DuReader:真实场景中的中文阅读理解数据集

论文:https://arxiv.org/pdf/1711.05073.pdf
代码:https://github.com/baidu/DuReader
数据:http://ai.baidu.com/broad/introduction?dataset=dureader&task=Main
简介
本文面向真实搜索场景的机器阅读问题,构造了一个大规模、开放领域的机器阅读数据集 DuReader。区别于之前的数据集,DuReader有以下几个特点:(1)问题来自于真实搜索场景,答案是用户生成的;(2)有丰富的问题类别;(3)为每个问题提供多个答案。第一版DuReader数据包括200k问题,1000k文档和420k答案,是目前为止最大的中文机器阅读数据。同时本文使用match-LSTM和BiDAF模型来进一步测试和分析数据的特性,实验表明DuReader是一个非常具有挑战性的数据指的进一步的研究。是一个非常具有挑战性的数据指的进一步的研究。是一个非常具有挑战性的数据指的进一步的研究。
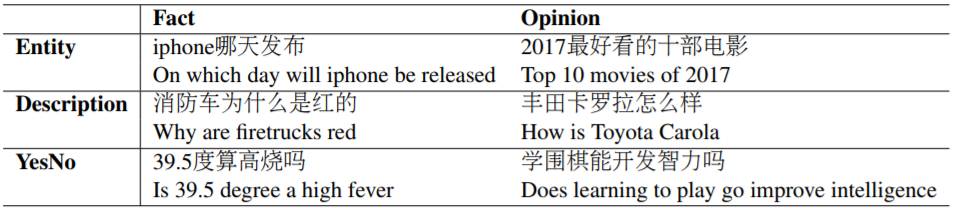
搜索中问题类型分析
从百度某天的搜索日志里,取样出1000个问题进行分析。从两个视角对问题进行标注,(1)答案类别,包括Entity,Description和YesNo。Entity问题的答案可以是单个实体或者实体列表;Description问题的答案一般为多个句子的摘要,这类问题包括how/why类型也包括比较两个对象的优缺点;YesNo问题的答案一般为肯定或者否定的回答。(2)答案的主观特性,包括Fact和Opinion。问题类别举例如下表,从百度某天的搜索日志里,取样出1000个问题进行分析。从两个视角对问题进行标注,(1)答案类别,包括Entity,Description和YesNo。Entity问题的答案可以是单个实体或者实体列表;Description问题的答案一般为多个句子的摘要,这类问题包括how/why类型也包括比较两个对象的优缺点;YesNo问题的答案一般为肯定或者否定的回答。(2)答案的主观特性,包括Fact和Opinion。问题类别举例如下表,
数据的收集和标注
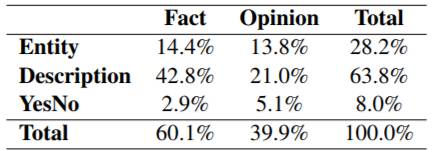
为了收集问题,首先随机地从百度搜索引擎选择高频的query logs,通过构造一个二分类器将问题选择出来,最后人工进行正确性检验得到200K问题。 本文使用了两个数据源来收集问题相关文档,分别是Baidu Zhidao和Baidu 搜索引擎。将问题进行检索,反馈top-5的相关文档作为结果。在问题类别标注中,标注者首先要求给问题进行Entity,Description和YesNo类别的标注,接着要求标注问题是Fact还是Opinion,问题的类别分布如下
对于答案的标注,本文使用crowdsourcing 的方法基于相关文档来生成答案。如果存在多个答案,标注要求将写下所有的答案。对于YesNo的问题,答案包括了opinion的类别(Yes,No 或者Depend)同时含有支持此观点的句子。
数据的难点:答案是生成的,与文档的匹配度不高。同时问题类别本身具有挑战性。
实验
本文实验分析目前机器理解中的两个典型模型match-LSTM和BiDAF在数据中的表现,来进一步分析数据的特性,衡量指标为BLUE和Rouge实验结果如下:

实验的基准方法直接使用Recall最高的段落作为答案。实验结果表明,现有的机器阅读模型相对比基准实验有了很高的提升,但是相比人类的水准依然差距很大。模型在Zhidao上的表现要好于Search,这说明了基于互联网开放领域的问答是一个难度更大的场景。


