统计挖掘那些事(八)—— 分层抽样与交叉验证


浩彬老撕,R语言中文社区特邀作者,好玩的IBM数据工程师,立志做数据科学界的段子手。
个人公众号:探数寻理
往期回顾:
统计挖掘那些事(四)-9个相关R先生的故事(理论+动手案例)

1留出法(Hold out)与分层抽样
留出法就是咱们在上期文章介绍的进行对训练集和测试集进行的划分方法。
上期内容:如何直观地理解过拟合与欠拟合那些事~
留出法的意思就是直接将总数据D划分为两个对立集合,训练集S以及测试集T,我们有S+T=D,以及S交T等于空集;
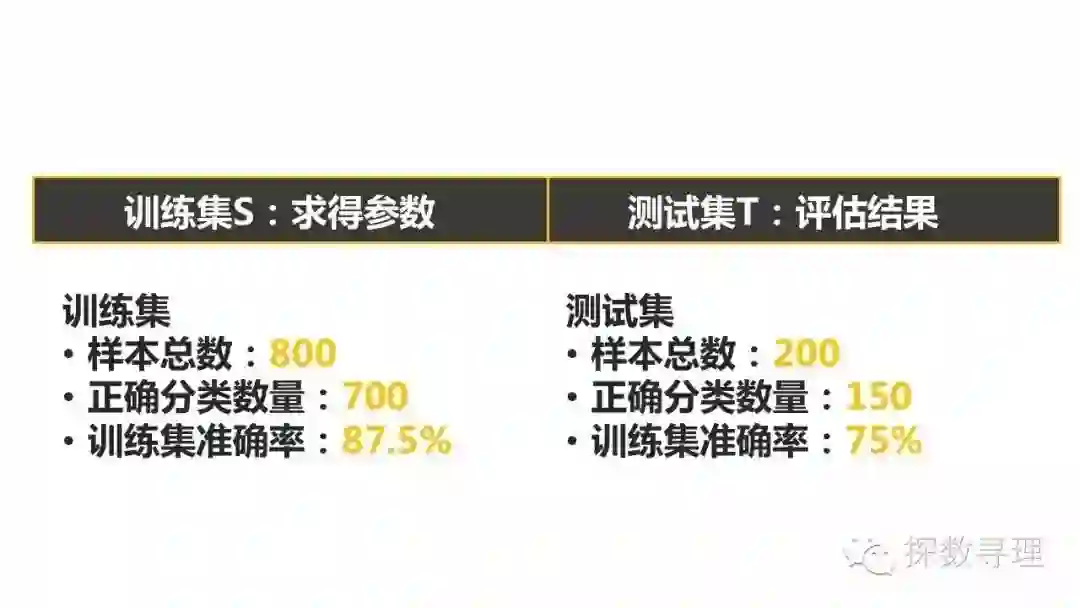
举个简单例子说明,例如我们在研究客户流失,在集合D中我们有1000个样本,我们利用随机抽样的方法从中抽取800个样本作为训练集,剩下的200个作为测试集。
划分出集合后,我们就可以在训练集S上进行模型训练,再在测试集T上评估结果。假如在训练集中,我们有700个样本被正确分类,那么分类的正确率就有700/800*100%=87.5%,而在测试集中,假如我们只有150个样本被正确分类,那么分类的正确率绩优150/200*100%=75%.
