sczhu/papers/Conf_2019/AAAI2019_Mirroring_Actions.pdf
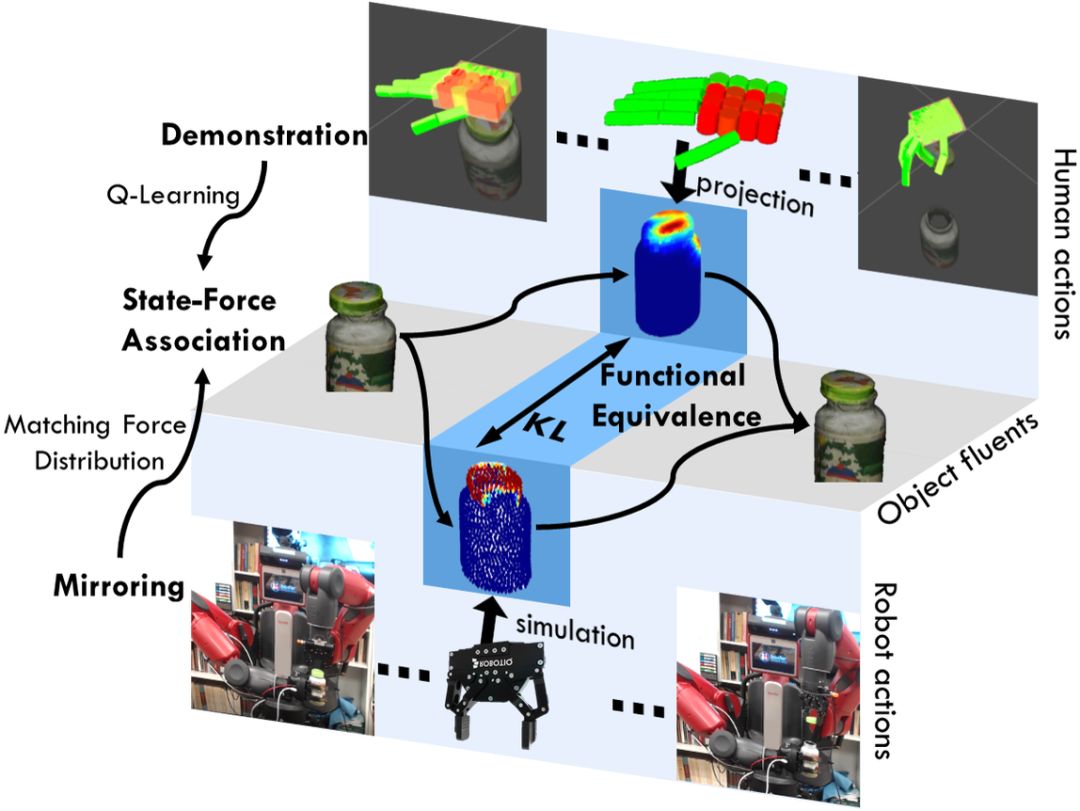
第二篇文章是著名的 UCLA 朱松纯教授和他的合作者贡献的文章「Mirroring without Overimitation: Learning Functionally Equivalent Manipulation Actions」。但这个研究跟朱教授擅长的计算机视觉有联系但不是完全相关,而是利用示教(LfD(learning from demonstration)),令机器人模拟人的镜像神经元(Mirror Neuron)运作进而来控制机器人的对物品的操作能力。当然 LfD 和镜像神经元都不是最创新的概念,但该文跟之前的 LfD 不同之处是提出了机器人的示教学习应该「功能等同性」(functionally equivalent)。具体来说,机器人模拟人的动作,不需要完全学习每个细节动作(overimitation),而只需要学习完成对应的目标。因此在本文的上下文中,「目标」(goal) 被定义为目标对象的期望状态并该状态应该语法模型中编码。
本文的创新性在于 1) 采用了触觉手套来感应不同程度的力度,2) 通过 Q 强化学习和语义模型,以目标为主(goal-directed)学习对应的状态和力度;3)利用物理模拟器模拟不同的机器人动作和力度可以建立功能等同的动作。
1. 知识表示
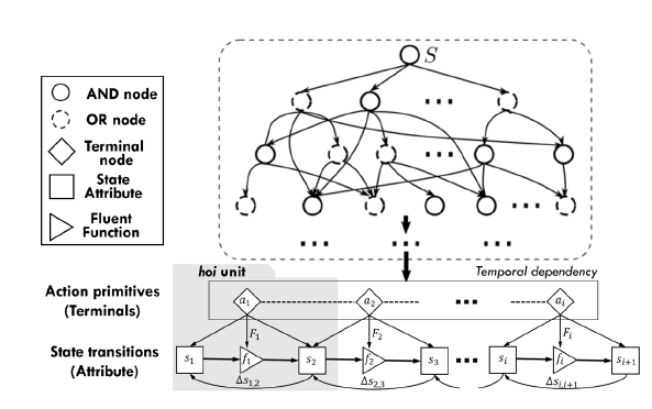
文章把完成一个目标动作处理成层次性 Temporal And-Or Graph (T-AOG) 的数据结构。T-AOG 是朱老师一直推崇的层次级有向图模型,可以用下面的序列描述
G=(S,V,R,P, σ),其中 S 表示一个具体的目标动作,比方说「打开水瓶」,而 V 是代表有向图中的「And Node」或者「Or Node」。图中的最末端表示的是各个基本动作,表示把环境(物体)从一个状态 S_t,通过力量 F,到另外一个状态S_{t+1} 的过程。因此学习过程变成学习各个节点之间的概率 P(α | β) = P(r) 的过程。
2 学习过程
