【团队新作】深度强化学习进展: 从AlphaGo到AlphaGo Zero

【今日聚焦】
2016年初, AlphaGo战胜李世石成为人工智能的里程碑事件. 其核心技术深度强化学习受到人们的广泛关注和研究, 取得了丰硕的理论和应用成果. 并进一步研发出算法形式更为简洁的AlphaGo Zero, 其采用完全不基于人类经验的自学习算法, 完胜AlphaGo, 再一次刷新人们对深度强化学习的认知. 深度强化学习结合了深度学习和强化学习的优势, 可以在复杂高维的状态动作空间中进行端到端的感知决策.


深度学习起源于人工神经网络. 早期研究人员提出了多层感知机的概念, 并且使用反向传播算法优化多层神经网络, 但是由于受到梯度弥散或爆炸问题的困扰和硬件资源的限制, 神经网络的研究一直没有取得突破性进展. 最近几年, 随着计算资源的性能提升和相应算法的发展, 深度学习在人工智能领域取得了一系列重大突破, 包括图像识别、语音识别、自然语言处理等.

来自网络
强化学习是机器学习中的一个重要研究领域, 它以试错的机制与环境进行交互, 通过最大化累积奖赏来学习最优策略。强化学习不需要监督信号,可以在模型未知的环境中平衡探索和利用, 其主要算法有蒙特卡罗强化学习, 时间差分(temporal difference:TD)学习, 策略梯度等。深度学习具有较强的感知能力, 但是缺乏一定的决策能力; 而强化学习具有较强的决策能力, 但对感知问题束手无策. 因此, 将两者结合起来, 优势互补, 能够为复杂状态下的感知决策问题提供解决思路。
1.深度Q网络及其扩展
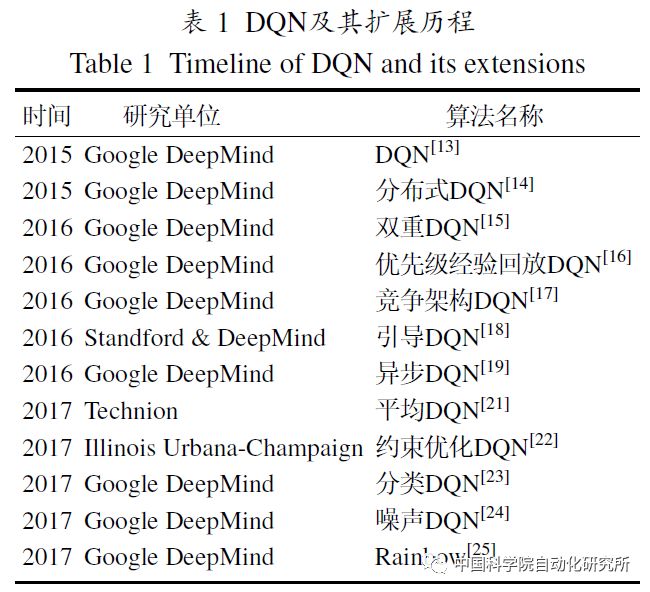
2015年, Google DeepMind团队提出了深度Q网络(deep Q network, DQN), DQN创新性地将卷积神经网络和Q学习结合到一起, 通过经验回放技术和固定目标Q网络, 使神经网络非线性动作值函数逼近器带来的不稳定性和发散性问题得到有效处理, 极大提升了强化学习方法的适用性. 经验回放增加了历史数据的利用效率, 同时随机采样打破了数据间的相关性, 与目标Q网络的结合进一步稳定了动作值函数的训练过程. 此外, 通过截断奖赏和正则化网络参数, 梯度被限制到合适的范围内, 从而使训练过程更加鲁棒。
此后, 研究人员又陆续提出了一些DQN的重要扩展, 进一步完善DQN 算法. 彩虹(Rainbow)将各类DQN的算法优势集成在一体, 取得目前最优的算法性能, 视为DQN算法的集大成者.
2.A3C及其扩展
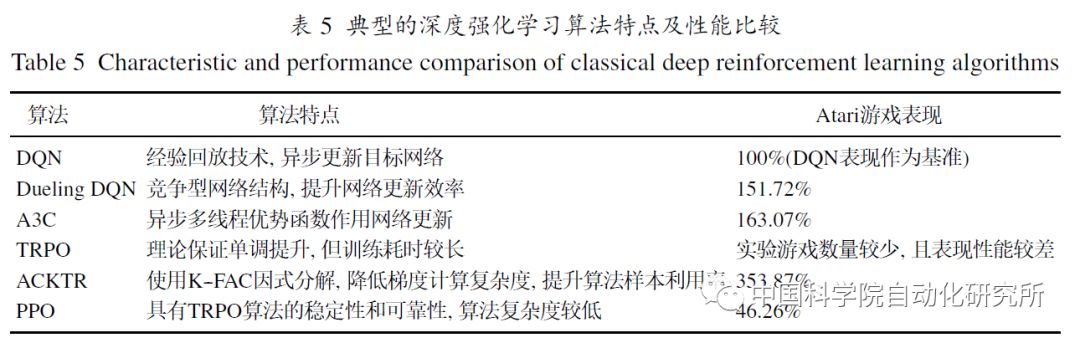
深度强化学习领域另一个重要算法是异步优势actor-critic (asynchronous advantage actor-critic, A3C)。A3C 采用了actor-critic(AC)这一强化学习算法.相比DQN 算法, A3C 算法不需要使用经验池存储历史样本, 节省存储空间, 并通过提高数据的采样效率, 以此提升训练速度. 与此同时, 采用多个不同训练环境采集样本,使样本的分布也更加均匀, 更有利于神经网络的训练.A3C算法在以上多个环节上做出了改进, 使得其在Atari游戏上的平均成绩是DQN算法的4倍.A3C算法由于其优秀的性能, 很快成为了深度强化学习领域新的基准算法.

