扩散模型背后数学太难了,啃不动?谷歌用统一视角讲明白了
机器之心报道
扩散模型背后的数学可是难倒了一批人。


-
潜在维度完全等同于数据维度; -
每个时间步上潜在编码器的结构没有被学到,它被预定义为线性高斯模型。换言之,它是以之前时间步的输出为中心的高斯分布; -
潜在编码器的高斯参数随时间变化,过程中最终时间步 T 的潜在分布标是准高斯分布。
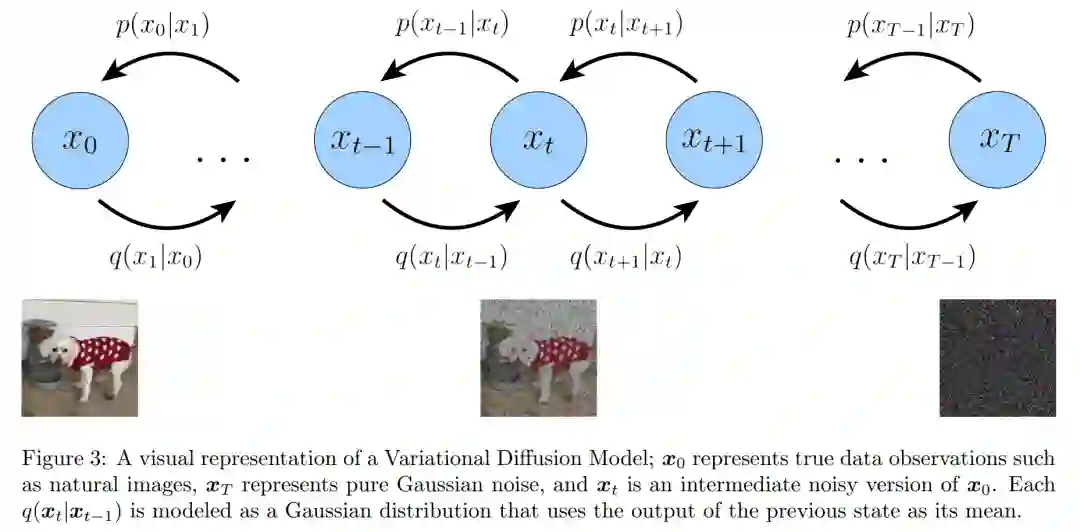

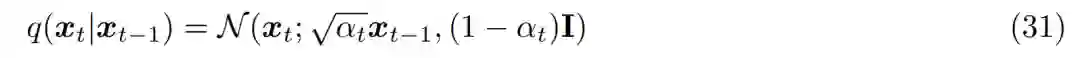
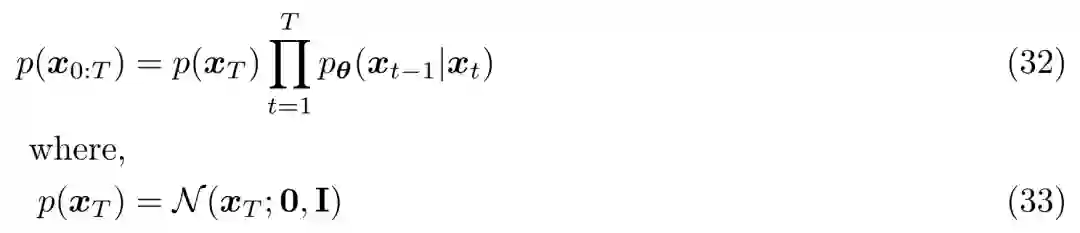

