法研杯cail2019阅读理解比赛记录(第5名团队分享)
作者:陈猛(华宇元典算法工程师)
知乎专栏:Talk About NLP
https://zhuanlan.zhihu.com/TalkAboutNLP
研究方向:自然语言处理
前言
这篇文章主要是记录一下我这次参加法研杯阅读理解比赛的一个过程,因为是第一次参加比赛,所以觉得挺有新鲜感,并且也付出了不少努力,现在还没有出最终的成绩,不过无论最终成绩怎么样,自己从中学到了不少东西,想记录下来跟大家分享一下。我会按照我做这个比赛的思路来写,文章可能会像流水账一样,大家多包涵。
比赛介绍
简单介绍一下这个比赛吧,法研杯是从去年开始的关于司法人工智能的一个比赛,主要是用自然语言处理的技术去做一些法律相关的任务,今年是第二年,今年有三个比赛:阅读理解,法律要素抽取,相似案例匹配,我参加的是阅读理解的任务。更多比赛的信息可以查看官方github去了解。比赛分为三个阶段,第一阶段相当于初赛,只要超过官方提供的baseline就可以进入到第二阶段,第二阶段会发放大数据集,第三阶段是封闭测试,最终成绩是第二阶段成绩0.3+第三阶段成绩0.7。
第一阶段的时候我没怎么努力就冲到了第二名,当时觉得这个比赛真的挺简单,后来到了第二阶段才发现自己是真太年轻,好多大佬在第一阶段过了baseline就不玩了,等第二阶段开始大佬一点面子没给我留,直接把我打到十几二十名。
第一阶段
因为之前对阅读理解这个任务只是有一点了解,看过比较出名的BIDAF,但是BERT出来后SQUAD就被BERT全面占领了,所以我也不用纠结直接用BERT就好了。好在这次法研杯的数据格式跟SQUAD2.0的一样,只是增加了YESNO类型的问题,稍微修改一下run_squad.py文件就能直接出结果。
拿到数据之后肯定是先做数据分析,观察了几个指标:刑事民事每类的数量,案由的种类,不能回答的问题个数,YESNO类型问题个数及YES和NO分别的个数,原文长度,答案长度,问题长度等,根据这些分析设置训练的超参数,后来通过聚类分析了这些问题大概都是什么问题类型,得出了结论就是问题类型比较复杂,并且分布不均,后边可以通过对一些问题做一些特殊处理。当然还有一个目的就是想通过案由的种类和问题的类型去找一些相关的法律文书在去预训练模型,这是我在第二阶段做的工作。
在预训练模型方面,因为我们是法律公司,所以当BERT出来之后我就用200多万条刑事民事的数据预训练了一个模型,这次正好直接派上用途。
关于YESNO类型的问题,我是使用的textCNN分类模型,尝试了几种方式:将问题进行分类,将原文进行分类,将原文+问题进行分类,最终的出来的结论就是使用问题分类效果比其他两种稍好一点。
通过上述几步,调整了一些超参数,最终拿到了在第一阶段第二名的好成绩😂(感谢大佬的不杀之恩)
第二阶段
这个阶段才算是比赛真正的开始,我在这个阶段也做了很多的尝试,我会从下面几个方面进行说明。
一、数据分析
这部分跟第一阶段差不多,也是分析上述的一些指标,然后通过在训练数据中出现的案由,找了一些相同案由的文书进行预训练。还有发现了训练数据中有的答案是错误,通过人工去修改了一部分错误,或者删掉相关问题。
数据增强,使用哈工大的同义词词林,将原文中非答案部分的词替换成等长的同义词,替换原文的20%,这样使数据量增加一倍,也尝试了只替换数据量的一半。还尝试了调用谷歌翻译的接口,将中文翻译成英文,然后再翻译回中文,相当于也是替换一部分同义词。经过试验证明,这样做数据增强效果并不好,F1值没有增加反而降低了。
二、预训练模型
1. 通过比赛数据进行预训练。
之前看过一篇文章,讲的就是在使用BERT做fine tune之前,尽量使用跟fine tune分布相同的数据去pre train模型。所以我将比赛数据作为训练语料再次对之前的模型进行预训练,并且我做了一个实验,就是在使用比赛数据训练4个epoch的时候在阅读理解中得出的F1值最高。
2. 通过相同案由的法律文书进行预训练,再通过比赛数据进行预训练。
通过数据分析得出的结论,我使用相同案由的文书对之前预训练的模型继续进行预训练,这次预训练的目的是使预训练模型尽可能多学到比赛中出现的案由的数据上下文的关系,之后再次使用比赛数据进行预训练,这次预训练的目的是使预训练模型学到比赛数据的上下文之间的关系。
3. 使用哈工大开源基于全词覆盖(Whole Word Masking)的中文BERT预训练模型
目前google只开源了wwm的英文BERT预训练模型,在比赛过程中,哈工大开源了中文的模型,号称比之前google开源的中文预训练模型在阅读理解中有提高,这种好东西怎么能错过呢,也是赶紧下下来试了一下。在哈工大开源的模型的基础上,我使用的是清华的分词器(thulac),预训练数据就是比赛的数据,具体训练方法在BERT的github上也有说明,我就不细说了。但是让人失望的是使用经过我的预训练,在阅读理解中的F1值并没有之前高,不知道是我训练的有问题还是使用的问题,没有时间去纠结这些问题了,反正在论文中提高的也不是很多,我就放弃了这种方法。
4. 清华开源的基于全量法律文书预训练的模型
因为我们已经有通过部分法律文书预训练的模型了,所以感觉清华开源的这个模型可能对我提升不会很大,而且他们开源的是Pytorch版本的,而我使用的是TensorFlow,我就把测试他们模型的任务让组里的同学帮忙做了,实验证明效果没有我自己预训练的模型好。
5. 结论
在对比上述预训练模型性能时发现,方法2训练一个epoch的效果只比方法1的效果稍稍好一点,如果方法2的预训练训练轮数增加的话,反而会影响最终的F1值,所以之后使用的预训练的模型就是使用方法2只训练一个epoch。
三、模型修改
1. YESNO问题类型的处理方式
在第一阶段使用的是分类的方法,我后来考虑同样的问题可能在不同原文中可能是不同的回答,所以我就把YESNO作为原文进行训练。具体做法就是在原文后边拼接YESNO字符串,然后将之前的答案索引修改为YESNO对应的索引。这样在训练过程中就可以学到答案跟原文之间的关系,而不像之前只关注问题直接得出答案,实验证明这种方法确实能提高成绩,大概提高了3个百分点。
2. 不能回答的问题的处理方式
在BERT的源码中,对于不能回答的问题有一套处理方式,就是根据预测结果得出的nbest和答案为空的概率进行对比,如果答案为空的概率最高就把空作为答案。我使用与处理YESNO问题的方式去试了一下,就是将NULL拼接到原文后,将对应的答案索引改为NULL的索引,实验效果证明能提升, 但是只能提升百分之零点几,anyway,有点提升就用起来吧。
3. 参考哈工大在cmrc2018数据集修改BERT的代码
这种方式也是我在哈工大wwm的讨论区中看到的,主要的修改主要是添加自定义分词器,针对中文进行了一些优化,然后再InputFeature中添加了input_span_mask,然后在计算start_logits和end_logits时去使用,说实话我不太明白他的目的是什么,但是这种方式确实有点提升,于是就用上了。
四、错误分析
这一部分也是到比赛后期才去做的工作,其实应该在每个模型训练完都去分析错误,我也是犯懒,只想着怎么去修改模型了就把这块工作拖到了最后。根据我本地的测试和观察在测试集输出的nbest,观察了到几个问题。
有的预测答案只有一个字。针对这种答案,我使用了一种很暴力的方式,就是如果预测答案是一个字,那么就遍历nbest,直到拿出不是一个字的答案。当然这种方法把原本答案就是一个字的正确答案干掉了,但是通过数据分析看出,只有一个字的答案出现的概率比较低,所以就选取了这种一棒子打死的方法,实验证明能提升不少(有时候暴力的方法真好用)。
