利用算法进行股票量化交易是当今金融市场的一个重要趋势。在国际象棋和围棋等诸多复杂的游戏中,深度强化学习(DRL)智能体都取得了惊人的成绩。深度强化学习的理论同样适用于股票市场的量化决策。本文介绍了同济大学计算机科学与技术系的上海市大学生创新创业训练计划优秀项目:「基于深度强化学习的金融量化策略研究」,解读了如何训练一个 A 股市场的深度强化学习模型,以及回测的绩效表现。
在该项目中,
研究者把股票市场的历史价格走势看作一个复杂的不完全信息环境,而智能体需要在这个环境中最大化回报和最小化风险
。相比于其他传统机器学习算法,深度强化学习的优势在于对股票交易任务进行马尔可夫决策过程建模,没有将识别市场状况和交易策略执行分开,更符合股票交易的特点。尽管基于深度强化学习的量化策略研究仍处于早期探索阶段,部分算法已经能够在特定的交易任务中展现出良好的收益。
实验表明,深度强化学习算法中 DDPG(Deep Deterministic Policy Gradient)算法已能在复杂多变的股票市场取得良好的效果。
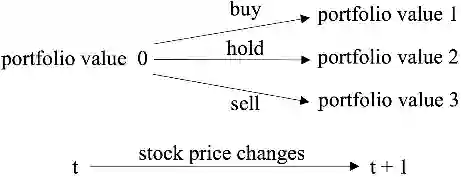
考虑到交易市场的随机性和互动性,研究者将股票交易过程建模为如下图所示的马尔可夫决策过程(Markov Decision process, MDP),具体如下:
状态 s = [p, h, b],其中 p, h 均为 D 维向量,分别代表股票价格和持股量,b 为当前余额(D 为在市场上考虑的股票数量)。
动作 a: D 维向量,代表对股票的操作。每只股票的可操作行为包括卖出、买入和持有,分别导致持股量 h 的减少、增加和不变。
奖励![]() :代表在状态 s 时执行动作 a 后达到新的状态
:代表在状态 s 时执行动作 a 后达到新的状态![]() 投资组合价值的变化。投资组合价值是所有持有的股票价值
投资组合价值的变化。投资组合价值是所有持有的股票价值![]() 和余额 b 的总和。
和余额 b 的总和。
策略![]() : 代表股票在状态 s 的交易策略,它本质上是动作 a 在状态 s 的概率分布。
: 代表股票在状态 s 的交易策略,它本质上是动作 a 在状态 s 的概率分布。
状态动作价值函数![]() : 代表在状态 s 执行动作 a,并在后续状态以策略进行交易所能获得的期望收益。
: 代表在状态 s 执行动作 a,并在后续状态以策略进行交易所能获得的期望收益。
![]()
股票市场的动态变化如下:在 t 时刻,智能体执行一个动作 a,可以是卖出、买入和持有,分别导致持股量 h 的减少、增加和不变。而后根据持股量、余额的变化和股票价格的更新,重新计算股票价值
![]() 和
余额 b 的总和,即可得到 t+1 时刻新的投资组合价值。
和
余额 b 的总和,即可得到 t+1 时刻新的投资组合价值。
DDPG 是确定性策略梯度 (Deterministic Policy Gradient, DPG) 算法的改进版本
。DPG 结合了 Q-learning 和策略梯度这两种方法。与 DPG 相比,DDPG 采用神经网络作为函数逼近器。
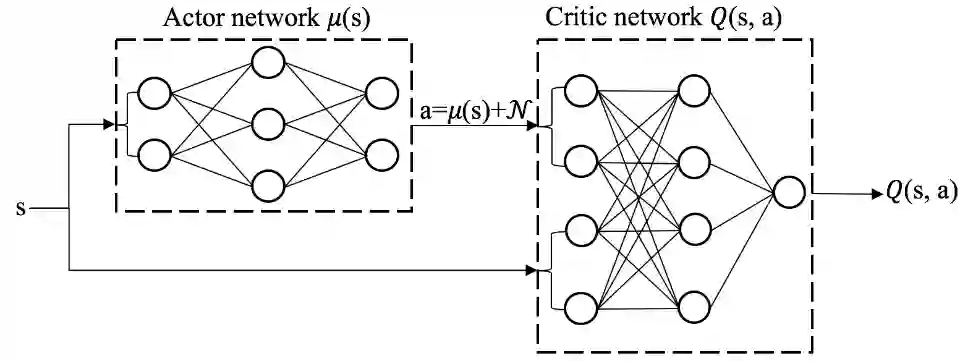
如下图所示,DDPG 采用 Actor-Critic 方法,它有一个策略网络(Actor),一个价值网络(Critic)。策略网络控制智能体的行动,它基于状态 s 做出动作 a。价值网络不控制智能体,只是基于状态 s 给动作 a 打分,从而指导策略网络做出改进。
![]()
与 DQN 类似,DDPG 使用经验回放缓冲区(experience replay buffer) R 来存储收集到的经验和更新模型参数,可以有效降低采样样本之间的相关性。为了收集经验,每个时刻,DDPG 智能体在状态下采取动作
