截止2020年4月最新的目标检测总结(第六期)提供下载链接
点击蓝字关注我们 Spring comes

扫码关注我们
公众号 : 计算机视觉战队
扫码回复:目标检测,获取源码及论文链接
RECENT ADVANCES IN OBJECT DETECTION
今天在这一节中,我们将回顾近三年来最先进的目标检测方法。
Detection with Better Engines
近年来,Deep CNN 在许多计算机视觉任务中发挥了核心作用。由于检测器的精度在很大程度上取决于其特征提取网络,因此本文将主干网络 ( 如 ResNet 和 VGG ) 称为检测器的 “ 引擎 ”。下图为三种知名检测系统选择不同引擎[27]时的检测精度:Faster RCNN,R-FCN和SSD。
在本节中,我们将介绍深度学习时代的一些重要的检测引擎。关于这个话题的更多细节,我们请读者参考下面的调查。
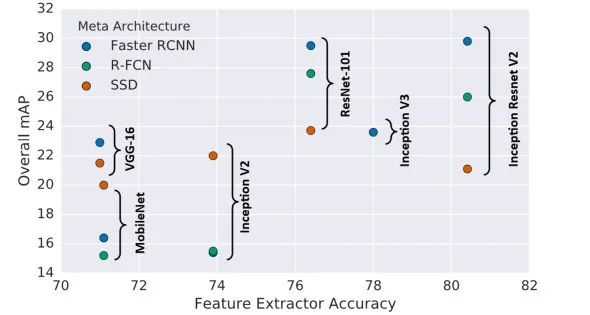
Object detectors with new engines
近三年来,许多最新的引擎已应用于目标检测。例如,一些最新的目标检测模型,如 STDN,DSOD,TinyDSOD,Pelee,都选择 DenseNet作为检测引擎。Mask RCNN作为实例分割的最先进模型,采用了下一代 ResNet:ResNeXt作为其检测引擎。此外,为了加快检测速度,Xception引入了深度可分离卷积运算是 Incepion 的改进版本,也被用于MobileNet和LightHead RCNN等检测器。
Detection with Better Features
特征表示的质量是目标检测的关键。近年来,许多研究人员在一些最新的引擎的基础上,进一步提高了图像特征的质量,其中最重要的两组方法是:1) 特征融合;2) 学习具有较大接受域的高分辨率特征。
Why Feature Fusion is Important?
不变性(Invariance) 和 同变性/等变化(equivariance) 是图像特征表示的两个重要性质。分类 需要不变的特征表示,因为它的目的是学习高级语义信息。目标定位 需要等变的表示,因为它的目的是区分位置和尺度的变化。由于目标检测由目标识别和定位两个子任务组成,因此检测器必须同时学习不变性和等变性。
近三年来,特征融合在目标检测中得到了广泛的应用。由于CNN模型由一系列卷积层和池化层组成,更深层次的特征具有更强的不变性,但等变性较小。虽然这有利于分类识别,但在目标检测中定位精度较低。相反,较浅层次的特征不利于学习语义,但它有助于对象定位,因为它包含更多关于边缘和轮廓的信息。因此,CNN模型中深度和深度特征的融合有助于提高不变性和等变性。
Feature Fusion in Different Ways
在目标检测中进行特征融合的方法有很多。本文从两个方面介绍了近年来的一些方法:1) 处理流程;2) 元素智能操作。
目前用于目标检测的特征融合方法可分为两类:1) 自底向上融合,2) 自顶向下融合,如下图(a)-(b)所示。自底向上的融合通过跳跃连接将浅层特征前馈到更深的层。相比之下,自顶向下的融合将更深层次的特征反馈给更浅层次。除了这些方法,最近还提出了更复杂的方法,例如跨不同层编织特性。
