「中国法研杯」相似案例匹配竞赛结果出炉,冠军方案关键技术解读

作者 | 杨鲤萍
编辑 | 唐里

Kaggle Master 鲍晟霖
KDD 2019 冠军得主易灿
帝国理工博士刘星
杜克大学硕士叶珩
爱丁堡大学硕士林晓彤
一是业务涉及丰富的文本,沉淀了很多文本相关的算法;
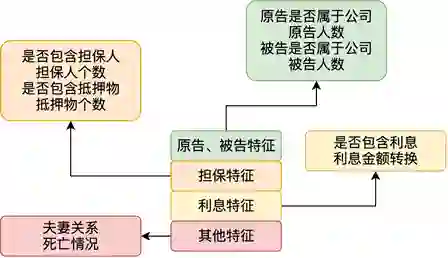
二是团队曾搭建过诈骗案由的知识图谱,这也更好的帮助他们轻车熟路地构建业务抽象要素框架,并与文本模型结合,丰富了模型的学习维度。
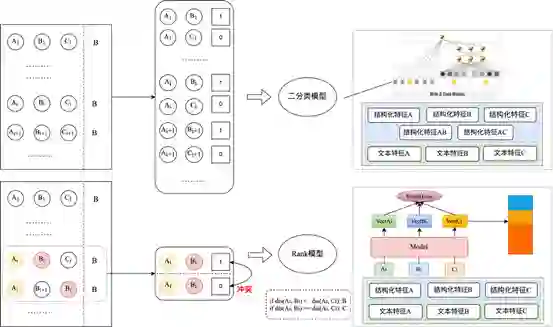
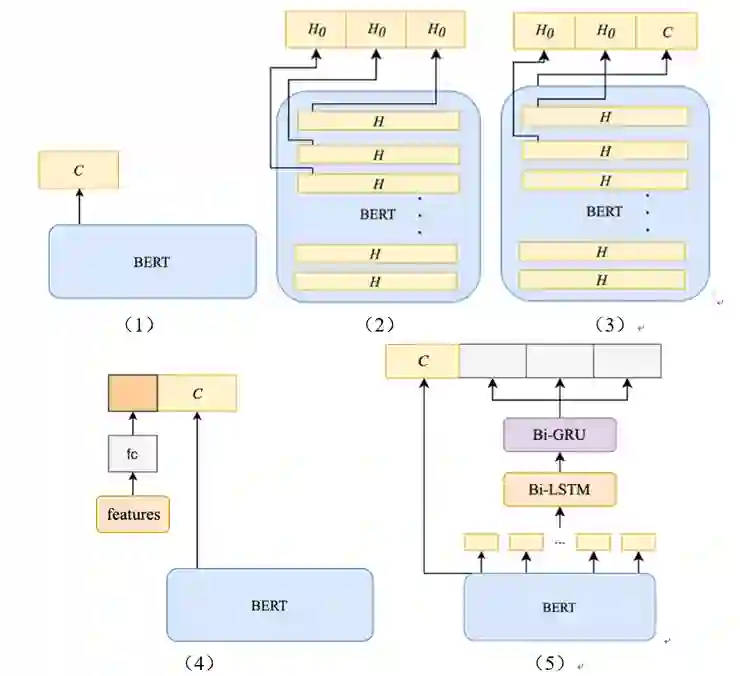
1、模型融合
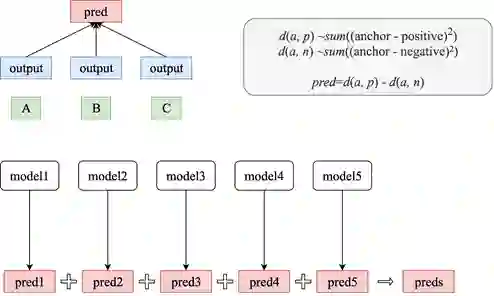
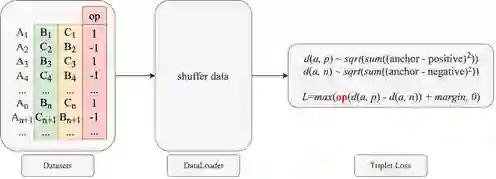
2、Triple Loss 过拟合
Artificial Intelligence for Legal Assistance (AILA) 详情查看: https://sites.google.com/view/fire-2019-aila/ Competition on Legal Information Extraction/Entailment 详情查看: https://sites.ualberta.ca/~rabelo/COLIEE2019/


 点击“
阅读原文
”查看如何在Keras中开发神经机器翻译系统?
点击“
阅读原文
”查看如何在Keras中开发神经机器翻译系统?
登录查看更多
相关内容

专知会员服务
38+阅读 · 2020年3月23日
Arxiv
3+阅读 · 2018年8月2日
Arxiv
5+阅读 · 2018年1月17日




相关VIP内容
专知会员服务
38+阅读 · 2020年3月23日
相关资讯
相关论文
Arxiv
3+阅读 · 2018年8月2日
Arxiv
5+阅读 · 2018年1月17日