3.策略梯度深度强化学习及其扩展
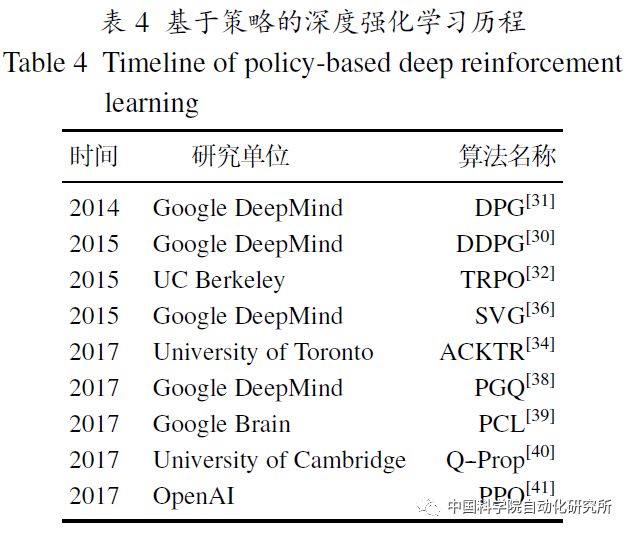
基于值函数的深度强化学习主要应用于离散动作空间的任务. 面对连续动作空间的任务,基于策略梯度的深度强化学习算法能获得更好的决策效果.Lillicrap等提出的深度确定性策略梯度算法(deep deterministic policy gradient, DDPG),以确定性策略梯度算法(deterministic policy gradient, DPG)为基础, 将DQN算法在离散控制任务上的成功经验应用到连续控制任务的研究。DDPG是无模型、离策略(off-policy)actor-critic算法, 使用深度神经网络作为逼近器, 将深度学习和确定性策略梯度算法有效地结合在一起. Schulman等提出可信域策略优化(trust region policy optimization, TRPO)处理随机策略的训练过程, 保证策略优化过程稳定提升, 同时证明了期望奖赏呈单调性增长.
4.深度强化学习算法小结
除了上述深度强化学习算法, 还有深度迁移强化学习、分层深度强化学习、深度记忆强化学习以及多智能体深度强化学习等算法.综合来看,基于值函数概念的DQN及其相应的扩展算法在离散状态、离散动作的控制任务中已经表现了卓越的性能, 但是受限于值函数离散型输出的影响, 在连续型控制任务上显得捉襟见肘.基于策略梯度概念的,以DDPG, TRPO等为代表的策略型深度强化学习算法则更适用于处理基于连续状态空间的连续动作的控制输出任务, 并且算法在稳定性和可靠性上具有一定的理论保证, 理论完备性较强. 采用actor-critic架构的A3C算法及其扩展算法, 相比于传统DQN算法, 这类算法的数据利用效率更高, 学习速率更快, 通用性、可扩展应用性更强, 达到的表现性能更优, 但算法的稳定性无法得到保证. 而其他的如深度迁移强化学习、分层深度强化学习、深度记忆强化学习和多智能体深度强化学习等算法都是现在的研究热点, 通过这些算法能应对更为复杂的场景问题、系统环境及控制任务, 是目前深度强化学习算法研究的前沿领域.
人工智能领域一个里程碑式的工作是由Google DeepMind 在2016 年初发表于《Nature》上的围棋AI:AlphaGo.它创新性地结合深度强化学习和蒙特卡罗树搜索, 通过策略网络选择落子位置降低搜索宽度, 使用价值网络评估局面以减小搜索深度, 使搜索效率得到了大幅提升, 胜率估算也更加精确.与此同时, AlphaGo使用强化学习的自我博弈来对策略网络进行调整, 改善策略网络的性能, 使用自我对弈和快速走子结合形成的棋谱数据进一步训练价值网络. 最终在线对弈时,结合策略网络和价值网络的蒙特卡罗树搜索在当前局面下选择最终的落子位置.AlphaGo成功地整合了上述算法, 并依托强大的硬件支持达到了顶尖棋手的水平。

