【AAAI专题】中篇:BRAVE组系列研究进展之“视听模态的生成”



中篇:视听模态的生成

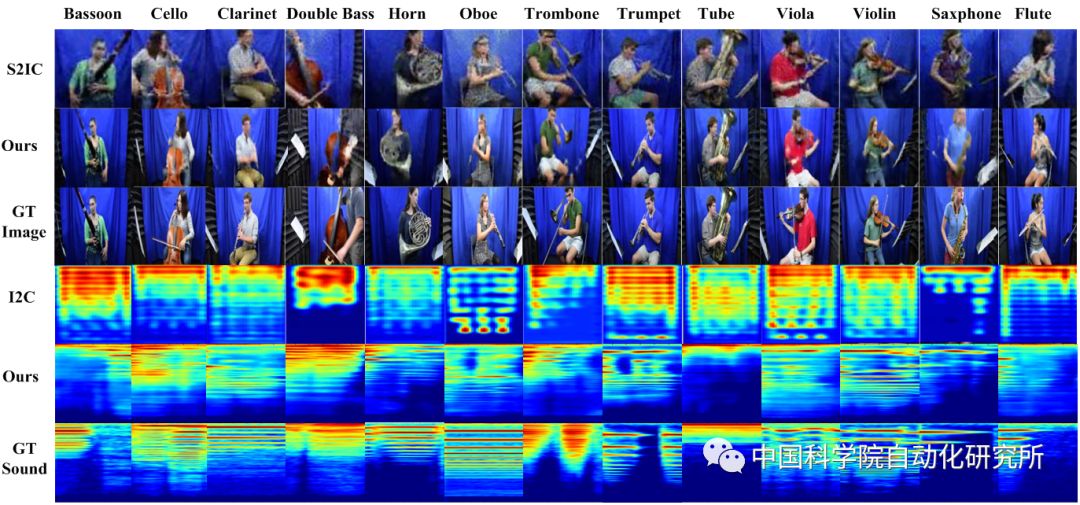
视听模态是视频中的两个共生模态,包含相同和互补信息。利用共同信息可实现模态间的相互转换。同时,互补信息可作为先验去辅助相关工作。因此,充分利用视听模态间的共同和互补信息可以进一步增强相关任务的性能。然而,由于环境干扰和传感器故障等因素,其中的一个模态会受损或者缺失,从而带来一些严重的问题,比如消音的影片或者模糊的屏幕。如果我们可以基于已知模态生成缺失模态,会给许多多媒体任务带来好处。因此,我们致力于创建有效的视听跨模态相互生成模型。
传统的跨模态相互生成方法主要存在以下几个问题,一是模态间存在严重的结构、维度和信息不对称性,导致跨模态相互生成的质量不理想。二是模态间的相互生成是独立的,具有很大的不便性。三是其训练过程并不是端到端的。
为解决上述问题,我们提出基于循环对抗生成网络的跨模态相互生成模型(CMCGAN)。
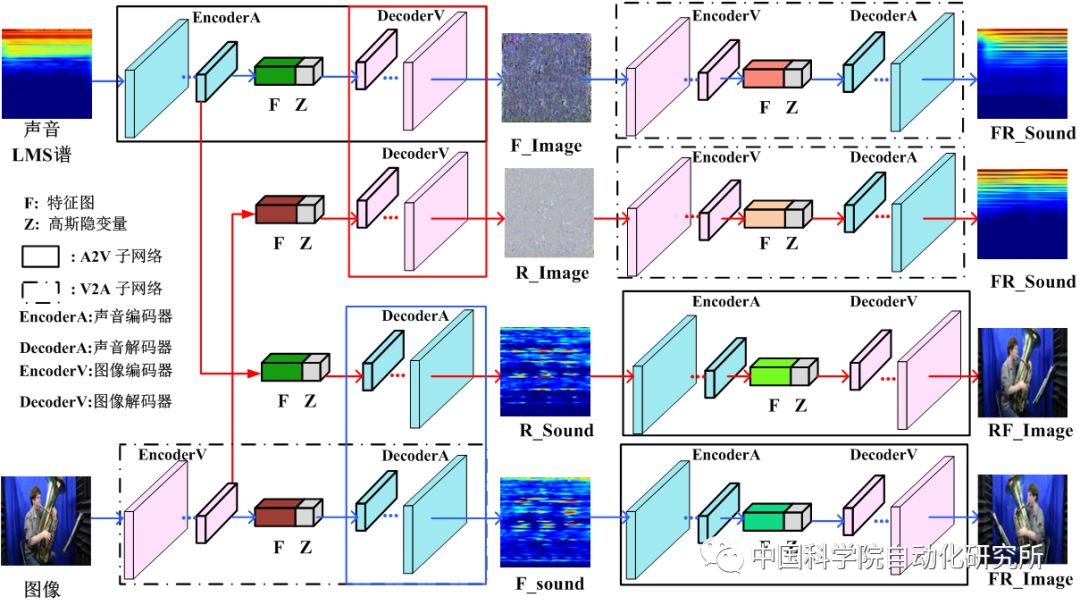
基本框架图
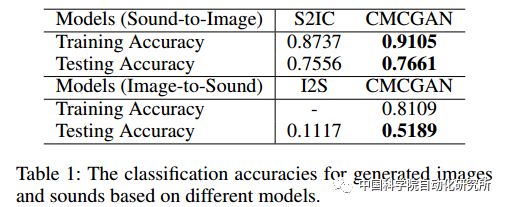
该模型包含四个子网络,分别为A-V(听觉到视觉), V-A(视觉到听觉), A-A(听觉到听觉)和V-V(视觉到视觉)子网络。每个子网络均由一个编码器和一个解码器组成。这四种子网络以对称的形式组成了两种生成路径,一种是V-A-V/A-V-A(视觉-听觉-视觉/听觉-视觉-听觉), 另一种为跨模态生成路径A-A-V/V-V-A(听觉-听觉-视觉/视觉-视觉-听觉)。
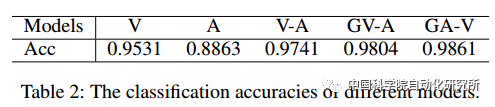
受益于CMCGAN,我们也提出了一个动态多模态分类网络。若输入有两个模态,则首先将它们进行融合然后输入到后续的分类网络中。若输入只有一个模态,则可基于CMCGAN生成缺失模态,然后将已知模态和缺失模态输入到后续的动态多模态分类网络中。我们的贡献有以下几点:
a. 我们提出了一个跨模态循环对抗生成网络去实现跨模态的视听相互生成。
b. 我们提出了一个联合对应对抗损失函数将视听相互生成集成在一个统一的框架中,该损失函数不仅可以区分图像来自原始样本集还是生成集,而且可以判断(图像,声音)是否匹配。
c. 针对不同模态的输入,我们提出了一个动态多模态分类网络。
其中,联合对应对抗损失函数有三个子项:生成器损失函数,判别器损失函数,数据一致性损失函数
a. 联合对应对抗损失函数中判别器损失函数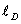
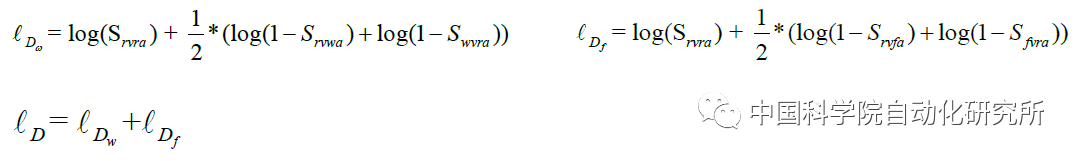
b. 联合对应对抗损失函数中判别器损失函数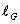
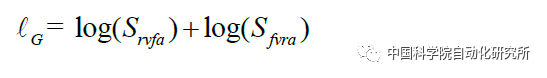
c. 联合对应对抗损失函数中数据一致性损失函数:
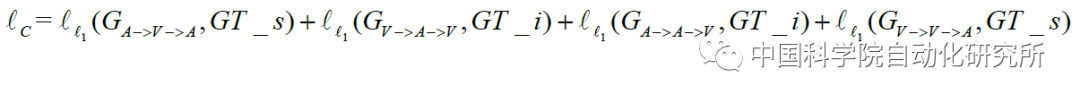
其中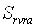

