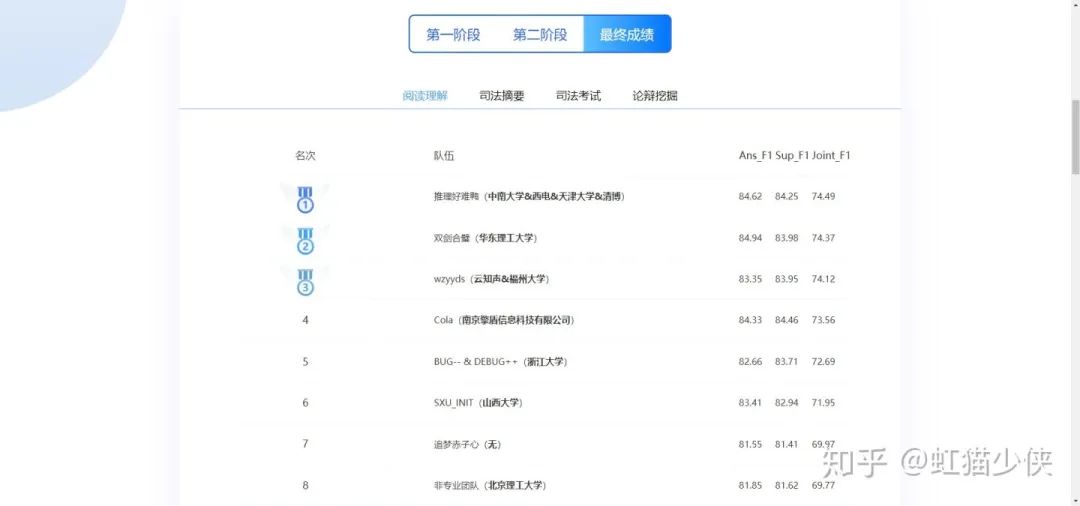
2.使用19年数据时,19年数据文章context长度普遍较长,平均约800-900,这样直接切句子时,容易超出max_len=512,因此,我们使用了下截断,将答案开始位置在480长度之后的,进行根据答案开始结束位置前后取150长度作为新的文章context,这样保证了文本长度基本在512之内,扩充了正样本量。仅通过这两个对数据集的修正,我们ans_f1就提高了1个多点,确实证明了正确数据的重要性。预训练模型方面的尝试:去年做法研杯的时候,当时预训练模型只有中文版的BERT_base和ERNIE 1.0,短短一年时间,NLP预训练模型五花八门,从理解到生成都发布了很多优秀的预训练模型。因此,除了RoBERTa模型之外,我们还尝试了NEZHA和ELECTRA,但是效果都没有RoBERTa好,差距约2-3个点。通过阅读ACL 2020最佳论文提名奖《Don't Stop Pretraining: Adapt Language Models to Domains and Tasks》,我们也受到启发,继续对下游任务进行预训练,使用的18年的法研杯数据,约3.5G,继续进行MLM任务的预训练,跑了20W步,然后进行测试,发现也没效果,23333....,也尝试了FGM等对抗训练方式,也没有提升。对于阅读任务,除了第一阶段的拼接BERT最后两层句向量,还在后面接了BiAttention,类似BiDAF的query、context双向attention,然后去做答案抽取。当然也做了其他各种操作,答案验证、接BiGRU、接Highway Net等。对于答案类型分类任务,除了在BERT的最后一层sequence_out后面接CapsNet和答案四分类的Attention层进行答案的分类,再结合CLS和sequence_out做了层attention,联合四个logit进行答案四分类,也尝试了DiceLoss这些,但并没有提升。对于线索句子分类任务,先将BERT的sequence_out再次经过SelfAttention,然后使用了线索句子开始和结束的映射,去和输出的所有句子表示做Attention,突出线索句子的表示,最终concat线索句子开始和结束表示,与max、mean方式进行联合分类线索句子。在训练时,非线索句子数量一般远大于线索句子,由于是二分类,使用的是BCE损失,我们也设置了pos_weight,让正样本权重提高一些。第二阶段用以上方式,我们最好的单模ansf1有83.46,support_f1有78.23,离比赛第二阶段结束还有一周多时,单模取得了线上第四的成绩。最终的模型集成就是不同的下游模型集成了,以及不同的随机种子,然后选取加权权重这样的常规集成方式。总结&TO DO1.首先感谢主办方举办的第二届法研杯机器阅读理解比赛,赛题也更加有趣和挑战性,期待明年阅读任务和数据格式会是什么样子。2.其实HotpotQA排行榜上面前排很多模型都是基于图网络的,用图网络做线索句子识别效果会更好,但也由于我们对图网络了解不够,所以没有采用这样的方法,图网络技能以后还是必须得点上。3.这次比赛数据质量很重要,阅读理解答案位置的正确标定,真实的线索句子都会带来不小的提升,所以不论竞赛还是工程项目,在数据上做的要足够细致。4.通过分析bad case,发现模型对答案文本靠后的答案有的识别不出来,以及如果原文中多次出现了答案文本,比如多次出现“原告”,也抽取不出来,所以可以对这些bad case再做进一步的优化。参考文献[1] 法研杯2020官方github[2] RoBERTa: A Robustly Optimized BERT Pretraining Approach[3] ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS[4] NEZHA: Neural Contextualized Representation for Chinese Language Understanding[5] Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks