业界 | 百度提出机器阅读理解技术V-NET,登顶MS MARCO数据集榜单
机器之心发布
作者:吴昕
据机器之心了解,百度自然语言处理团队研发的 V-Net 模型以 46.15 的 Rouge-L 得分登上微软的 MS MARCO(Microsoft MAchine Reading COmprehension)机器阅读理解测试排行榜首。
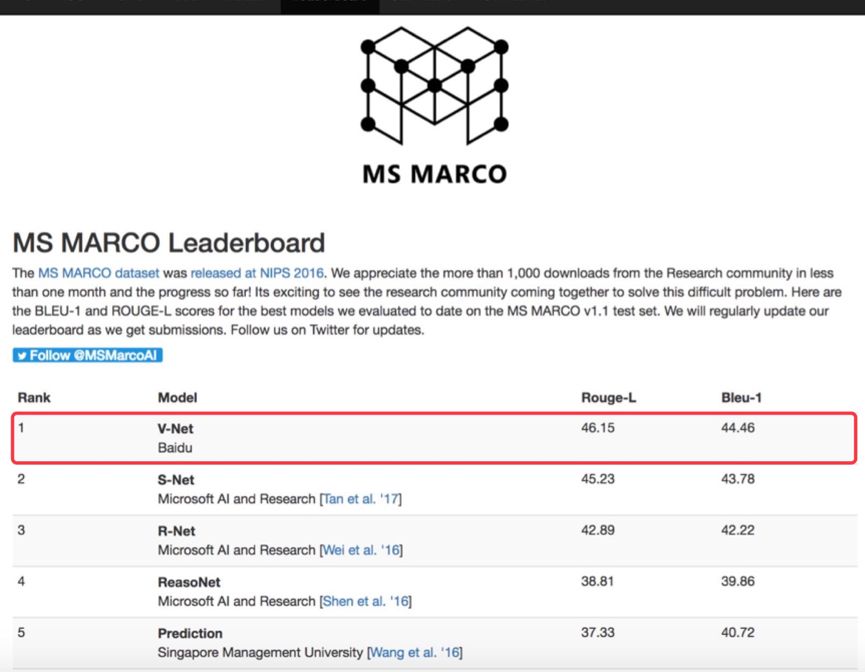
MS MARCO 排行榜

MS MARCO 官方 twitter 发出的祝贺
说到机器阅读理解,业内人士必然会想到今年 1 月份「机器阅读理解打破人类记录」的新闻:微软和阿里巴巴的机器阅读理解系统在最新的 SQuAD 数据集测评结果中取得了并列第一的成绩。其中阿里使用的 SLQA 系统和微软的 R-Net 都是集成模型。
此次百度登顶的数据集是微软基于搜索引擎 BING 构建的大规模英文阅读理解数据集 MS MARCO,包含 10 万个问题和 20 万篇不重复的文档。MARCO 数据集中的问题全部来自于 BING 的搜索日志,根据用户在 BING 中输入的真实问题模拟搜索引擎中的真实应用场景,是该领域最有应用价值的数据集之一。
据介绍,相比 SQuAD,MARCO 的挑战难度更大,因为它需要测试者提交的模型具备理解复杂文档、回答复杂问题的能力。对于每一个问题,MARCO 提供多篇来自搜索结果的网页文档,系统需要通过阅读这些文档来回答用户提出的问题。但是,文档中是否含有答案,以及答案具体在哪一篇文档中,都需要系统自己来判断解决。更有趣的是,有一部分问题无法在文档中直接找到答案,需要阅读理解模型自己做出判断;MARCO 也不限制答案必须是文档中的片段,很多问题的答案必须经过多篇文档综合提炼得到。这对机器阅读理解提出了更高的要求,需要机器具备综合理解多文档信息、聚合生成问题答案的能力。
此次百度 NLP 在 MARCO 提交的是一种全新的模型 V-NET,它使用了一种新的多候选文档联合建模表示方法,通过注意力机制使不同文档产生的答案之间能够产生交换信息,互相印证,从而更好地预测答案。值得注意的是,此次百度只凭借单模型(single model)就拿到了第一名,并没有提交多模型集成(ensemble)结果。
关于百度提出的这一全新的机器阅读理解模型,目前还没有更多的技术细节放出。但据机器之心了解,相关论文会在之后公布。
对于此次登顶 MS MARCO 数据集榜单,百度自然语言处理首席科学家兼百度技术委员会主席吴华表示,「此次在 MARCO 的测试中取得第一,只是百度机器阅读理解技术经历的一次小考。我们希望能够与领域内的其他同行者一起,推进机器阅读理解技术和应用的研究,使 AI 能够理解人类的语言、用自然语言与人类交流,让 AI 更『懂』人类。」

本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