由于不同层的 feature map 在空间维度和通道维度上都可能有不同的尺寸,因此可能需要对 feature map 进行调整,如调整通道数量、上采样低分辨率 map 或下采样高分辨率 map ,使其尺寸合适。最简单的方法是使用最接近或双线性插值(nearest or bilinear-interpolation)。此外,分数阶条纹卷积 ( 又称转置卷积 )是近年来另一种常用的调整 feature map 大小和调整通道数量的方法。使用分数阶条纹卷积的优点是,它可以学习一种适当的方法来执行上采样本身。
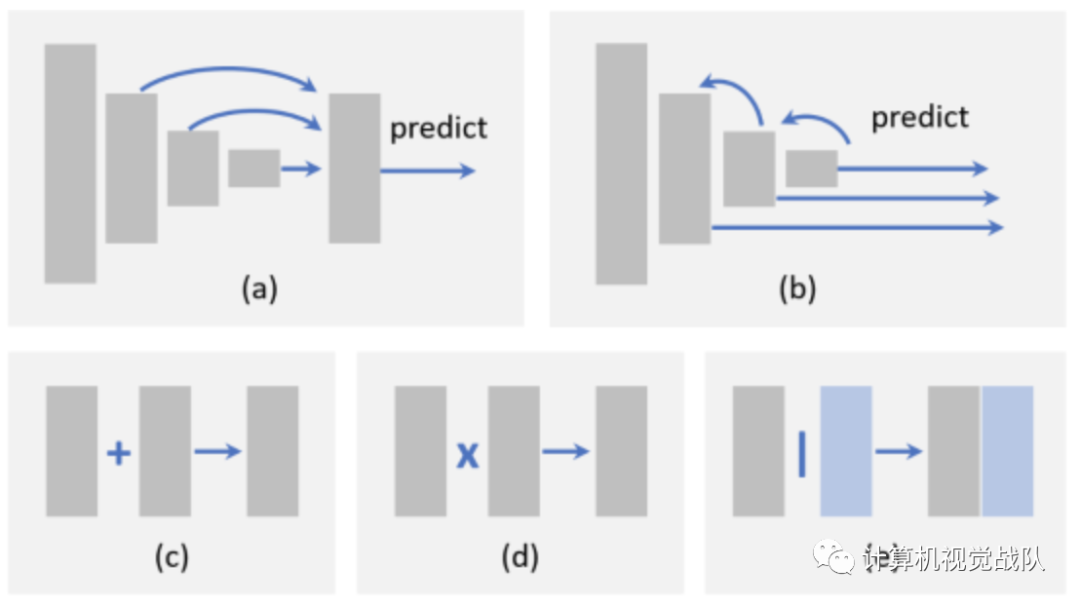
从局部的角度看,特征融合可以看作是不同特征映射之间的元素智能操作。有三组方法:1) element-wise 的和,2) element-wise 的积,3) 串联,如上图(c)-(e)所示。element-wise的和是执行特征融合最简单的方法。它已被频繁地用于许多最近的目标检测器。element-wise 的积与 element-wise 的和非常相似,唯一的区别是使用乘法而不是求和。element-wise 的积的一个优点是,它可以用来抑制或突出某个区域内的特性,这可能进一步有利于小对象检测。特征拼接/串联是特征融合的另一种方式。它的优点是可以用来集成不同区域的上下文信息,缺点是增加了内存。
Learning High Resolution Features with Large Receptive Fields
接受域和特征分辨率是基于CNN的检测器的两个重要特点,前者是指输入像素的空间范围,用于计算输出的单个像素,而后者对应于输入与特征图之间的下采样率。具有较大接受域的网络能够捕获更大范围的上下文信息,而具有较小接受域的网络则可能更专注于局部细节。
正如我们前面提到的,特征分辨率越低,就越难检测小对象。提高特征分辨率最直接的方法是去除池化层或降低卷积下采样率。但这将带来一个新的问题,即由于输出步长减小,接受域会变得太小。换句话说,这将缩小检测器的“视线”范围,并可能导致一些大型目标的漏检。
一种同时提高接收域和特征分辨率的方法是引入膨胀/扩展卷积(dilated convolution),又称无孔卷积(atrous convolution)或带孔卷积(convolution with holes)。膨胀/扩展卷积最初是在语义分割任务中提出的。其主要思想是对卷积滤波器进行扩展,和使用稀疏参数。例如,膨胀率为2的3x3滤波器会具有与核为5x5的滤波器相同的接受域,但只有9个参数。膨胀卷积目前已广泛应用于目标检测中,在不需要任何额外参数和计算代价的情况下,被证明是提高精度的有效方法。
Beyond Sliding Window
虽然目标检测已经从手工特征发展到深度神经网络,但仍然遵循 “ 特征图滑动窗口 ” 的模式。最近,在滑动窗之外还安装了一些检测器。
子区域搜索提供了一种新的检测方法。最近的一种方法是将检测视为一个路径规划过程,从初始网格开始,最终收敛到所需的ground truth box。另一种方法是将检测看作是一个迭代更新过程,对预测边界框的角进行细化。
