Attention isn’t all you need!BERT的力量之源远不止注意力
选自medium
作者:Damien Sileo
机器之心编译
参与:Geek AI、路
本文尝试从自然语言理解的角度解释 BERT 的强大能力。作者指出Transformer不只有注意力(解析),还注重组合,而解析/组合正是自然语言理解的框架。
BERT 为何如此重要
BERT 是谷歌近期发布的自然语言处理模型,它在问答系统、自然语言推理和释义检测(paraphrase detection)等任务中取得了突破性的进展。由于 BERT 是公开可用的,它在研究社区中很受欢迎。
下图显示了 GLUE 基准测试分数的演变趋势,GLUE 基准测试分数即在多个自然语言处理评估任务中的平均得分。
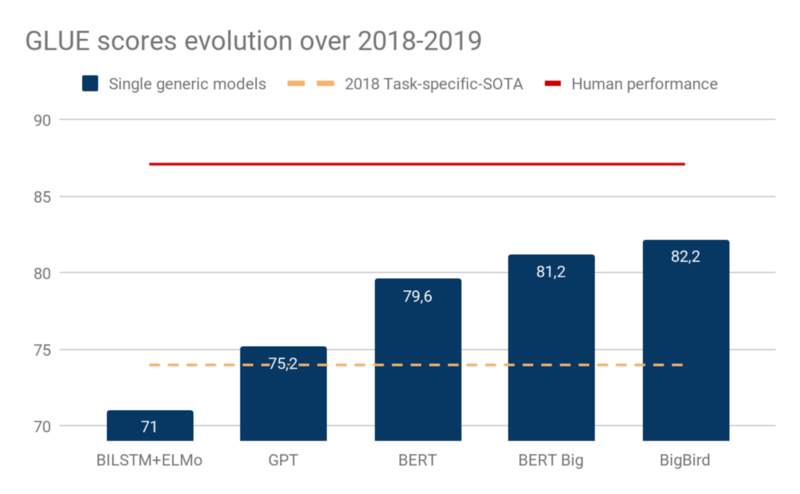
虽然尚不清楚是否所有的 GLUE 任务都非常有意义,但是基于 Transformer 编码器的通用模型(Open-GPT、BERT 和 BigBird)在不到一年的时间内缩小了与任务专用模型和人类的差距。
然而,正如 Yoav Goldberg 在论文《Assessing BERT’s Syntactic Abilities》所述,我们并没有完全理解 Transformer 是如何对句子进行编码的。
与 RNN 不同,Transformer完全依赖于注意力机制,除了通过每个单词的绝对位置的嵌入对单词进行标记外,Transformer 对单词顺序没有明确的概念。这种对注意力的依赖可能会导致 Transformer 在语法敏感任务上的性能不如 RNN (LSTM)模型,后者直接对词序建模并显式跟踪句子状态。
有一些文章已经深入探讨了 BERT 模型的技术细节。本文将尝试提供一些新的见解和假设,从而解释 BERT 强大的能力。
语言理解的框架:解析/组合
人类理解语言的方式一直是一个悬而未决的问题。在 20 世纪,两个互补的理论对这个问题进行了说明:
组合原则(Compositionalityprinciple)指出,复合词的意义来源于每个单词的意义以及这些单词组合的方式。根据这一原则,名词性短语「carnivorousplants」(食肉植物)的意义可以通过组合过程从「carnivorous」和「plant」的意义中派生出来。[Szabó 2017]
另一个原则是语言的层次结构。该理论指出,通过分析,句子可以被分解成从句等简单结构。从句又可以被分解成动词短语和名词性短语等结构。
对层次结构进行解析,并递归地从它们的组成部分中提取出意义,直到达到句子级别,这对于语言理解是一种很好的方法。想想「Bart watched a squirrel with binoculars」(Bart用双筒望远镜观察松鼠)这句话。一个好的解析组件可以生成如下解析树:
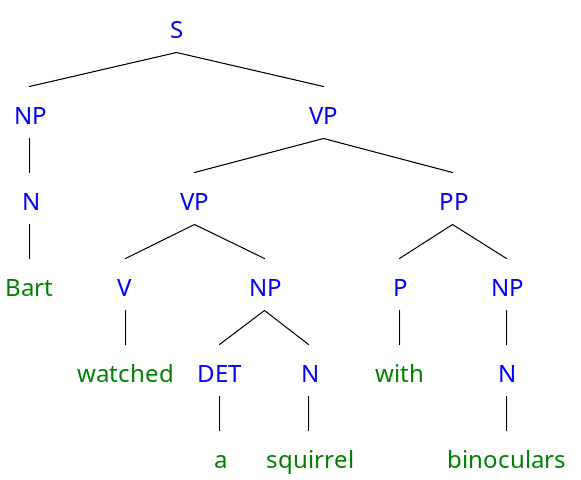
「Bart watched a squirrel withbinoculars」这句话的二叉解析树。
这个句子的意义可以从连续的组合过程中派生而来(将「a」与「squirrel」组合、「watched」与「a squirrel」复合,「watched a squirrel」与「with binoculars」),直到获知句子的意义。
