2019法研杯比赛--阅读理解任务第4名团队参赛总结
作者:虹猫少侠
本文已获授权,原文链接,可点击文末"阅读原文"直达:
https://zhuanlan.zhihu.com/p/76377422
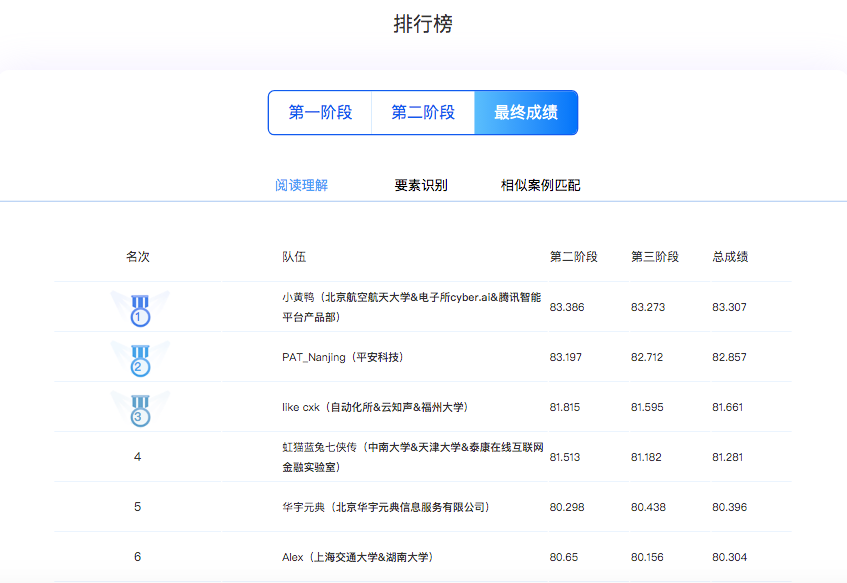
2019法研杯阅读理解比赛也接近尾声了,我们团队在第二阶段获得了第5名的成绩,作为一名鶸,能取得这样的成绩很满足了,首先感谢队友@悟空的帮助,接下来是我对这次比赛的总结,希望和大家相互学习,多交流。
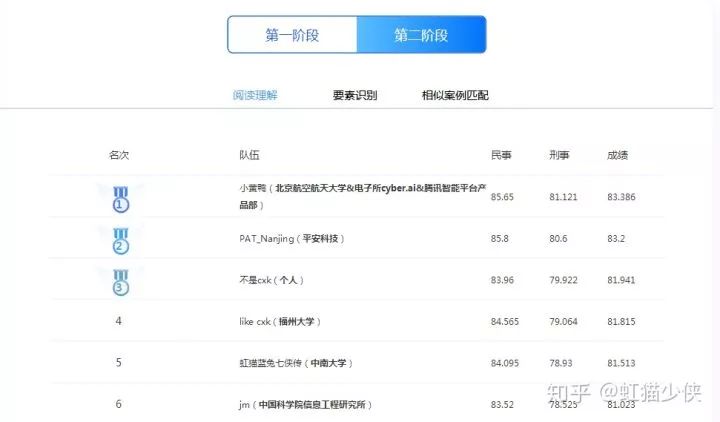
法研杯今年举行了三个任务的比赛:阅读理解、要素识别、相似案例匹配。我们团队选择参加了阅读理解的比赛。
稍微简单介绍下机器阅读理解:和咱们从小到大做的语文、英语阅读理解题目很相似,很通俗的来说,就是给定一篇文章C,和相关的问题Q,让机器阅读推理,然后得出答案A。当然啦,机器阅读理解从2015年快速发展到现在,并不是为了让机器去帮助学生们完成考试阅读理解题目,23333,而是主要为了让机器更好地“理解”文本,为了聊天机器人,搜索等等应用服务。
数据介绍
本任务技术评测使用的数据集由科大讯飞提供,数据主要来源于裁判文书网公开的裁判文书,其中包含刑事和民事一审裁判文书。此次阅读理解任务属于篇章片段抽取型(Span-Extraction Machine Reading Comprehension)。
训练集约包含4万个问题,开发集和测试集各约5000个问题。
对于开发集和测试集,每个问题包含3个人工标注参考答案。
鉴于民事和刑事裁判文书在事实描述部分差异性较大,相应的问题类型也不尽相同,为了能同时兼顾这两种裁判文书,从而覆盖大多数裁判文书,本次比赛会设置民事和刑事两类测试集。
数据集详细介绍可以参见链接
此次数据集的格式和SQuAD 2.0数据集格式一样,同样存在不可回答的问题,即问题的答案在文章中找不到的情况,也增加了答案为YES/NO的问题。
评价方式
本任务采用与CoQA比赛一致的宏平均(macro-average F1)进行评估。
对于每个问题,需要与N个标准回答计算得到N个F1,并取最大值作为其F1值。
然而在评估人类表现(Human Performance)的时候,每个标准回答需要与N-1个其它标准回答计算F1值。
为了更公平地对比指标,需要把N个标准回答按照N-1一组的方式分成N组,最终每个问题的F1值为这N组F1的平均值。
整个数据集的F1值为所有数据F1的平均值。
更详细的评价方法详见链接
此次比赛主要分为三个阶段,第一阶段:报名,发放samll数据集,编写、测试模型,结果不计入最终成绩;第二阶段:发放big数据集,结果将计入最终成绩;第三阶段:选手在第二阶段提交的模型中选择三个模型作为第三阶段封闭测试的模型。
挑战赛的最终成绩计算方式:最终成绩 = 第二阶段的成绩 * 0.3 + 第三阶段的成绩 * 0.7
顺便提一句:此次比赛的模型和测试代码是要提交的,以供主办方在线运行并得出结果~,确实是学习SQuAD ?!