关键点定位是一项重要的计算机视觉任务,有着广泛的应用,如面部表情识别、人体姿态识别等。由于图像中任何对象都可以由其在ground truth box的左上角和右下角唯一确定,因此检测任务可以等价地框定为一对关键点定位问题。这个想法最近的一个实现是预测拐角的热图。该方法的优点是可以在语义分割框架下实现,不需要设计多尺度的锚框。
Improvements of Localization
为了提高定位精度,目前的检测方法主要有两种:1) 边界框细化法;2) 设计新的损失函数进行精确定位。
Bounding Box Refinement
提高定位精度最直观的方法是对边界框进行细化,可以将其视为检测结果的后处理。尽管边界框回归已经集成到大多数现代目标检测器中,但是仍然有一些具有意外尺度的对象不能被预定义的锚框很好地捕获。这将不可避免地导致对其位置的不准确预测。由于这个原因,“ 迭代边界框细化(iterative bounding box refinement)” 最近被引入,它将检测结果迭代地输入BB回归器,直到预测收敛到正确的位置和大小。但也有研究人员认为该方法不能保证定位精度的单调性,即多次使用BB回归可能会使定位退化。
Improving Loss Functions for Accurate Localization
在大多数现代检测器中,目标定位被认为是一个坐标回归问题。然而,这种模式有两个缺点。首先,回归损失函数并不对应最终的位置评估。例如,我们不能保证较低的回归误差总是会产生较高的IOU预测,特别是当对象的长径比非常大时。其次,传统的边界框回归方法不能提供定位的置信度。当多个BB重叠时,可能导致非最大抑制失败 ( 详见之前的分享,点击获取连接 )。
设计新的损失函数可以缓解上述问题。最直观的设计是直接使用IoU作为定位损失函数。其他一些研究人员进一步提出了一种IOU 引导的 NMS来改进训练和检测阶段的定位。此外,一些研究者也尝试在概率推理框架下改进定位。与以往直接预测框坐标的方法不同,该方法预测了边界框位置的概率分布。
Learning with Segmentation
目标检测和语义分割是计算机视觉中的重要任务。近年来的研究表明,通过学习和语义分割可以提高目标检测能力。
Why Segmentation Improves Detection?
语义分割提高目标检测能力的原因有三个。
边缘和边界是构成人类视觉认知的基本要素。在计算机视觉中,物体(如汽车、人)和物体(如天空、水、草)的区别在于前者通常有一个封闭的、明确的边界,而后者没有。由于语义分割任务的特征能够很好地捕捉到对象的边界,因此分割可能有助于分类识别。
对象的ground-truth边界框由其定义良好的边界决定。对于一些特殊形状的物体 ( 例如,想象一只猫有很长的尾巴 ),很难预测高IOU的位置。由于目标边界可以很好地编码在语义分割特征中,分割学习有助于准确的目标定位。
日常生活中的物体被不同的背景所包围,如天空、水、草等,这些元素构成了一个物体的语境。整合上下文的语义分割将有助于目标检测,例如,飞机更有可能出现在空中而不是水上。
How Segmentation Improves Detection?
