同济大学用深度强化学习算法训练了一个“股票交易智能体”,年化收益率近达65%
深度强化学习实验室
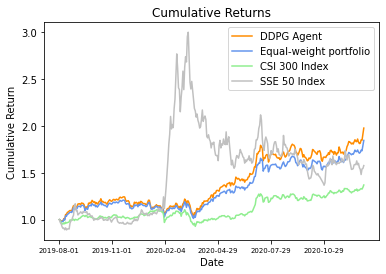
利用算法进行股票量化交易是当今金融市场的一个重要趋势。在国际象棋和围棋等诸多复杂的游戏中,深度强化学习(DRL)智能体都取得了惊人的成绩。深度强化学习的理论同样适用于股票市场的量化决策。本文介绍了同济大学计算机科学与技术系的上海市大学生创新创业训练计划优秀项目:「基于深度强化学习的金融量化策略研究」,解读了如何训练一个 A 股市场的深度强化学习模型,以及回测的绩效表现。
状态 s = [p, h, b],其中 p, h 均为 D 维向量,分别代表股票价格和持股量,b 为当前余额(D 为在市场上考虑的股票数量)。
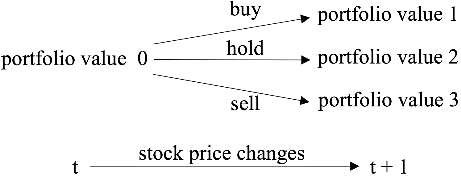
动作 a: D 维向量,代表对股票的操作。每只股票的可操作行为包括卖出、买入和持有,分别导致持股量 h 的减少、增加和不变。
奖励
:代表在状态 s 时执行动作 a 后达到新的状态
投资组合价值的变化。投资组合价值是所有持有的股票价值
和余额 b 的总和。
策略
: 代表股票在状态 s 的交易策略,它本质上是动作 a 在状态 s 的概率分布。
状态动作价值函数
: 代表在状态 s 执行动作 a,并在后续状态以策略进行交易所能获得的期望收益。
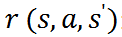
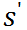
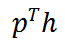

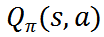
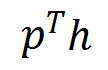 和
余额 b 的总和,即可得到 t+1 时刻新的投资组合价值。
和
余额 b 的总和,即可得到 t+1 时刻新的投资组合价值。
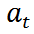 ,并根据下一状态
,并根据下一状态
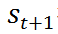 得到奖励,由此得到经验四元组
得到奖励,由此得到经验四元组
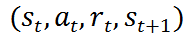 并存入 R 中。
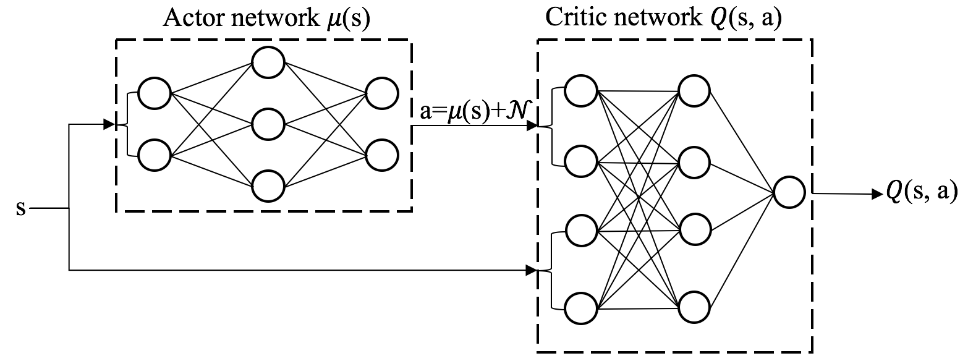
随后,从 R 中随机抽出 N 条经验,计算 TD target 并更新价值网络参数,从而使得价值网络对状态动作价值函数
并存入 R 中。
随后,从 R 中随机抽出 N 条经验,计算 TD target 并更新价值网络参数,从而使得价值网络对状态动作价值函数
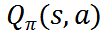 的估计更准确。
然后根据价值网络计算策略梯度并更新策略网络的参数。
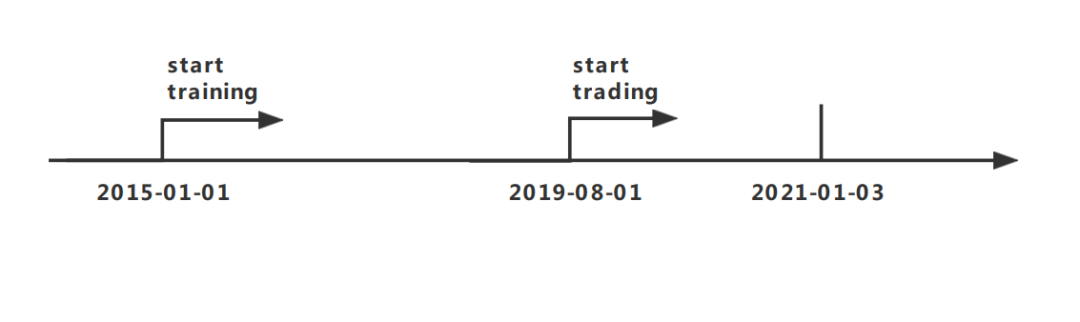
下图对算法的细节做了详细的说明。
的估计更准确。
然后根据价值网络计算策略梯度并更新策略网络的参数。
下图对算法的细节做了详细的说明。


登录查看更多
相关内容

Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月19日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月19日