Local GAN | 局部稀疏注意层+新损失函数(文末免费送书活动)
点击蓝字关注我们

计算机视觉研究院专栏
作者:Edison_G
本次分享的文章主要两点贡献。 首先引入了一个新的局部稀疏注意层(local sparse attention layer),该层保留了二维几何形状和局部性。文章证明,用文章的结构替换SAGAN的密集注意力层,我们就可以获得非常显着的FID,初始得分(Inception score )和纯净的视觉效果。在其他所有参数保持不变的情况下,FID分数在ImageNet上从18.65提高到15.94。我们为新层提议的稀疏注意力模式(sparse attention patterns)是使用一种新的信息理论标准设计的,该标准使用信息流图。 文章还提出了一种新颖的方法来引起对立的对抗网络的产生,就是使用鉴别器的注意力层来创建创新的损失函数(an innovative loss function)。这使我们能够可视化新引入的关注头,并表明它们确实捕获了真实图像二维几何的有趣方面。
背景

Local GAN
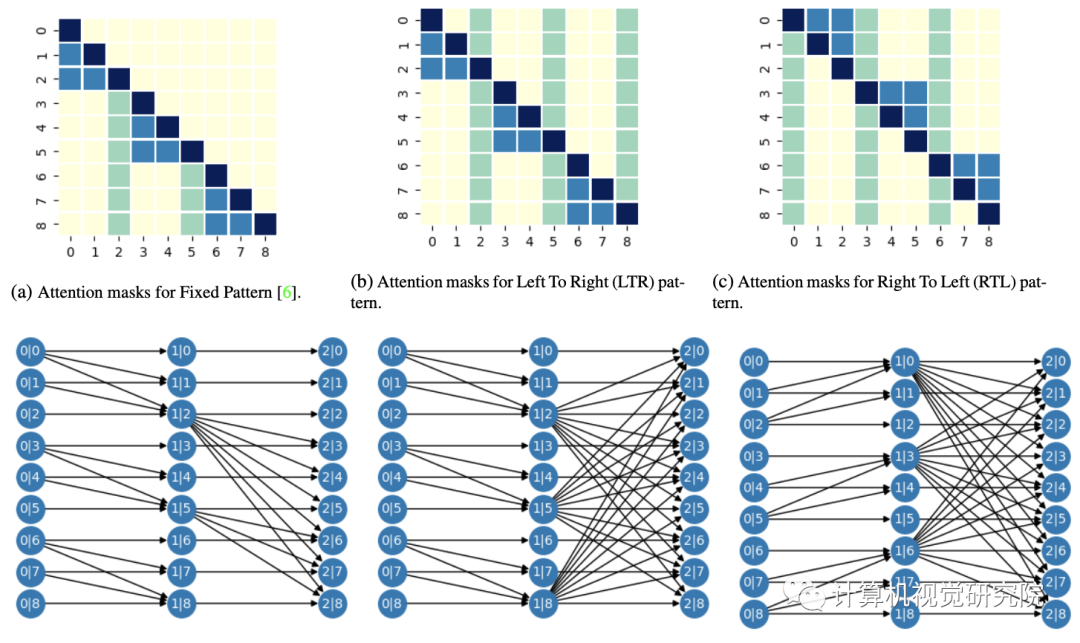
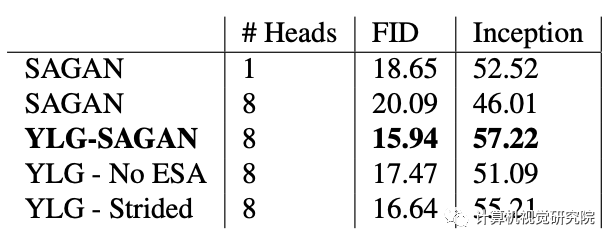
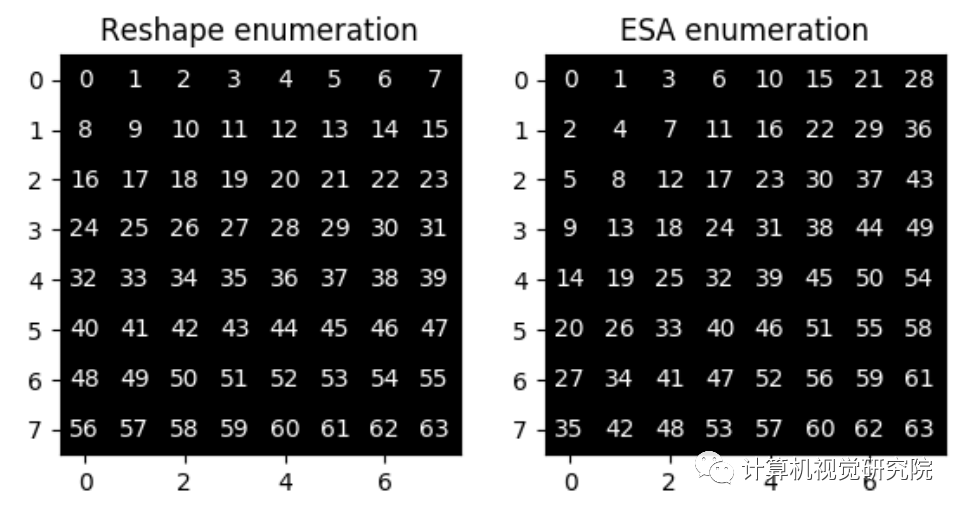
实验&验证



Inverting Generative Models with Attention
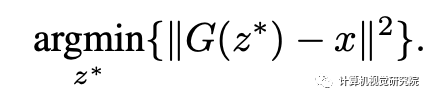
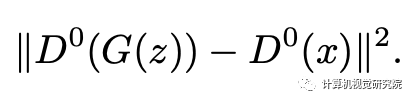
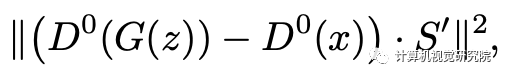



总结



【内容简介】
本书首先从Python 基本语法开始讨论,逐步介绍必备的数学知识与神经网络的基本知识,并利用讨论的内容编写一个深度学习框架TensorPy,有了这些知识作为铺垫后,就开始讨论生成对抗网络(GAN)相关的内容。然后,本书使用比较简单的语言来描述GAN 涉及的思想、模型与数学原理,接着便通过TensorFlow实现传统的GAN,并讨论为何一定需要生成器或判别器。接下来,重点介绍GAN 各种常见的变体,包括卷积生成对抗网络、条件对抗生成网络、循环一致性、改进生成对抗网络、渐近增强式生成对抗网络等内容。


扫码关注我们
公众号 : 计算机视觉研究院
扫码回复:LocalGAN,获取下载链接
登录查看更多
相关内容

专知会员服务
25+阅读 · 2020年7月1日
专知会员服务
63+阅读 · 2020年4月19日
专知会员服务
44+阅读 · 2020年3月4日
Arxiv
11+阅读 · 2018年12月8日
Arxiv
3+阅读 · 2018年5月6日




相关VIP内容
专知会员服务
25+阅读 · 2020年7月1日
专知会员服务
63+阅读 · 2020年4月19日
专知会员服务
44+阅读 · 2020年3月4日
相关资讯
相关论文
Arxiv
11+阅读 · 2018年12月8日
Arxiv
3+阅读 · 2018年5月6日