来自网络
在AlphaGo的基础上, DeepMind进一步提出了AlphaGo Zero。AlphaGo Zero棋力提升的关键因素可以归结为两点, 一是使用基于残差模块构成的深度神经网络, 不需要人工制定特征, 通过原始棋盘信息便可提取相关表示特征; 二是使用新的神经网络构造启发式搜索函数, 优化蒙特卡罗树搜索算法, 使用神经网络估值函数替换快速走子过程,使算法训练学习和执行走子所需要的时间大幅减少。
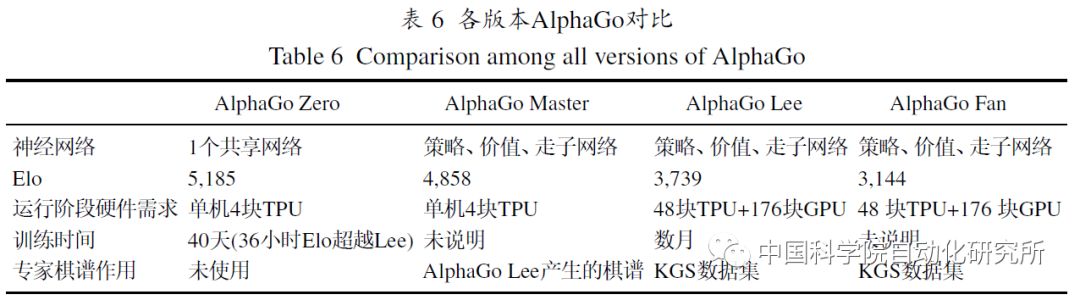
AlphaGo Zero的成功证明了在没有人类经验指导的前提下, 深度强化学习算法仍然能在围棋领域出色地完成这项复杂任务, 甚至比有人类经验知识指导时, 达到更高的水平. 在围棋下法上, AlphaGo Zero比此前的版本创造出了更多前所未见的下棋方式, 为人类对围棋领域的认知打开了新的篇章. 就某种程度而言, AlphaGo Zero展现了机器“机智过人”的一面. 从以下几个方面对 AlphaGo 和 AlphaGo Zero进行比较.
1) 局部最优与全局最优.
虽然AlphaGo和AlphaGo Zero都以深度学习作 为核心算法, 但是核心神经网络的初始化方式却不 同. AlphaGo是基于人类专家棋谱使用监督学习进 行训练, 虽然算法的收敛速度较快, 但易于陷入局 部最优. AlphaGo Zero则没有使用先验知识和专家 数据, 避开了噪声数据的影响, 直接基于强化学习 以逐步逼近至全局最优解. 最终AlphaGo Zero的围 棋水平要远高于AlphaGo.
2) 大数据与深度学习的关系.
……
3) 强化学习算法的收敛性.
……
4) 算法的“加法”和“减法”.
……
AlphaGo的出现使深度强化学习在游戏、机器人、自然语言处理、智能驾驶和智能医疗等诸多领域得到了更加广泛的应用推广。相信AlphaGo Zero的成功会进一步促进以深度强化学习为基础的其他人工智能领域的发展。
DeepMind又提出了同时适用于国际象棋和日本将棋的通用AI: Alpha Zero, 其使用5000块I代TPU和64块II代TPU完成自我对弈数据的产生和神经网络的训练, 用了不到2个小时就击败了日本将棋的最强程序Elmo, 用了4个小时打败了国际象棋最强程序Stockfish, 仅用了8个小时就超过了AlphaGo Lee的对弈水平. 深度强化学习算法的贡献不言而喻, 但不能忽视算法背后所需要的强大算力资源. 要想更快提升算法的训练效率, 不能一味依靠硬件资源的支撑, 更需要对数据的利用训练效率展开更加深入细致的研究, 才能更有效地推进实际应用. 另, 深度强化学习的训练稳定性提升的理论保证和算法探索,基于多智能体协作的深度强化学习算法等,都将成为未来的研究热点.