通过分割提高目标检测的主要方法有两种:1) 采用丰富的特征学习;2) 采用多任务损失函数学习。
最简单的方法是将分割网络看作一个固定的特征提取器,并将其作为附加特征集成到检测框架中。该方法的优点是易于实现,缺点是分割网络可能带来额外的计算。
另一种方法是在原有检测框架的基础上引入额外的分割分支,用多任务损失函数 ( 分割损失+检测损失 ) 训练该模型。在大多数情况下,分割分支将在推理阶段被删除。优点是检测速度不受影响,缺点是训练需要像素级的图像标注。为此,一些研究人员采用了 “ 弱监督学习 ” 的思想:他们不是基于像素级注释掩码进行训练,而是基于边界框级注释训练分割分支。
Robust Detection of Rotation and Scale Changes
目标旋转和尺度变化是目标检测中的重要挑战。由于CNN学习到的特征是不受旋转和尺度变化的影响的,近年来很多人在这个问题上做出了努力。
Rotation Robust Detection
对象旋转在人脸检测、文本检测等检测任务中非常常见。这个问题最直接的解决方案是数据扩充,使任何方向的对象都能被扩充的数据很好地覆盖。另一种解决方案是为每个方向训练独立的检测器。除了这些传统的方法,最近还有一些新的改进方法。
旋转不变损失函数学习的思想可以追溯到20世纪90年代。最近的一些工作对原有的检测损失函数进行了约束,使旋转后的物体的特征保持不变。
改进旋转不变的检测的另一种方法是对候选对象进行几何变换。这对于多级检测器尤其有用,前阶段的相关性将有利于后续的检测。这种思想的代表是空间变压器网络(Spatial Transformer Networks,STN )。STN目前已被用于旋转文本检测和旋转人脸检测。
在 two-stage 检测器中,特征池化的目的是为任意位置和大小的对象建议(object proposal)提取固定长度的特征表示,首先将 proposal 均匀地划分为一组网格,然后将网格特征串联起来。由于网格划分是在直角坐标系下进行的,其特征对旋转变换不具有不变性。最近的一项改进是在极坐标下对网格进行网格划分,使特征对旋转变化具有鲁棒性。
Scale Robust Detection
近年来,在尺度鲁棒检测的训练和检测阶段都有了改进。
大多数现代检测器都是将输入图像重新缩放到一个固定的尺寸,并将物体在所有尺度下的损失进行反向传播,如下图(a)所示。但是,这样做的缺点是会出现 “ 尺度不平衡 ” 问题。在检测过程中构建图像金字塔可以缓解这一问题,但不能从根本上解决。最近的一个改进是图像金字塔的尺度标准化 ( Scale Normalization for Image Pyramids,SNIP ) ,它在训练阶段和检测阶段都建立图像金字塔,只对一些选定尺度的损失进行反向传播,如下图(b)所示。一些研究人员进一步提出了一种更有效的训练策略:使用高效重采样的SNIP(SNIP with Efficient Resampling,SNIPER),即,将图像裁剪并重新缩放到一组子区域,以便从大规模批量训练中获益。
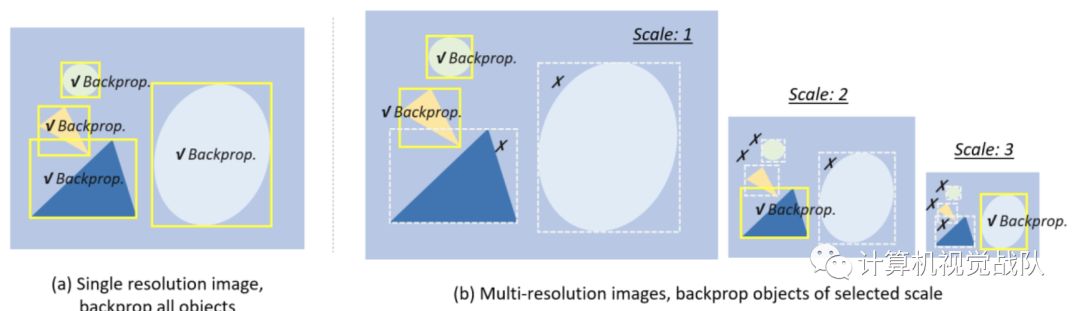
现代检测器大多采用固定的结构来检测不同尺寸的物体。例如,在一个典型的基于CNN的检测器中,我们需要仔细定义锚框的大小。这样做的一个缺点是配置不能适应意外的尺度变化。为了提高对小目标的检测,近年来的一些检测器提出了一些 “ 自适应放大(adaptive zoom-in) ” 技术,自适应地将小目标放大为 “ 大目标 ”。最近的另一项改进是学习预测图像中对象的尺度分布,然后根据分布自适应地重新缩放图像。
Training from Scratch