2.1 强化学习施力和状态的关系
为了便于实现,文章使用对象上的力分布作为力的状态空间,并将 K 均值聚类应用于由不同机器人动作生成的力分布。然后对组中的力分布进行平均和归一化。对于状态表示,文章将瓶盖的距离和角度离散化并将它们标准化为 [0,1]。最后,以时间差异的方式应用着名的 Q 学习规则来学习力和状态关联。
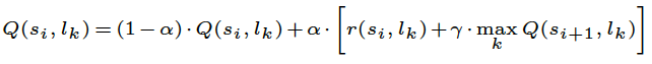
2.2 学习目标导向的语法
由策略学习的人 - 对象交互(hoi)序列自然地形成来自隐式语法的解析句子的空间。因此,可以按照后验概率通过 ADIOS [2.1] 恢复语法结构。
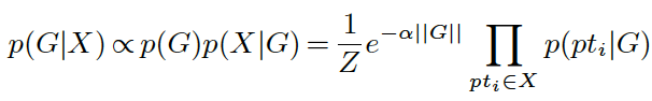
2.3 镜像学习
为了让机器人学习动作镜像但又避免过度模仿,文章利用了基于物理的 Neo-Hookean 模型模拟器对学习出来的模型进行测试。镜像动作首先通过模拟下的力分布来操作,然后与学习得出的力分布进行比较。然后选择与学习的力的概率分布的最小距离的动作(如下图所示)。在本文中使用 KL 散度作为距离度量。
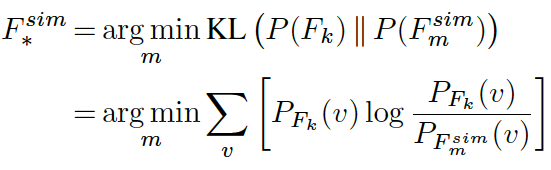
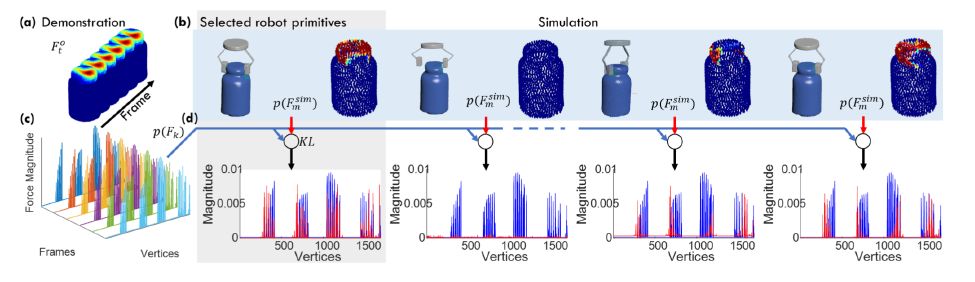
最后本文的各项功能集成起来如下图所示:
3 实验
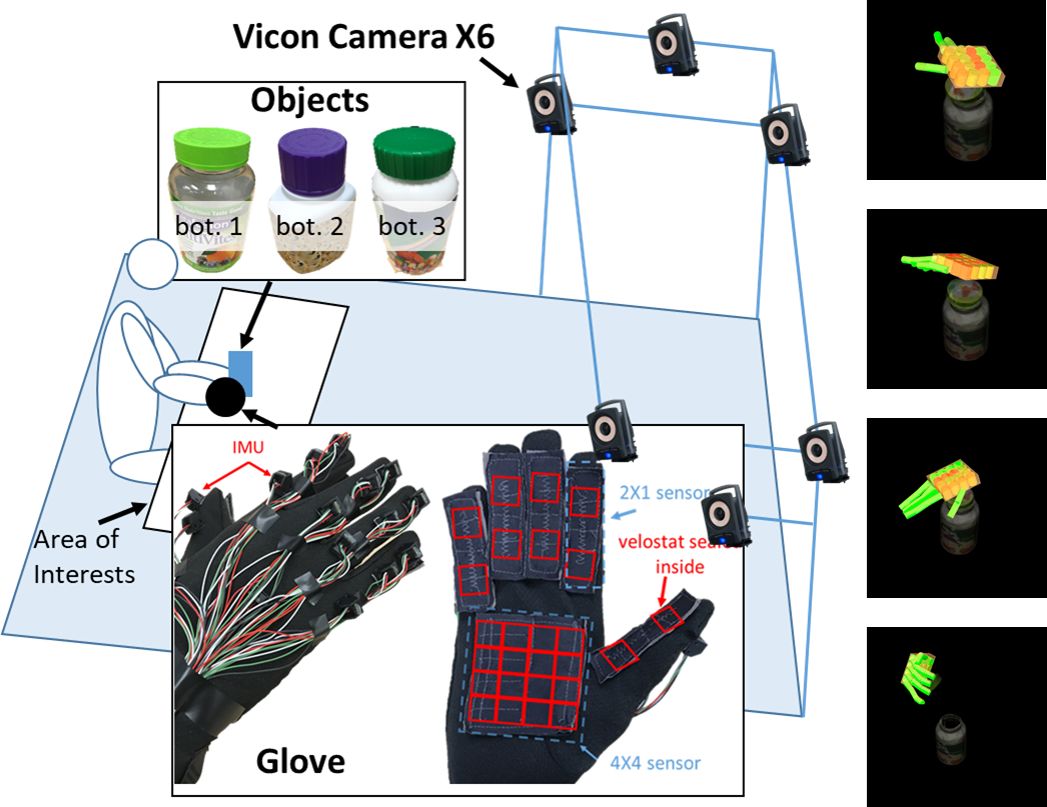
文章采用了双臂 7-DoF Baxter 机器人。整个系统在 ROS 上运行。收集手部姿势时使用开放式触觉手套和力数据,该手套配备有 i)15 个 IMU 的网络以测量各个趾骨之间的旋转,以及 ii)使用 Velostat(一种压阻材料)的 6 个定制力传感器来记录 每个趾骨上的两个区域(近端和远端)的力和手掌上的 4×4 区域。手腕和手腕部分(即瓶子和盖子)之间的相对姿势是从 Vicon 获得的。数据收集过程如下图所示。
在学习过程之后,在机器人上执行学习模型如下图所示让机器人完成打开药瓶的动作。首先从学习策略引起的 T-AoG 中对解析树进行采样,以获得机器人应该模仿的一系列力类型,以便引起对象状态的相对变化。然后,Baxter 机器人的执行从初始位置开始并顺序执行相应的基元。在下图中,a6 会产生由机器人手腕中的力传感器(左上)捕获的力,比较数据表明提出的镜像方法确实比 baseline 方法能成功打开瓶子。