有的预测答案开头是标点符号。在正常的回答中答案的开头不可能是标点符号,于是我就把开头的标点符号直接干掉了。
五、超参调整
这部分做的工作比较简单,但是做起来比较烦人,因为需要跑太多模型进行对比了,所以还是单独拿出来说一下,也对得起我做的训练记录。在数据分析的时候已经确定了大部分参数,现在需要去调整的基本只剩下学习率和训练的epoch。这就需要对比不同的学习率在不同的训练步数下的得分。我试了2e-5、3e-5、4e-5、5e-5这几种学习率,训练的epoch从5一直到10,甚至有的到了13。最终的出来的结论就是在4e-5的学习率下训练9个epoch得分是最高的。虽然跟其他的差距不太大,但是比赛中百分之0.1可能就会差出一名,所以这部分工作还是挺有意义的。
第三阶段
这个阶段就是选择自己第二阶段提交的3个模型,当然3个模型最好不太一样,因为从第一阶段到第二阶段来看,同样的模型在第一阶段能得很高的得分,到第二阶段得分就比较低了,所以不同阶段的数据分布是不一样的,尽量让自己模型能适应不同的数据分布。我这边就选择之前训练的得分比较高的3个模型吧,拿名次是不可能的了。
总结
1.算是真真正正做了一次阅读理解任务,对这个任务有了更深入的理解,以后在工作中遇到这种任务,能较快上手,当然工作中做阅读理解需要根据数据集以及具体应用场景去调整,而不像是比赛这样只追求F1值。
2.第一次参加这种技术比赛,感觉挺有意思,也认识到了自己很多不足,比如在比赛中时间分配不合理,把调整模型的时间压缩的比较紧,后来错误分析时间也比较少。还有自己的编码能力和知识面的宽度和深度都不足,不能较快将想法落实到代码上,针对遇到的问题容易进死胡同,没有比较灵活的方式去解决,这里就要感谢一下组里的小伙伴,在我遇到问题的时候能帮我出出主意和我讨论让我有了解决问题的灵感。
3.深感科研工作者的不易,虽然这个比赛算不上什么科研,但是在我调参的过程中,需要记录各种训练数据以及分析原因,想到做科研的大佬在调参过程中肯定比我做的复杂,得记录各种训练数据,以及分析产生各种结果的原因等等,当然这还只是调参,还有设计模型的想法和深入了解业内的各种算法和原理以及快速实现代码跑起来,想想就觉得搞科研真的不容易,在这里送上最大的respect。
2019年8月9日更新。
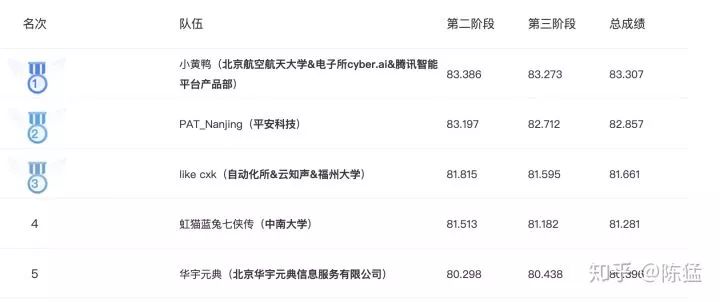
最终成绩是第五名,三等奖吧,可能之前排在我之前的大佬都是同一拨人吧,他们把账号合并了我的排名就提升了,并且还有的第二阶段排名比我靠前的大佬由于第三阶段封闭测试没有我的模型泛化性好,在第三阶段也就排名稍稍靠后了。突然被通知得奖了这种感觉还是很爽的,哈哈哈。
参考文献
法研杯2019官方github
Seo M, Kembhavi A, Farhadi A, et al. Bidirectional attention flow for machine comprehension[J]. arXiv preprint arXiv:1611.01603, 2016.
Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
BERT
Cui Y, Che W, Liu T, et al. Pre-Training with Whole Word Masking for Chinese BERT[J]. arXiv preprint arXiv:1906.08101, 2019.
thulac
CMRC2018-DRCD-BERT
相关文章:
本文由作者授权AINLP原创首发于公众号平台,点击'阅读原文'直达原文链接,欢迎投稿,AI、NLP均可。