![]() ,并根据下一状态
,并根据下一状态
![]() 得到奖励,由此得到经验四元组
得到奖励,由此得到经验四元组
![]() 并存入 R 中。
随后,从 R 中随机抽出 N 条经验,计算 TD target 并更新价值网络参数,从而使得价值网络对状态动作价值函数
并存入 R 中。
随后,从 R 中随机抽出 N 条经验,计算 TD target 并更新价值网络参数,从而使得价值网络对状态动作价值函数
![]() 的估计更准确。
然后根据价值网络计算策略梯度并更新策略网络的参数。
下图对算法的细节做了详细的说明。
的估计更准确。
然后根据价值网络计算策略梯度并更新策略网络的参数。
下图对算法的细节做了详细的说明。
![]()
FinRL 是第一个展现出深度强化学习应用在量化金融中巨大潜力的 Python 开源框架
。FinRL 提供了通用的构建模块,使策略制定者能够(1)将股票市场数据集配置为虚拟环境(2)训练深度神经网络作为智能体(3)通过回测分析智能体的交易表现。
首先,下载、安装并导入相关功能包,并通过 TushareDownloader 下载股票市场数据集。然后进行数据预处理,主要是根据原始股票数据计算各种金融技术性指标,这一步可以使用 FinRL 提供的 FeatureEngineer 类。
之后便是强化学习环境的定义,包括数据集的划分、状态空间大小的计算以及初始金额、交易成本等环境参数的设定。这一步会分别定义训练和交易两个环境,需要使用 FinRL 提供的 StockTradingEnv 类。
环境搭建完成后,用搭建好的环境初始化 DRLAgent 类,得到一个智能体实例,并根据需要赋予智能体实例深度强化学习算法。目前 FinRL 框架中包含了 DDPG、A2C、PPO 等绝大多数主流深度强化学习算法,同时也支持自定义算法。随后设定学习率等与模型训练相关的超参数,即可在训练环境中开始训练。
最后,让训练好的 DRLAgent 在交易环境中交易,得到各时间步下的投资组合价值和智能体的动作,再应用 FinRL 中集成的 pyfolio 自动化回测工具就能得到年化收益率、夏普指数等一系列回测指标的数值和曲线图。
同济大学的本科生团队正致力于基于深度强化学习的量化金融策略研究,并已经使用 DDPG 算法在我国 A 股的历史数据上取得了不错的效果。实验代码已在 FinRL-Meta 开源。
项目地址:https://github.com/AI4Finance-Foundation/FinRL-Meta/blob/master/Demo_China_A_share_market.ipynb
![]()
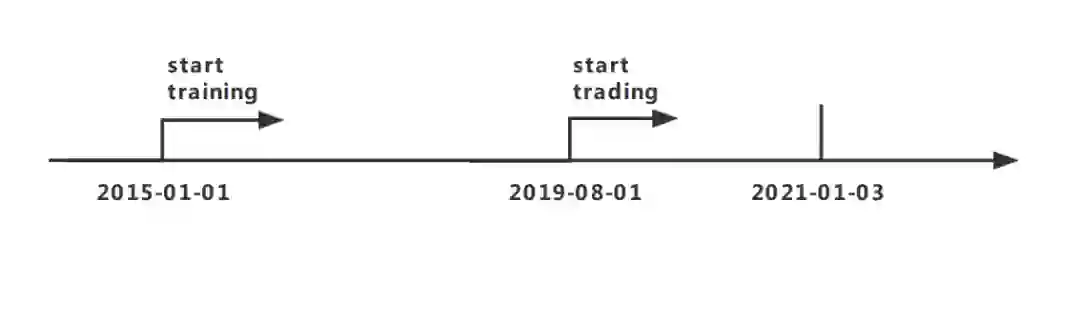
该研究选择了上证 50 中的 15 支作为交易股票,并使用 2015 年 1 月 1 日至 2021 年 1 月 3 日的历史日价格来训练智能体并测试其表现
。数据集通过开源的 Python 财经数据接口包 Tushare 获得。
实验包括三个阶段,即训练、验证和交易。在训练阶段,首先使用 DDPG 算法生成一个训练有素的交易智能体。然后在验证阶段调整关键参数,如 learning rate 和 episode 的大小等。最后在交易阶段,对训练得到的智能体的盈利能力进行评估。因此,整个数据集被分为两个部分,如下图所示。训练使用 2015 年 1 月 1 日至 2019 年 8 月 1 日的数据,测试使用 2019 年 8 月 1 日至 2021 年 1 月 3 日的数据。
![]()