但实际上,这样的做法是存在一定的问题的。由于我们采取的是完全随机抽样的方法,这就可能会由于抽样划分的问题而改变了原有的数据分布。
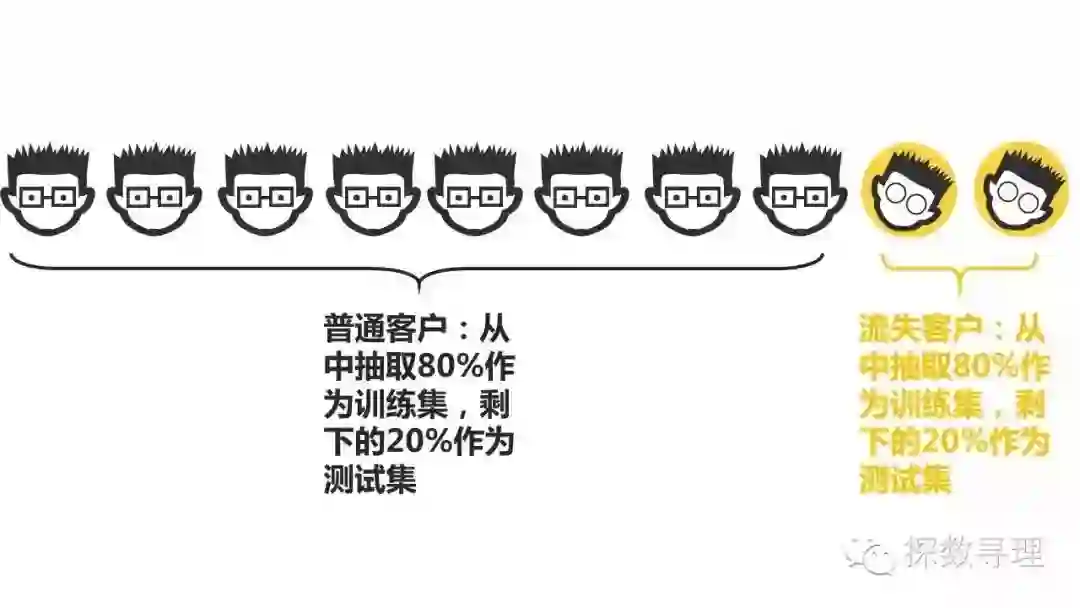
例如在上述1000个样本中,其中有200名客户被标记为流失,800名客户被标记为普通客户。
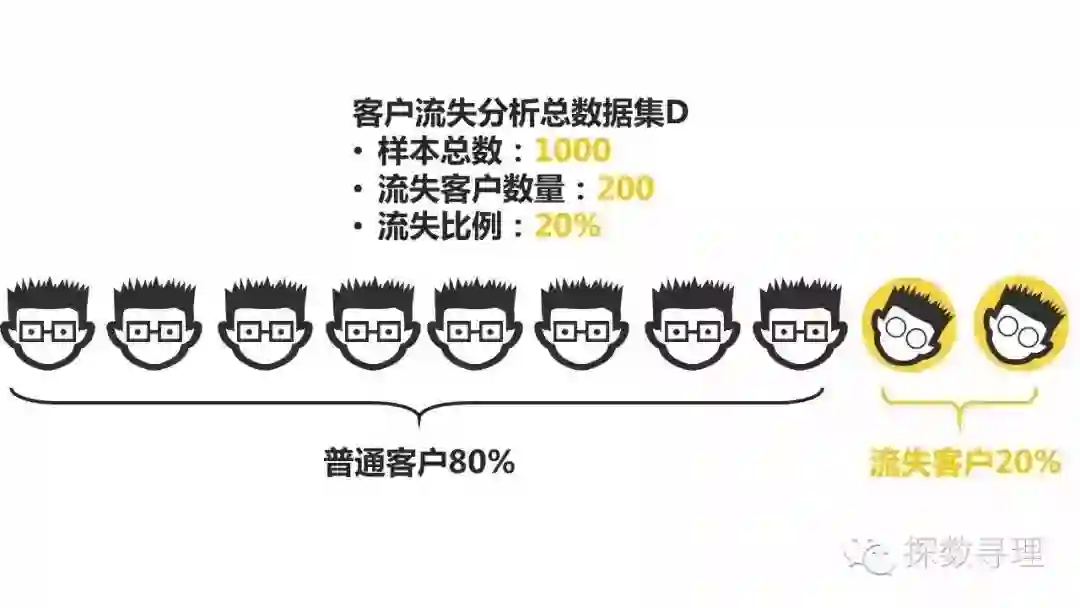
接下来,我们随机抽取数据集D中的800个样本作为训练集,200个样本作为测试。但是由于抽样的问题,其中有100名流失客户被分在了训练集,另外的100名客户被分在了测试集。
让我们在回顾一下分布比例,原本在数据集D中,流失客户的分布比例是20%,而经过划分后,我们在训练集中的流失比例只有12.5%,而在测试集中流失比例达到50%,显然,我们的数据分布与原有的数据分布发生了极大的改变,而这很有可能给我们的模型训练以及评估带来非常大的隐患。