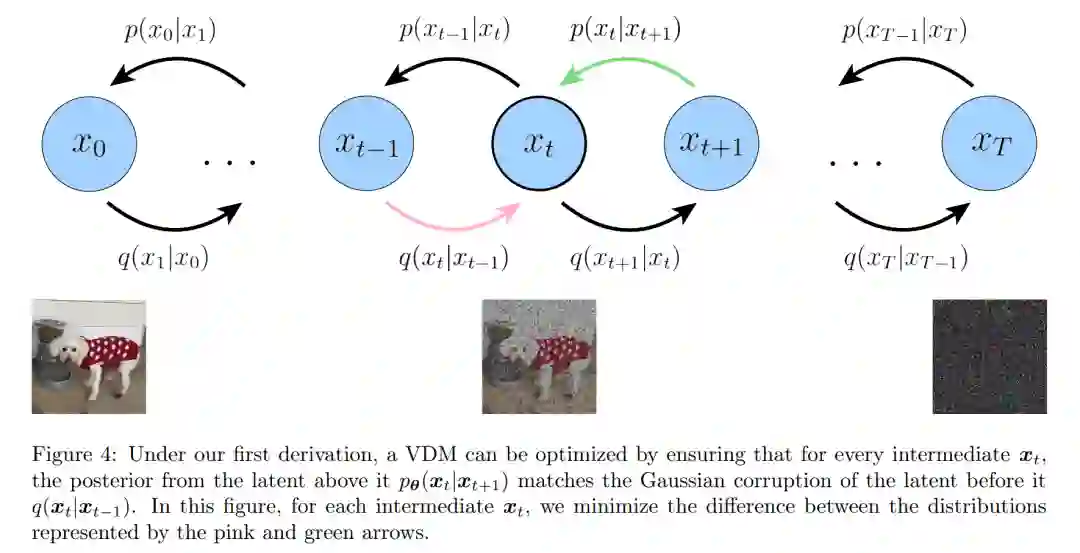

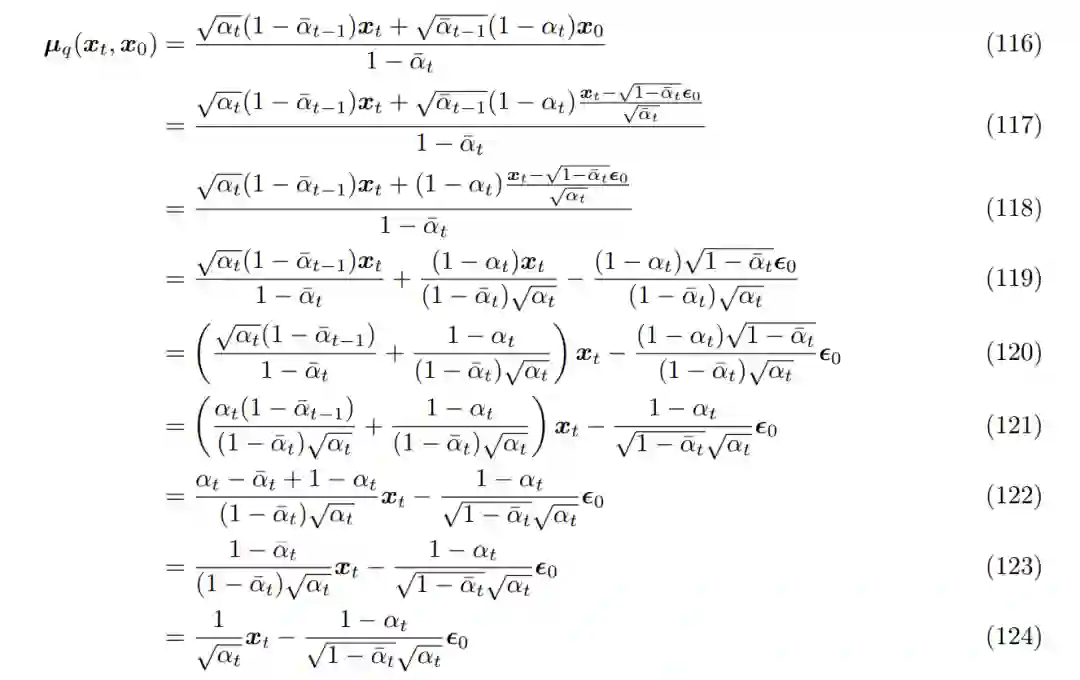

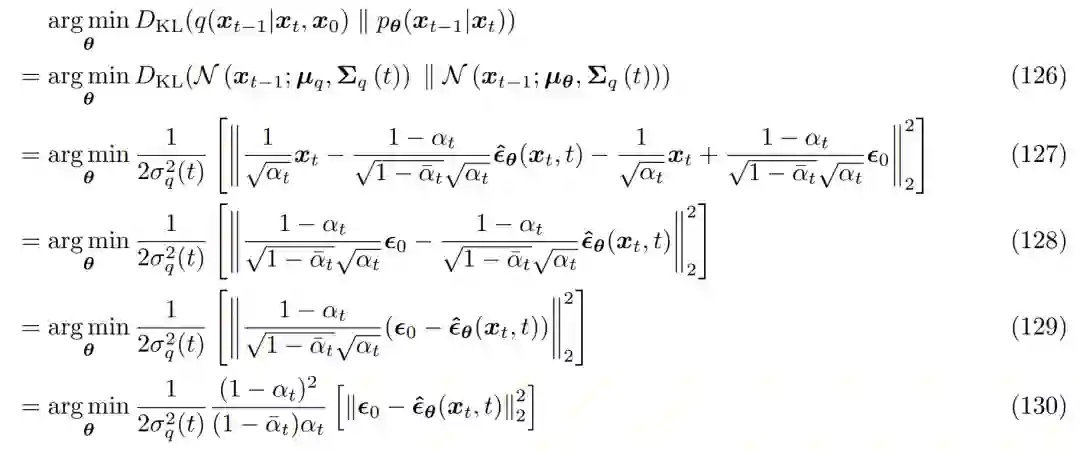


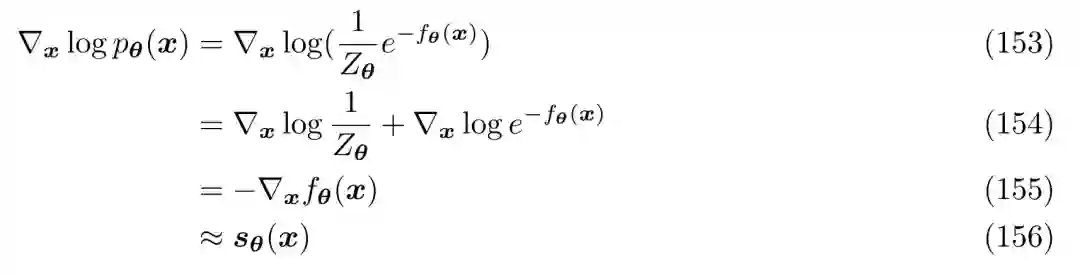



登录查看更多
相关内容

Arxiv
0+阅读 · 2022年11月22日
Arxiv
72+阅读 · 2022年11月15日




相关VIP内容
相关资讯