分析师评论:研究针对以目标为主的动作学习,利用不同模态(力度,摄像头等)的传感器采集足够的数据,似乎达到不错的学习效果。另外利用层次的图 T-AOG 也能更好表示机器人的状态变化,达到更好的控制效果。比较其他机器学习和机器人结合的研究组(比如 [2.2])如今主要采用深度学习+强化学习,似乎有更好的可解释性。
Cognitive Deficit of Deep Learning in Numerosity
Xiaolin Wu, Xi Zhang, Xiao Shu
Link: https://arxiv.org/abs/1802.05160
第三篇论文跟深度学习的可解释性和认知学习有关。标题是「Cognitive Deficit of Deep Learning in Numerosity」,是来自上海交大和加拿大麦克马斯特大学的合作研究。
文章研究了是否能用当今的深度学习方法来模拟简单的人类认知活动「Subitizing「。Subitizing 中文没有固定的翻译,一般叫「数觉」或「数感「。详情可以参看「知乎日报」:https://daily.zhihu.com/story/4066465。简单来说,人除了有逐一数数的能力以外,也有一眼认出 5-6 以下物体数量的能力。而如今的深度学习虽然有与人相比拟,甚至超过人类的物体/脸孔辨识能力,但是能否也有与人类类似的「数觉」能力?本文也想探究更深次的深度学习:黑盒子的深度学习是否可以达到人类的抽象和推理水平,这种超出了一般(像素)的统计学学习能力。
DCNN(深度卷积网络)可以用来计算特定环境中特定类型的物体,例如街道上的行人或显微镜下的细胞。但是这些这些方法不能像人类一样在不同背景的不同对象之间进行推广。Subitizing 需要在像素中抽象出面或单元格个数的自然数字。和一般 CNN 的分类问题不同的是,要实现 Subitizing 的主要问题是抽象物体的个数(也和符号化有关),但与物体具体的形状、颜色等几何信息相关性不大。
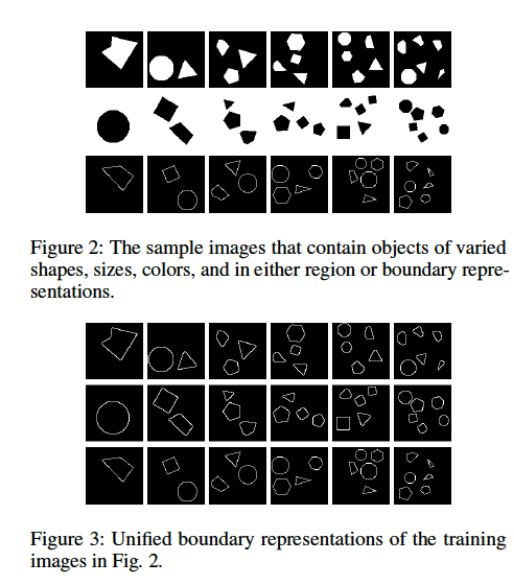