大多数基于深度学习的检测器首先在大规模数据集(如ImageNet)上进行预训练,然后针对特定的检测任务进行微调。人们一直认为预训练有助于提高泛化能力和训练速度,问题是,我们真的需要在 ImageNet 上对检测器进行预训练吗? 事实上,采用预训练网络进行目标检测存在一定的局限性。第一个限制是ImageNet分类和目标检测之间的散度,包括它们的损失函数和尺度/类别分布。第二个限制是领域不匹配。由于ImageNet中的图像是RGB图像,而有时需要进行检测的是深度图像(RGB-d)或三维医学图像,因此无法很好地将预先训练好的知识转移到这些检测任务中。
近年来,一些研究人员尝试从零开始训练一种目标检测器。为了加快训练速度和提高稳定性,一些研究人员引入密集连接(dense connection)和批量归一化(batch normalization)来加速浅层的反向传播。最近K . He等人的工作进一步质疑预训练的范式通过探索相反的制度推进:他们报告了使用从随机初始化训练而来的标准模型对COCO数据集进行目标检测的有竞争性的结果,唯一的改变是增加了训练迭代的次数,以便随机初始化的模型可以收敛。即使只使用10%的训练数据,随机初始化训练的鲁棒性也令人惊讶,这表明ImageNet预处理可以加快收敛速度,但不一定提供正则化或提高最终检测精度。
Adversarial Training
由A. Goodfellow等人于2014年提出的生成式对抗网络(Generative Adversarial Networks,GAN)近年来受到了极大的关注。一个典型的GAN由两个神经网络组成:一个生成网络和一个判别网络,它们在极小极大优化框架下相互竞争。通常,生成器学习从潜在空间映射到感兴趣的特定数据分布,而鉴别器的目的是区分真实数据分布中的实例和生成器生成的实例。GAN广泛应用于图像生成、图像样式传输、图像超分辨率等计算机视觉任务。近年来,GAN也被应用于目标检测,尤其是对小遮挡目标的检测。GAN被用来通过缩小小目标和大目标之间的模型表示来增强对小目标的检测。为了提高对被遮挡物体的检测,最近的一个想法是使用对抗性训练生成遮挡掩模。与在像素空间中生成示例不同,对抗性网络直接修改特性来模拟遮挡。
此外,“ 对抗性攻击 ”研究如何用对抗性的例子攻击检测器,近年来受到越来越多的关注。这一课题的研究对于自主驾驶来说尤为重要,因为在保证其对对抗攻击的鲁棒性之前,不能完全信任它。
Weakly Supervised Object Detection
现代目标探测器的训练通常需要大量的人工标记数据,而标记过程费时、昂贵、低效。弱监督目标检测 ( Weakly Supervised Object Detection,WSOD ) 的目标是通过训练一个只带有图像级注释而不是边界框的检测器来解决这一问题。
近年来,多实例学习在WSOD中得到了广泛的应用。多实例学习是一种有监督的学习方法。多实例学习模型不是使用一组单独标记的实例进行学习,而是接收一组标记的包,每个包包含多个实例。如果将一个图像中的候选对象看作一个包,并将图像级注释看作标签,那么WSOD可以表示为一个多实例学习过程。
类激活映射是最近出现的另一组WSOD方法。对CNN可视化的研究表明,尽管没有对目标位置的监控,但是CNN的卷积层表现为目标检测器。类激活映射揭示了如何使CNN在接受图像级标签训练的情况下仍然具有定位能力。
除了上述方法外,还有一些研究者认为WSOD是一个proposal排序过程,通过选择信息量最大的区域,然后用图像级注释对这些区域进行训练。WSOD的另一个简单方法是屏蔽图像的不同部分。如果检测分数急剧下降,那么一个物体将高概率被覆盖。此外,交互注释在训练中考虑了人的反馈,从而改进了WSOD。最近,生成对抗性训练被用于WSOD。

通知
计算机视觉战队正在组建深度学习技术群,欢迎大家申请加入!
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。
扫码关注我们
公众号 : 计算机视觉战队
扫码回复:目标检测,获取源码及论文链接
我们开创一段时间的“计算机视觉协会”知识星球,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。