向量空间(如在词嵌入中)可用于表示单词、短语以及其它组成部分。组合过程可以被构造为函数 f,它将把(“a”、“squirrel”)合成为一个有意义的向量表示 “a squirrel” =f(“a”, “squirrel”)。[Baroni 2014]
然而,组合和解析都是很困难的任务,并且这两个任务彼此需要。
显然,组合依赖解析的结果来确定应该组合什么。但即使有正确的输入,组合也是一个难题。例如,形容词的意义会根据它们所描述的单词而变化:「white wine」(白葡萄酒)的颜色实际上是黄色的,而白猫是白色的。这种现象被称为co-composition。 [Pustejovsky 2017]
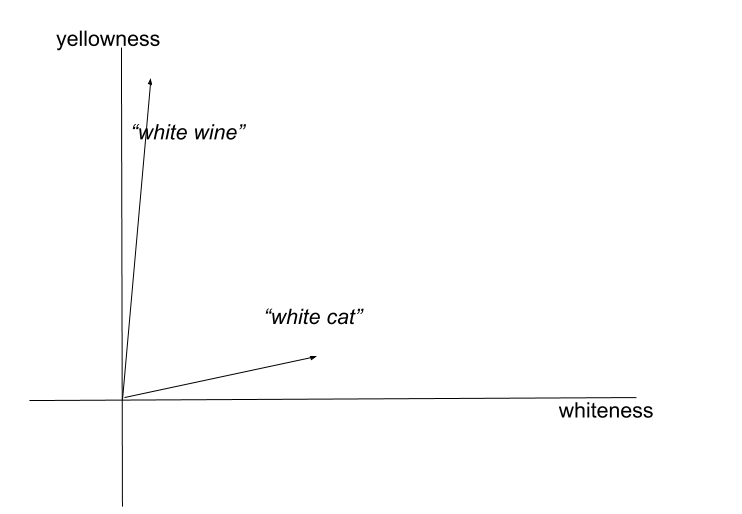
「白葡萄酒」和「白猫」在二维语义空间中的表征(空间的维度是颜色)。
组合还需要更广泛的上下文。例如,「绿灯」中的单词组合方式取决于具体情况。绿灯可以表示认可,也可以表示真正绿色的灯。一些惯用表达的意义需要某种形式的记忆,而不是简单地组合。因此,在向量空间中执行组合过程需要如深度神经网络这样的强大非线性函数(也具有记忆功能 [Arpit 2017])。
相反,解析操作在某些情况下可能需要组合才能工作。不妨考虑句子「Bart watcheda squirrel with binoculars」的另一个解析树:
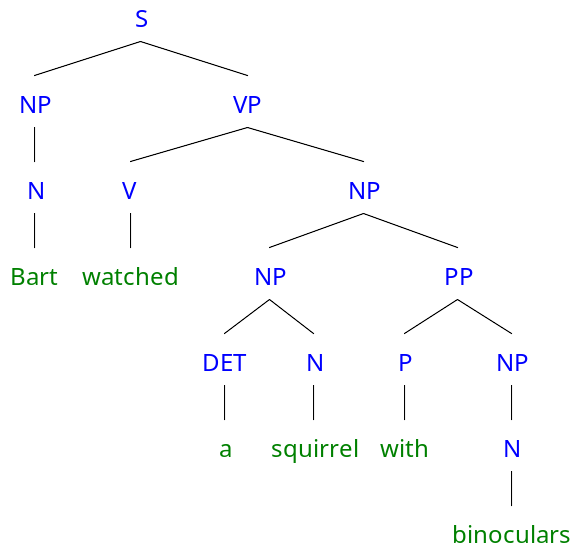
「Bart watched a squirrel withbinoculars」的另一种二叉解析树。
虽然这种解析在句法上是成立的,但它引出了对句子的一种奇怪解释:Bart(裸眼)看到一只拿着双筒望远镜的松鼠。然而,我们必须使用某种形式的组合过程才能确定「一只松鼠拿着双筒望远镜」是不可能的。
通常,在派生出恰当的结构之前,必须经过消歧和对背景知识的整合。但是这种派生也可以通过某些形式的解析和组合来实现。
有一些模型也曾试着将解析和组合一起应用到实践中 [Socher 2013],然而,它们有一个限制,即依赖手动标注的标准解析树,此外,它们也已经被一些更简单的模型超越了。
BERT 如何实现解析/组合
我们假设 Transformer 以一种创新的方式严重依赖这两种操作(解析/组合):由于组合需要解析,而解析又需要复合,所以Transformer 使用迭代过程,通过连续的解析和组合步骤来解决相互依赖的问题。实际上,Transformer 是由几个堆叠的层(也称为块)组成的。每个块包括一个注意力层和一个紧接着的非线性函数(应用于每个 token)。
我们试着展示这些组件与解析/组合框架之间的联系:
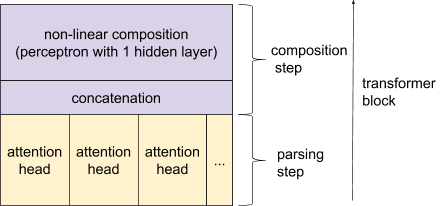
一个 Transformer 块可以被看做连续的解析和组合步骤。
将注意力作为一个解析步骤
BERT 模型使用注意力机制让输入序列中的每个 token(例如,句子由词或子词 token 组成)能够注意到其余的 token。
为了说明这一点,我们使用一种可视化工具(来自这篇文章:https://medium.com/dissecting-bert/dissecting-bert-part2-335ff2ed9c73)深入研究注意力头,并在预训练 BERT-Base Uncased 模型(谷歌发布的 4 种BERT 预训练模型中的一种)上测试了我们的假设。在如下注意力头示意图中,「it」这个单词会注意到该句中所有其它 token,但是似乎重点关注「street」和「animal」这两个词。