文章采用了如下的数据集进行训练。训练的图像都是合成和没有噪声干扰的。

在实验一,文章采用了最直接的方法,尝试在测试集改变图形的大小形状颜色等信息,由此测试 DCNN 模型是否具有大小形状颜色的泛化能力。文章在这里利用了下面的 DCNN 模型进行训练:

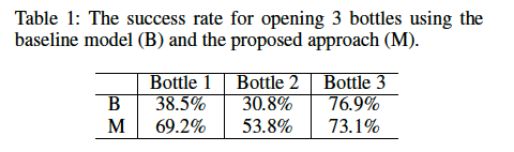
但结果不太令人满意,除了在第一个测试里,网络可以分辨出按比例扩大的图形,其他实验(包括改变形状,改变颜色,把训练图像改变成环状等),基本网络不能完成 Numerosity 的任务。(下面是部分实验结果,包括改变颜色,测试集图像是训练图像的环状版本)。由此看来,当图像在空间域里面的概率分布改变了,在 DCNN 里基本很难辨识出来。
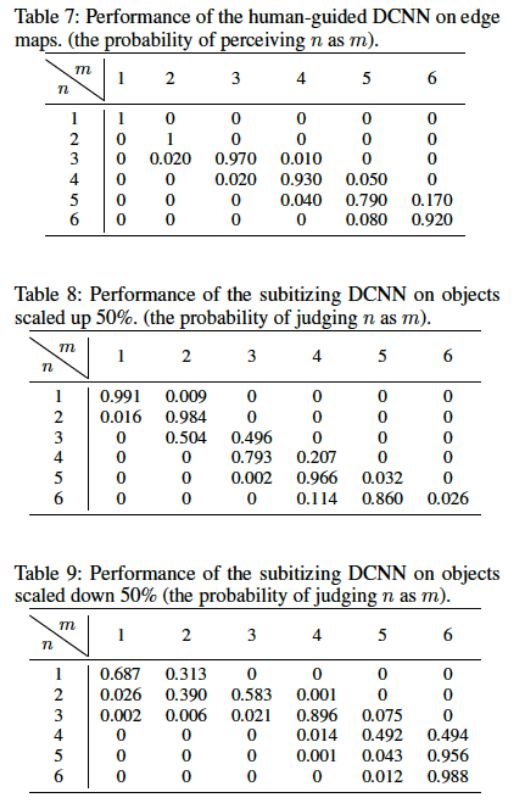
在第二个实验中,作者尝试把上述的几何信息归一化, 只把所有的图像边缘用来训练和测试:
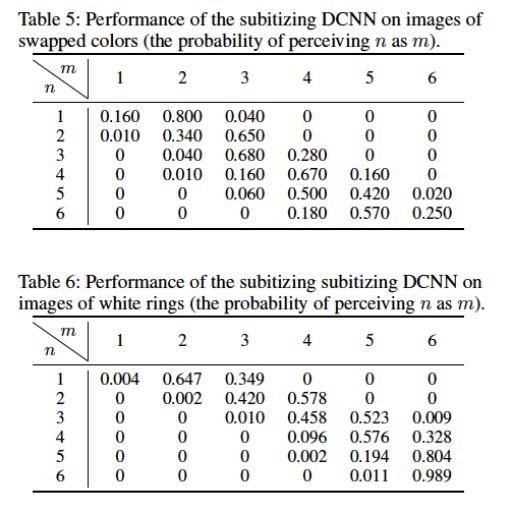
比起第一个实验,网络学习归一化(也就是经过边缘检测)的图像达到较好效果(如下图所示)。但识别率还没达到人的 Subitizing 标准。
在第三个实验里,文章继续对图形进行计算机视觉的形态学预处理。以下几个预定义的核卷积算子,以此来提取相关的拓扑信息,而不是直接用原始图像来进行 DCNN 处理。但作者经过尝试发现,这些核卷积算子只能预定义,而不能通过一般的反向传播学习来达到收敛。

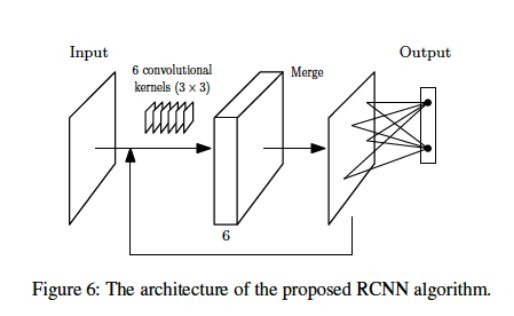
分析师评论:这篇文章建立了简单的连接模型 (connectionist),和改变训练和测试集性质等办法做了初步的深度学习和认知学关系的测试。作者认为, 如今流行的 DCNN 方法 (或者只凭借深度学习) 并不能实现 Subitizing 等简单的人类认知功能。而通过添加预定义的卷积算子,效果会提高。这是否意味着要某些提取物体基本的拓扑学信息,而这些计算要在人脑中内置(innate)呢?另外除了 Subitizing,和人的手势相关的数数(counting) 的连接学模型研究,可以参考 [3.1][3.2]。

参考文献:
[1.1] Fürnkranz, Johannes. "Separate-and-conquer rule learning." Artificial Intelligence Review 13.1 (1999): 3-54.
[1.2] Boström, Henrik, and Lars Asker. "Combining divide-and-conquer and separate-and-conquer for efficient and effective rule induction." International Conference on Inductive Logic Programming. Springer, Berlin, Heidelberg, 1999.
[2.1] http://kybele.psych.cornell.edu/ADIOS/
[2.2] Levine, Sergey, et al. "Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection." The International Journal of Robotics Research 37.4-5 (2018): 421-436.
[3.1] De La Cruz, Vivian Milagros, et al. "Making fingers and words count in a cognitive robot." Frontiers in behavioral neuroscience 8 (2014): 13.
[3.2] Rucinski, Marek, Angelo Cangelosi, and Tony Belpaeme. "Robotic model of the contribution of gesture to learning to count." Development and Learning and Epigenetic Robotics (ICDL), 2012 IEEE International Conference on. IEEE, 2012.
本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