该研究使用三个指标来评估得到的结果: 最终投资组合价值、年化收益率和夏普比率
。最终投资组合价值反映的是交易阶段结束时的投资组合价值。年化收益率是指投资组合每年的直接收益。夏普比率将收益和风险结合在一起给出的评价。
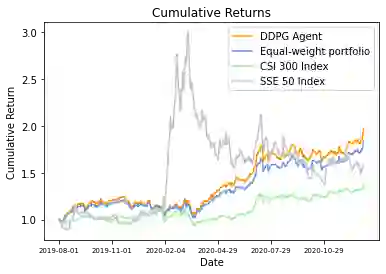
结果显示,
智能体在初始资金为 1000000 时,经过一年半的交易,最终投资组合价值为 1978179,年化收益率为 64.35%,夏普比率达 1.99
。下图为累积收益率随时间变化的曲线。
![]()
[1] Deep Reinforcement Learning in Quantitative Algorithmic Trading: A Review:https://arxiv.org/abs/2106.00123
[2] Practical Deep Reinforcement Learning Approach for Stock Trading:https://arxiv.org/pdf/1811.07522.pdf
使用Python快速构建基于NVIDIA RIVA的智能问答机器人
NVIDIA Riva 是一个使用 GPU 加速,能用于快速部署高性能会话式 AI 服务的 SDK,可用于快速开发语音 AI 的应用程序。Riva 的设计旨在轻松、快速地访问会话 AI 功能,开箱即用,通过一些简单的命令和 API 操作就可以快速构建高级别的对话式 AI 服务。
2022年1月26日19:30-21:00,最新一期线上分享主要介绍:
对话式 AI 与 NVIDIA Riva 简介
利用NVIDIA Riva构建语音识别模块
利用NVIDIA Riva构建智能问答模块
利用NVIDIA Riva构建语音合成模块
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
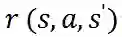
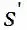
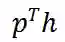
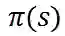
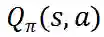
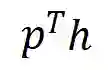 和
余额 b 的总和,即可得到 t+1 时刻新的投资组合价值。
和
余额 b 的总和,即可得到 t+1 时刻新的投资组合价值。
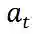 ,并根据下一状态
,并根据下一状态
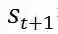 得到奖励,由此得到经验四元组
得到奖励,由此得到经验四元组
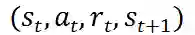 并存入 R 中。
随后,从 R 中随机抽出 N 条经验,计算 TD target 并更新价值网络参数,从而使得价值网络对状态动作价值函数
并存入 R 中。
随后,从 R 中随机抽出 N 条经验,计算 TD target 并更新价值网络参数,从而使得价值网络对状态动作价值函数
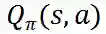 的估计更准确。
然后根据价值网络计算策略梯度并更新策略网络的参数。
下图对算法的细节做了详细的说明。
的估计更准确。
然后根据价值网络计算策略梯度并更新策略网络的参数。
下图对算法的细节做了详细的说明。