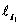
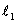

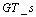
上篇:视听模态的融合(昨日聚焦)
Wangli Hao, Zhaoxiang Zhang*, He Guan, Integrating both Visual and Audio Cues for Enhanced Video Caption, The Thirty-Second AAAI Conference on Artificial Intelligence, AAAI 2018, USA, February 2-7, 2018
中篇:视听模态的生成 (今日聚焦)
Wangli Hao, Zhaoxiang Zhang*, He Guan, CMCGAN: A Uniform Framework for Cross-Modal Visual-Audio Mutual Generation, The Thirty-Second AAAI Conference on Artificial Intelligence, AAAI 2018, USA, February 2-7, 2018
下篇:智能体之间的知识迁移(明日聚焦)
Yuntao Chen, Naiyan Wang, Zhaoxiang Zhang*, DarkRank: Accelerating Deep Metric Learning via Cross Sample Similarities Transfer; The Thirty-Second AAAI Conference on Artificial Intelligence, AAAI 2018, USA, February 2-7, 2018
中国科学院类脑智能研究中心“类脑信息处理研究组”(Bio-inspired-intelligence Research for Artificial Vision and lEarning),又叫BRAVE研究组,由张兆翔研究员带领,瞄准学科前沿,致力于融合智能科学、脑与认知科学的多学科优势,研究创新性的认知脑模型,实现类脑信息处理相关领域理论、方法与应用的突破。
BRAVE团队在借鉴生物神经结构、认知机制与学习特性的神经网络建模与类人学习方向开展了系统性研究,取得了一系列突破性进展。近期,该团队又取得了重大突破,已有3篇论文被2018年国际人工智能年会AAAI录用。AAAI是人工智能领域的顶级会议,即将于2018年2月在美国召开第18届会议。本届会议共收到3800多篇稿件,最终录用933篇,录用率不到25%。张兆翔团队此次被录用的3篇文章中,2篇文章被选为Oral,1篇文章被选为Spotlight poster,展现了该团队的研究实力。

更多精彩内容,欢迎关注
中科院自动化所官方网站:
http://www.ia.ac.cn
欢迎后台留言、推荐您感兴趣的话题、内容或资讯,小编恭候您的意见和建议!如需转载或投稿,请后台私信。
来源:BRAVE研究组
编辑:欧梨成


中科院自动化研究所
微信:casia1956
欢迎搭乘自动化所AI旗舰号!