因此,为了避免这种情况,在我们使用留出法进行训练集测试集划分的时候,也会采用分层抽样的方法。
回到原来的例子,我们可能从200个流失客户中随机抽取80%放到训练集,20%放到测试集;再从800个非流失客户中抽取80%放到训练集,剩下20%又放回到测试集。值得注意的是,划分训练集以及测试集的方法是多样的,我们完全可以通过抽样方法的结合,帮助我们更好的决定训练集以及测试集的组成;
除了结合抽样方式,另外一种改进策略被称为“重复抽样”。它的思想是这样的,考虑到我们只进行一次随机抽样划分训练集与测试集可能会有存在较大的不稳定性,因此我们就将抽样结果重复p次,最后把p次结果进行加和求平均。
2交叉验证(Cross Validation)
虽然留出法可以通过分层抽样解决数据分布不等的问题,但是由于我们需要拿出一部分数据作为测试,因此总有部分的数据不能用于构建模型,而一种更好的选择是交叉验证,一般也简称CV。
交叉验证法是一个将整体数据集平均划分为k份,先取第一份子集数据作为测试集,剩下的k-1份子集数据作为训练集进行一次试验;之后再取第二份子集数据,剩下的k-1份子集数据在进行一次试验,不断往复,最后重复k次的过程,一般我们称之为k折交叉检验,交叉检验是我们进行参数调整过程中非常重要的一个方法。
一般我们常用十折交叉检验,不妨我们设定k=10进行举例:
首先我们把总数据集划分为10份,分别成D1,D2,… …,D10;
首先选择D1数据集作为测试集,D2,…D10作为训练集。在训练集上构建模型,在测试集上进行模型评估,得到评估记过O1;
之后选择D2数据集作为测试集,D1,D3,…D10作为训练集。在训练集上构建模型,在测试集上进行模型评估,得到评估记过O2;
分别抽去D3,D4,…,D10作为测试集,一共重复10次,并得到10个结果:O1,O2,…,O10;
将得到10个结果:O1,O2,…,O10加和取平均,作为最终评估结果O。


以上过程,我们称之为10折交叉检验。一般而言,在平常的使用中,10折交叉检验比较常见,当然也会有5折交叉检验,3折交叉检验。
更进一步地,类似于留出法可以采取重复抽样,对于交叉检验来说同样也存在着划分方式的不同情况,因此我们也可以采用不同的划分方式重复进行交叉试验的方法,例如,我们利用不同的划分方式划分数据5次,每次都是划分为10折,那我们就称之为5次10折交叉试验
特别地,交叉验证还有一种特殊情况,称之为留一交叉验证(leave one Out)。它是指,我们令样本划分次数k等于数据集合D的样本数量n,即对样本集合D划分为n份子集,每份子集只包含一个样本。这个方法的优缺点都十分的明显,优点点我们每次的训练集都与原始数据集非常接近,并且也能做到训练集与测试集是对立的,这样可以保证我们得到的结果相对比较准确。但相对而言,采取这样的方式也意味着我们的计算开销会大大增加。


最好玩
最通俗
最易懂
de
机器学习课程
最最最重要的是
现在
限免
扫描下方二维码或点击阅读原文即可加入学习