「it」在 layer 0head #1 得到的注意力值的可视化结果。
BERT 的每一层使用 12 个单独的注意力机制。因此在每一层上,每个 token 都可以关注其它 token 的 12 个不同方面。由于 Transformer 使用许多不同的注意力头(这个 BERT base 模型使用了 12*12=144个注意力头),每个注意力头可以重点关注不同类型的组合。
我们忽略了与 [cls] 和[SEP] token 相关的注意力值。我们试着使用几个句子进行测试,发现结果很难不被过度解读,你可以随意在这个 colab notebook(https://colab.research.google.com/drive/1Nlhh2vwlQdKleNMqpmLDBsAwrv_7NnrB)中使用不同的句子测试我们的假设。请注意,在这些图中,左侧的序列注意右侧的序列。
在第二层中,注意力头 #1 似乎会基于相关性生成组合的组成部分。

第二层的注意力头 #1 的注意力值可视化结果,它似乎将相关的 token 配对。
更有趣的是,在第三层中,注意力头 #9 似乎展示了更高层次的组成部分:一些 token 注意到了相同的核心单词(「if」、「keep」、「have」)。

第三层的注意力头 #11 的注意力值可视化结果,其中一些token似乎注意到了某些的核心单词(例如「have」、「keep」)。
在第五层中,注意力头 #6 执行的匹配过程似乎更关注特定的组合,特别是涉及动词的组合。像 [SEP] 这样的特殊 token 似乎被用来表示没有找到匹配关系。这可以使注意力头发现适合组合的特定结构。这种一致的结构可被传递给组合函数。

第五层的注意力头#6 的注意力值可视化结果,其中 (we, have)、(if, we)、(keep, up)、(get, angry) 等组合似乎更受到关注。
任何树状结构都可以通过连续的浅层解析层来表示,如下图所示:
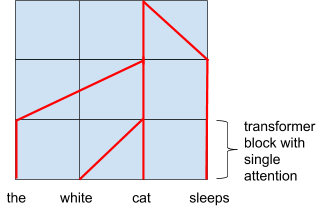
如何用一些注意力层表示树状结构。
在查看 BERT 注意力头的过程中,我们没有发现如此清晰的树状结构,但是 Transformer 还是有可能对其进行表征。
我们注意到,由于编码是在所有层上同时进行的,因此我们很难正确地解释 BERT 正在做什么。对于给定层的分析只对其上一层或下一层有意义。解析也分布在各个注意力头上。
下图展示了,在两个注意力头的情况下, BERT 的注意力机制更加实际的情况。
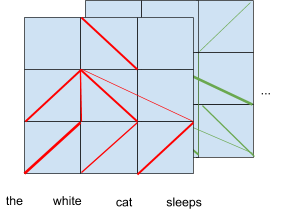
BERT 模型中的注意力值更加实际的情况。
然而,正如我们之前看到的那样,解析树是一种高级的抽象表示,它可以建立在在更复杂的「根茎」(rhizomatic)[Deleuze 1987] 结构之上。例如,我们可能需要找出代词指的是什么,以便对输入进行编码(共指消解)。在其他情况下,可能还需要根据全局上下文来进行消歧。
意外的是,我们发现了一个似乎在真正执行共指消解的注意力头(第六层的注意力头 #0)。此外,正如文章《Understanding BERT Part 2: BERT Specifics》中提到的,一些注意力头似乎为每个单词提供全局上下文(第 0 层的注意力头 #0)。