第一阶段
拿到数据之后我们先进行了EDA,对数据基本信息进行分析,分别统计了民事数据和刑事数据问题、文章、答案的长度;答案开始和结束的位置等等信息。并发现民事文章的95%分位数长度986.05,刑事文章的95%分位数长度952.0,看来属于长文本的阅读理解,这一点也和SQuAD文章长度较短(大多300+)不同。
我们也发现,数据集的部分答案存在一些”缺陷“?部分答案开始有标点符号,。等,导致一开始我们对预测出来的答案进行首尾标点的删除操作,后来完整保留下来所有信息,分数居然提升了1个点左右,噗~~~
我们的模型主要基于BERT进行修改用于此次比赛,由于有四种类型的答案:可回答答案、YES答案、NO答案、不可回答答案;我们借鉴circlePi大佬的思路,直接使用BERT+答案四分类进行模型的改进,最初使用了Google公开的中文版BERT预训练模型进行训练。
我们一开始的定的大思路是BERT+传统阅读理解模型(BIDAF、QANet等)来做,比赛刚开始基本也是各种小tricks试了一遍:
BERT+Dropout+softmax;
解冻BERT的10、11层;
取出BERT的1,3,9层;
BERT多语言版本;
加入wiq(文章中的词是否在问题中出现)特征;
使用百度的ERNIE进行训练;
后来ymcui大佬公布了Chinese-BERT-wwm,我们也进行了尝试;
简单的DA:数据增强;
必不可少的调参...
第一阶段做的工作不是很多,主要是熟悉了BERT的使用。
第二阶段
此阶段也是我们踩坑比较多的阶段。
从第一阶段各种尝试选出来的BERT+Dropout+softmax这种方式效果最好,然后开始了第二阶段的踩坑,我们没有将民事案件数据与刑事案件数据分开进行单独训练,正如前文所说,我们使用BERT+传统阅读理解模型(BIDAF、QANet等)作为主要思路。
首先使用了BERT embedding之后接BIDAF的方法,效果居然比仅使用BERT低了5个点左右,有点出乎意料,但是可能是由于使用了Pointer Network进行答案抽取,线上的刑事案件和民事案件的分数很接近,比单纯BERT直接训练民事案件数据与刑事案件数据造成的两者得分相差5个点左右还是有一点启发。
接BIDAF方案告破后,我们开始尝试接QANet,emmm,效果也不好,还是比单纯用BERT的成绩差了不少,深刻体会到了“一顿操作猛如虎,一看线上0.5”的悲惨遭遇。赛中,清华大学也发布了基于法律文书预训练的BERT模型,我们试了下,效果没有提升。
接下来的一段时间,我们也换了方向,既然接传统模型效果不好,我们开始着手去改进不可回答的问题和对问题进行4分类。
我们最终使用两层线性层去判断问题是否可回答,对于4分类问题,既然是分类问题,Kaggle上曾经有不少文本分类的经验可以借鉴,我们使用了TextCNN和CapsuleNet+Attention两种网络进行4分类,此两种网络的输入均为BERT embedding。改进了分类问题后,线上成绩也提高了,BERT+CapsuleNet_Attention单模成绩到了79.8,也是我们试过的最好单模成绩。
第二阶段主要的工作:
1.阅读理解模型部分:
BERT+BIDAF;
BERT+QANet;
BERT+BiLSTM;
BERT_Law;
尝试使用DCMN的思路对问题和文章分别使用BERT进行编码;
2.分类模型部分:
BERT+NoAnswer判断;
BERT+TextCNN;
BERT+CapsuleNet_Attention;
做完这些处理,最后剩余的时间也不多了,我们使用了4个模型进行融合:2个不同种子的BERT+CapsuleNet_Attention,1个BERT+TextCNN,1个BERT+NoAnswer判断。使用Blending思路,对预测的logits进行权重相加,使用的权重方案有5 2 2 1和4 4 1 1两种系数,最终0.4 * BERT_CapsuleNet_Attention + 0.4 * BERT_NoAnswer + 0.1 * BERT_TextCNN + 0.1 * BERT+CapsuleNet_Attention 线上成绩最高,为81.513。
总结&TO DO
1.首先感谢主办方举办的这次中文阅读理解比赛,中文阅读理解现有的数据集也不多,各方面发展也不太完善,很感谢主办方。
2.深深认识到了自己的不足,数据预处理方面我们做的还是比较少,这块应该有更大的挖掘空间。仔细分析模型后,发现每一层都是很有道理的,平时看源码要体会到作者设计这一层的原因,更深入地去理解。
3.至于BERT后面接其他阅读理解模型为什么效果不好的原因,我们现在也不太清楚,恳请了解的大佬指点迷津。至于SQuAD 2.0 前段时间的SOTA模型 BERT+AOA+DAE,我们也没来得及去尝试。
参考文献
[1]法研杯2019官方github
[2]QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension
[3]Bidirectional Attention Flow for Machine Comprehension
[4]BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[5]ymcui/Chinese-BERT-wwm
[6]PaddlePaddle/ERNIE
[7]thunlp/OpenCLaP
[8]circlePi/2019Cail-A-Bert-Joint-Baseline-for-Machine-Comprehension