来自网络
AlphaGo之父David Silver认为, 监督学习能产生当时性能最优的模型, 而强化学习却可以超越人类已有的知识得到更进一步的提升. 只使用监督学习算法确实可以达到令人惊叹的表现, 但是强化学习算法才是超越人类水平的关键. AlphaGo Zero的成功有力的证明了强化学习实现从无到有的强大学习能力, 但是这并不意味着通用人工智能领域问题得到了解决. AlphaGo Zero的出现只是证明在围棋这类特定应用环境的成功, 但要将这样的成功经验扩展到通用领域, 仍尚需时日, 因而通用人工智能问题的研究及解决仍然任重道远.
从文中统计的深度强化学习进展来看, 近两年的主要工作是由 Google DeepMind, Facebook, OpenAI等公司、以及一些国外名校也紧随其后. 这方面的研究仍然受到设备、数据、人才、资金等方面的制约, 国内好的成果仍然非常有限. 正如在第1篇综述中提到的, 深度强化学习的先进基础理论算法、广泛的日常生活应用、以及潜在的军事领域扩展, 正在加大我们与国外的差距. 2017年初, 中国工程院院刊提出了“人工智能2.0”的发展规划, 并引起国家层面的关注和重视, 希望藉此可以大力发展以深度强化学习为基础的人工智能理论、算法和应用的研究.

更多详细信息
深度强化学习进展: 从AlphaGo到AlphaGo Zero
唐振韬, 邵坤, 赵冬斌, 朱圆恒
《控制理论与应用》, vol. 34, no. 12, pp.1529-1546, 2017.
原文下载网址:
http://jcta.alljournals.ac.cn/cta_cn/ch/index.aspx

更多精彩内容,欢迎关注
中科院自动化所官方网站:
http://www.ia.ac.cn
欢迎后台留言、推荐您感兴趣的话题、内容或资讯,小编恭候您的意见和建议!如需转载或投稿,请后台私信。
来源:控制理论与应用
编辑:欧梨成


中科院自动化研究所
微信:casia1956
欢迎搭乘自动化所AI旗舰号!
点击“阅读原文”,下载完整论文