第六层的注意力头 #0 中发生的共指消解。

每个单词都会关注该句中所有其它的单词。这可能为每个单词创建一个粗略的上下文语境。
组合阶段
在每一层中,所有注意力头的输出都会被级联并输入到一个可表示复杂非线性函数的神经网络(这是构建一个有表达能力的组合过程所需要的)。
该神经网络依靠注意力头产生的结构化输入,可以执行各种各样的组合。在前文展示的第五层中,注意力头 #6 可以引导模型进行下列组合:(we, have)、(if, we)、(keep, up)、(get,angry)。该模型可以用非线性的方式将它们组合起来,并返回一个组合后的表征。因此,多注意力头可作为工具为组合做准备。
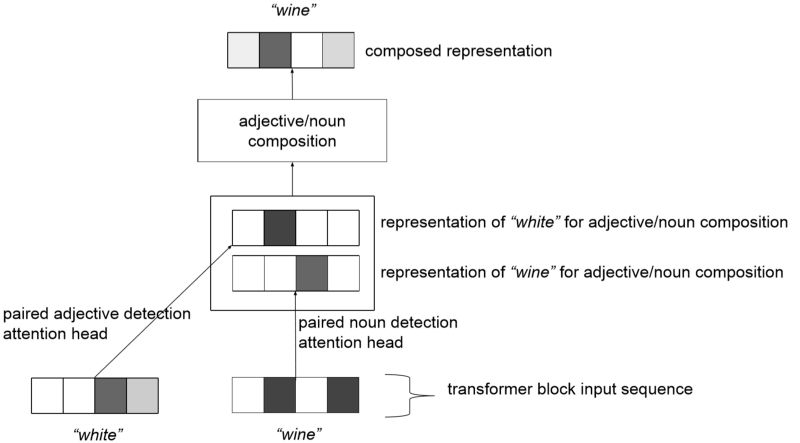
如何用注意力头为特定的组合(如形容词和名词的组合)做准备。
虽然我们没有发现注意力头更一致地关注某些组合(如形容词/名词),但动词/副词的组合和模型所利用的其他组合之间可能会有一些共同点。
可能存在许多相关的组合(词-子词、形容词-名词、动词-介词、从句-从句)。更进一步讲,我们可以将消歧看作把一个歧义词(如 bank)与其相关的上下文单词(如 river 或 cashier)组合的过程。在组合阶段,模型还可以将给定上下文中与概念相关的背景常识知识进行整合。

将消歧作为一种组合。
此外,组合还可能涉及词序推理。有人认为,位置编码(positional encoding)可能不足以正确地编码单词的顺序。然而,位置编码的初衷就是为每个 token 进行粗粒度、细粒度上和可能精确的位置编码。(位置编码是一个向量,它会被用来与输入嵌入求平均,以为输入序列中的每个 token 生成能够感知位置的表征)。因此,基于两个位置编码,非线性组合理论上可以执行基于单词相对位置的关系推理。
我们假设,在 BERT 模型的自然语言理解中, 组合阶段也起到了很重要的作用:你并不只需要注意力机制(不仅仅需要解析,还需要组合),Attention isn’t all you need!
总结
本文介绍了对 Transformer 的归纳偏置的一些见解。不过,读者需要了解,本文的解释对 Transformer 的能力持乐观态度。读者需要注意的是,LSTM 可以隐式地处理树结构 [Bowman 2015]和组合过程 [Tai 2015]。但是 LSTM 存在一些局限性,其中有一些是由梯度消失问题造成的 [Hochreiter1998]。因此,需要研究人员通过进一步的工作来解释 Transformer 的局限性。
参考文献
BERT: Pre-training of Deep BidirectionalTransformers for Language Understanding [Devlin 2018]
Attention Is All You Need [Vaswani 2017]
Assessing BERT’s SyntacticAbilities[Goldberg 2019]
Compositionality [Szabó 2017] Frege in Space [Baroi,2014]
Co-compositionality in Grammar [Pustejovsky 2017]
A Closer Look at Memorization in DeepNetworks [Arpit 2017]
Recursive Deep Models for SemanticCompositionality Over a Sentiment Treebank [Socher 2013]
Improved Semantic Representations From Tree-StructuredLong Short-Term Memory Networks [Tai 2015]
Tree-structured composition in neuralnetworks without tree-structured architectures [Bowman 2015]
A Thousand Plateaus[Deleuze 1987]
The vanishing gradient problem duringlearning recurrent neural nets and problem solutions [Hochreiter 1998]
Dissecting BERT part 2 [Ingham 2019]
原文链接:https://medium.com/synapse-dev/understanding-bert-transformer-attention-isnt-all-you-need-5839ebd396db
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



